
Multi object detection of underground unmanned electric locomotives in coal mines based on SD-YOLOv5s-4L
-
摘要: 为解决煤矿井下无人驾驶电机车由于光照不均、高噪声等复杂环境因素导致的多目标检测精度低及小目标识别困难问题,提出一种基于SD−YOLOv5s−4L的煤矿井下无人驾驶电机车多目标检测模型。在YOLOv5s基础上进行以下改进,构建SD−YOLOv5s−4L网络模型:引入SIoU损失函数来解决真实框与预测框方向不匹配的问题,使得模型可以更好地学习目标的位置信息;在YOLOv5s头部引入解耦头,增强网络模型的特征融合与定位准确性,使得模型可以快速捕捉目标的多尺度特征;引入小目标检测层,将原三尺度检测层增至4层,以增强模型对小目标的特征提取能力和检测精度。在矿井电机车多目标检测数据集上进行实验,结果表明:SD−YOLOv5s−4L网络模型对各类目标的平均精度均值(mAP)为97.9%,对小目标的平均检测精度(AP)为98.9%,较YOLOv5s网络模型分别提升了5.2%与9.8%;与YOLOv7,YOLOv8等其他网络模型相比,SD−YOLOv5s−4L网络模型综合检测性能最佳,可为实现矿井电机车无人驾驶提供技术支撑。Abstract: Due to complex environmental factors such as uneven illumination and high noise, unmanned electric locomotives in coal mines have low accuracy in multi object detection and difficulty in recognizing small objects. In order to solve the above problems, a multi object detection model for underground unmanned electric locomotives in coal mines based on SD-YOLOv5s-4L is proposed. On the basis of YOLOv5s, the following improvements are made to construct the SD-YOLOv5s-4L network model. The model introduces the SIoU loss function to solve the problem of mismatch between the direction of the real box and the predicted box, so that the model can better learn the position information of the object. The model introduces decoupled heads at the head of YOLOv5s to enhance the feature fusion and positioning accuracy of the network model. It enables the model to quickly capture multi-scale features of the object. The model introduces a small object detection layer to increase the original three scale detection layer to four scale. It enhances the model's feature extraction capability and detection precision for small objects. The experiment is conducted on a multi object detection dataset of the mine electric locomotives. The results show the following points. The mean average precision (mAP) of the SD-YOLOv5s-4L network model for various types of objects is 97.9%, and the average precision (AP) for small objects is 98.9%. Compared with the YOLOv5s network model, it improves by 5.2% and 9.8%, respectively. Compared with other network models such as YOLOv7 and YOLOv8, the SD-YOLOv5s-4L network model has the best comprehensive detection performance and can provide technical support for achieving unmanned driving of the mine electric locomotives.
-
0. 引言
煤炭是我国的主体能源[1],在保障能源需求和推动经济增长方面发挥着关键作用。2020年2月25日,国家八部委联合印发《关于加快煤矿智能化发展的指导意见》,对煤矿运输设备无人驾驶、智能感知等提出了更高要求[2-3]。煤矿电机车作为主要的运输装备,承担着煤炭、物料、人员与相关设备的辅助运输任务[4]。由于矿井电机车运输作业场景多样,常运行于高噪声、窄巷道、低光照等恶劣环境[5]中,容易引起驾驶员疲劳驾驶,从而造成电机车脱轨、追尾等事故。因此,研究煤矿无人驾驶电机车的智能化感知技术具有重要意义。
环境感知是无人驾驶技术的重要组成部分,准确的目标检测对提高无人驾驶电机车的安全性和效率至关重要。传统的目标检测方法难以适应煤矿井下的复杂环境,随着深度学习的快速发展,基于深度学习的目标检测算法得到广泛应用[6]。目前以R−CNN[7]、Mask R−CNN[8]、YOLO系列[9]、SSD[10]等为代表的深度学习算法在目标检测中已取得优异表现。李伟山等[11]在Faster R−CNN上构建了一种区域候选网络(Region Proposals Network,RPN)结构,解决了煤矿井下行人检测的多尺度问题。He Deqiang等[12]在Mask R−CNN模型中引入了ResNet[13]骨干特征提取网络,提高了模型的检测精度。郝帅等[14]在YOLOv5网络模型中引入注意力机制,有效解决了复杂环境条件下输送带中非煤异物难以检测的问题。郑玉珩等[15]基于YOLOv5单阶段检测算法,采用BiFPN特征融合结构,解决了遮挡目标的检测问题。杨艺等[16]提出了一种LiYOLO模型,该模型在面对综采工作面动态变化、煤尘干扰等复杂情况下,表现出了良好的鲁棒性。葛淑伟等[17]通过改进SSD算法,提升了模型对锚孔的检测性能。尽管研究者们在目标检测领域取得了一定成就,但针对运行于光照不均、高噪声等复杂环境中的矿井电机车多目标检测精度低的问题有待深入研究。
为解决上述问题,本文提出了一种基于SD−YOLOv5s−4L的煤矿井下无人驾驶电机车多目标检测模型。在数据预处理阶段,采用高斯噪声、运动模糊和随机光照等方式对数据集进行增强处理,以提升数据集多样性和算法鲁棒性。在损失函数方面,用SIoU[18]替换了原有的CIoU[19],使网络可以更好地学习目标的位置信息。在YOLOv5s检测头部引入解耦头[20],缓解分类任务和回归任务之间的冲突,使模型可以快速捕捉目标的多尺度特征;引入小目标检测层,以增强网络对小目标的特征提取能力和检测精度。
1. YOLOv5s模型及其改进策略
1.1 YOLOv5s网络结构
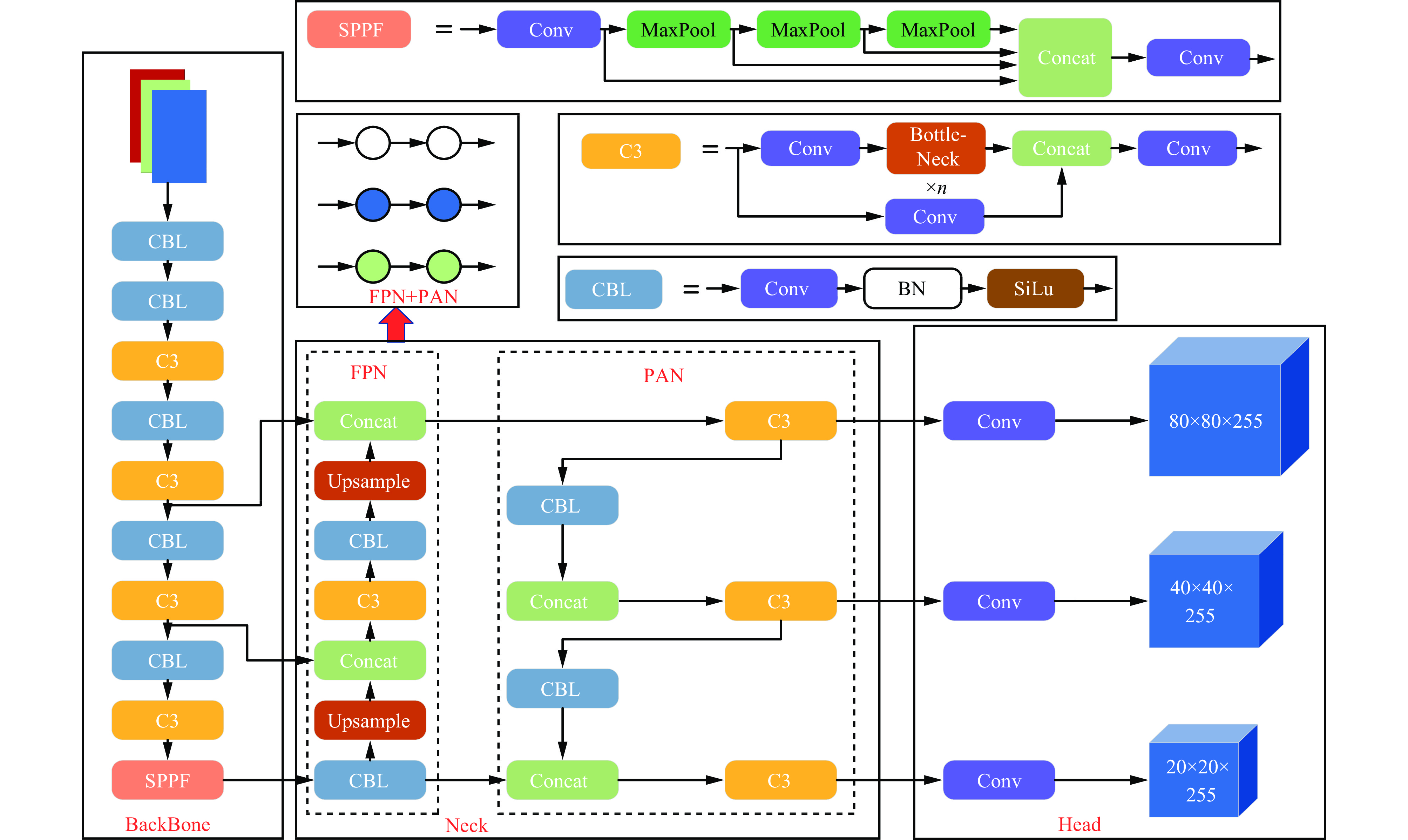
YOLOv5s网络结构主要由骨干网络(Backbone)、颈部段(Neck)及头部端(Head)3个部分组成,如图1所示。Backbone由CBL模块、C3模块和SPPF模块组合而成,负责提取多尺度特征信息。CBL是由1个卷积层(Conv)、1个批标准化层(Batch Normalization,BN)和1个SiLu激活函数组成的卷积块;C3模块包含3个卷积层和多个Bottleneck模块;SPPF模块在空间金字塔池化(Spatial Pyramid Pooling,SPP)基础上,将原结构中3路并行的Maxpool改为串行,使网络模型能够在不影响性能的同时提升计算速率。Neck采用特征金字塔网络(Feature Pyramid Network, FPN)与路径聚合网络(Path Aggregation Network,PAN)结构来融合不同尺寸的特征图,从而获取丰富的特征信息。其中FPN[21]是自顶向下,将高层的语义信息传递到底层;PAN[22]是自底向上,将底层的位置信息传递到高层。Head根据前向传递的特征信息,在图像上生成带有特征的边界框,且边界框上显示有类别名称及检测概率。
1.2 YOLOv5s改进策略
1.2.1 损失函数改进
损失函数用来估量模型的预测值与真实值之间的不一致程度,目标检测的准确性在很大程度上依赖于所使用的损失函数,因此选用适当的损失函数有利于模型检测精度的提升。
在YOLO系列目标检测模型中,损失函数主要由分类损失、置信度损失和定位损失[23]组成。其中,定位损失对于目标检测算法具有重要意义。通过优化定位损失,算法可更准确地确定目标位置和边界框,并且能够在复杂场景中更好地区分目标和背景,从而提高模型的检测精度和抗干扰能力。
目前YOLOv5网络模型采用CIoU作为定位损失函数,CIoU综合考虑了真实框与预测框之间的重叠面积、中心点距离和长宽比,克服了GIoU的退化问题,同时解决了DIoU无法区分中心点重合时交并比一样的情况,但忽略了真实框与预测框之间角度不匹配的问题。当检测目标尺度差异较大时,模型的收敛速度会变慢,从而影响模型的检测精度。因此,本文引入SIoU作为YOLOv5网络的定位损失函数。SIoU计算公式为
$$ S_{\mathrm{IoU}} = 1 - I_{\mathrm{oU}} + \frac{{\varDelta + \varOmega }}{2} $$ (1) $$ \varDelta = \sum_{t = {\mathrm{x,y}}} {(1 - {\exp( - (2 - \varLambda ){\rho _t}}))} $$ (2) $$ \varLambda = 1 - 2 {\sin ^2}\left(\arcsin \left(\frac{{{c_{\mathrm{h}}}}}{\sigma }\right) - \frac{{\text{π}} }{4}\right) $$ (3) $$ \varOmega = {\sum\limits_{r = {\mathrm{w,h}}} {(1 - {\exp({ - {\omega _r}}}))} ^\theta } $$ (4) 式中:IoU为预测框和真实框的交并比;$ \varDelta $为距离损失;$ \varOmega $为形状损失;$ \varLambda $为角度损失;ρt为衡量预测框中心点与真实框中心点之间坐标偏差的归一化指标,t=x表示横坐标,t=y表示纵坐标;$ {c_{\mathrm{h}}} $为真实框与预测框中心点的高度差;$ \sigma $为真实框与预测框中心点的距离;ωr为预测框和真实框之间的偏差,r=w表示宽度偏差,r=h表示高度偏差;$ \theta $为权重系数。
$$ {\rho _{\mathrm{x}}} = {\left[ {\left( {b_{{C_{\mathrm{x}}}}^{{\mathrm{gt}}} - {b_{{C_{\mathrm{x}}}}}} \right)/{C_{\mathrm{w}}}} \right]^2} $$ (5) $$ {\rho _{\mathrm{y}}} = {\left[ {\left( {b_{{C_{\mathrm{y}}}}^{{\mathrm{gt}}} - {b_{{C_{\mathrm{y}}}}}} \right)/{C_{\mathrm{h}}}} \right]^2} $$ (6) $$ {\omega _{\mathrm{w}}} = \left| {w - {w^{{\mathrm{gt}}}}} \right|/\max \left( {w,{w^{{\mathrm{gt}}}}} \right) $$ (7) $$ {\omega _{\mathrm{h}}} = \left| {h - {h^{{\mathrm{gt}}}}} \right|/\max (h,{h^{{\mathrm{gt}}}}) $$ (8) 式中:$ b_{C_{\mathrm{x}}}^{{\mathrm{gt}}},b_{C_{\mathrm{y}}}^{{\mathrm{gt}}} $为真实框中心坐标;$ {b_{C_{\mathrm{x}}}},{b_{C_{\mathrm{y}}}} $为预测框中心坐标;$ {C_{\mathrm{w}}} $为真实框和预测框最小外接矩形的宽;$ {C_{\mathrm{h}}} $为真实框和预测框最小外接矩形的高;$ \left( {w,h} \right) $和$ \left( {{w^{{\mathrm{gt}}}},{h^{{\mathrm{gt}}}}} \right) $分别为真实框和预测框的宽和高。
SIoU在CIoU的基础上引入了角度损失,降低了损失的总自由度,使预测的边界框更加准确地适应目标的形状和方向。
1.2.2 解耦头
在目标检测中,分类任务与回归任务所关注的特征信息不同。分类任务需要确定图像中目标的类别,因此专注于特征图中的突出区域;回归任务则专注于目标的边缘信息,以此来准确预测目标在图像中的位置和尺度。
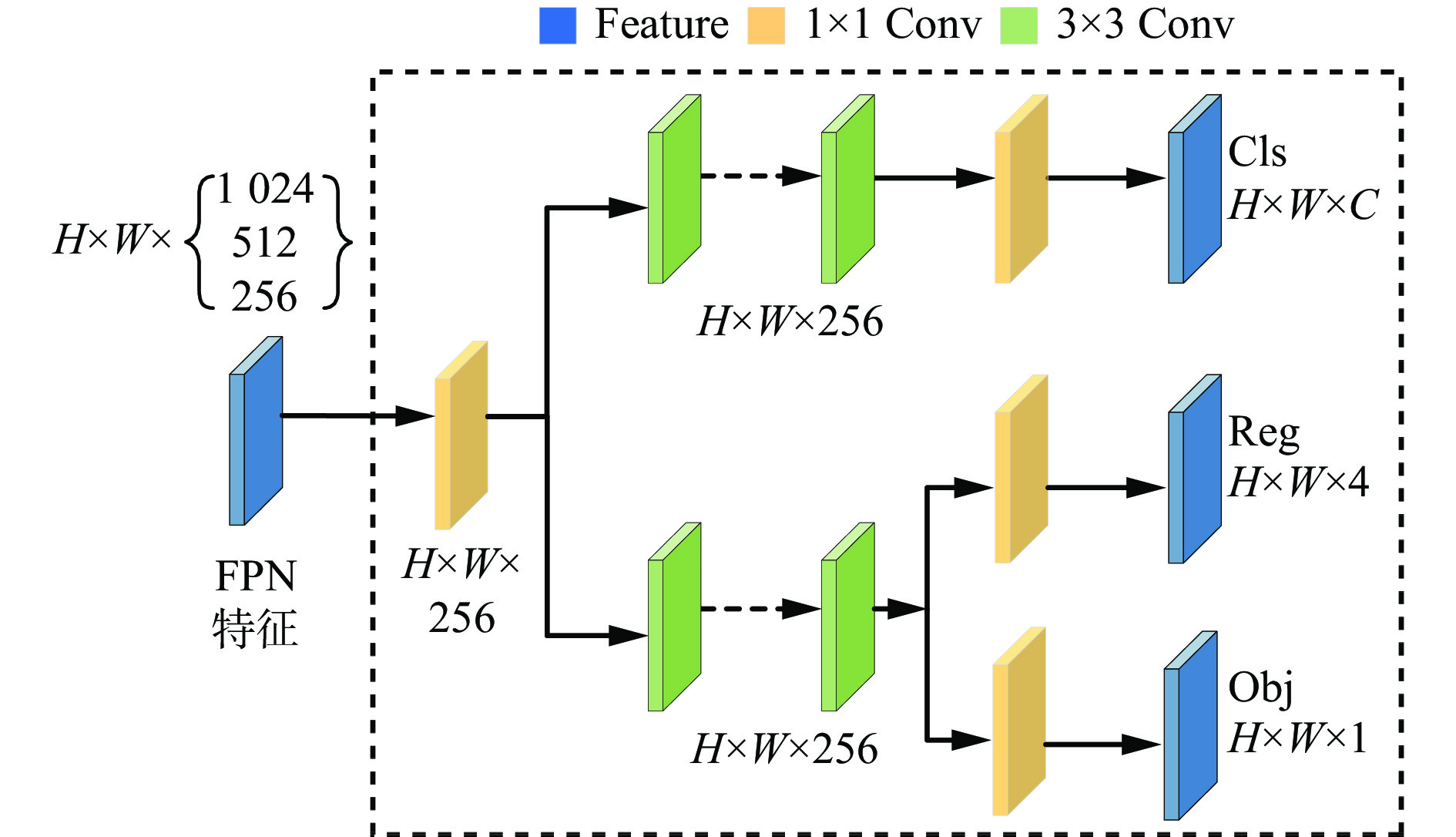
在YOLOv5网络模型中,分类任务和回归任务通过共享的卷积层完成。由于参数共享,分类任务和回归任务无法专注于各自的目标区域,使得2个任务之间相互干扰,导致模型性能降低。为解决上述问题,本文在YOLOv5s头部引入解耦头替换原耦合头,解耦头结构如图2所示,H,W,C分别为图像的高度、宽度和通道数。首先,采用1个1×1卷积对输入的FPN特征进行降维,将特征维数减少到256;然后,经过2个平行的分支,一个用于分类任务,一个用于回归任务,每个分支后面均接有2个3×3卷积;最后,分类分支再经过1个1×1卷积进行分类操作,回归分支中2个平行的定位与置信度分支里各经过1个1×1卷积进行定位和置信度操作。
解耦头通过2个分支分别处理分类任务和回归任务,使得2个任务之间相互独立、互不干扰。这种结构有利于模型快速准确地捕捉目标的多尺度特征,并在不同层级上进行特征融合与重定位,以提升目标检测的定位准确性与适应性。
1.2.3 小目标检测层
YOLOv5s网络模型通过多个下采样层来增强感受野,这导致图像分辨率降低,使得小目标的细节特征在较大感受野的特征图中变得模糊。此外,由于小目标与背景之间的尺度差异较大,模型更易聚焦于特征明显的区域,从而忽略小目标的微弱特征,导致网络模型对小目标的检测效果不佳。
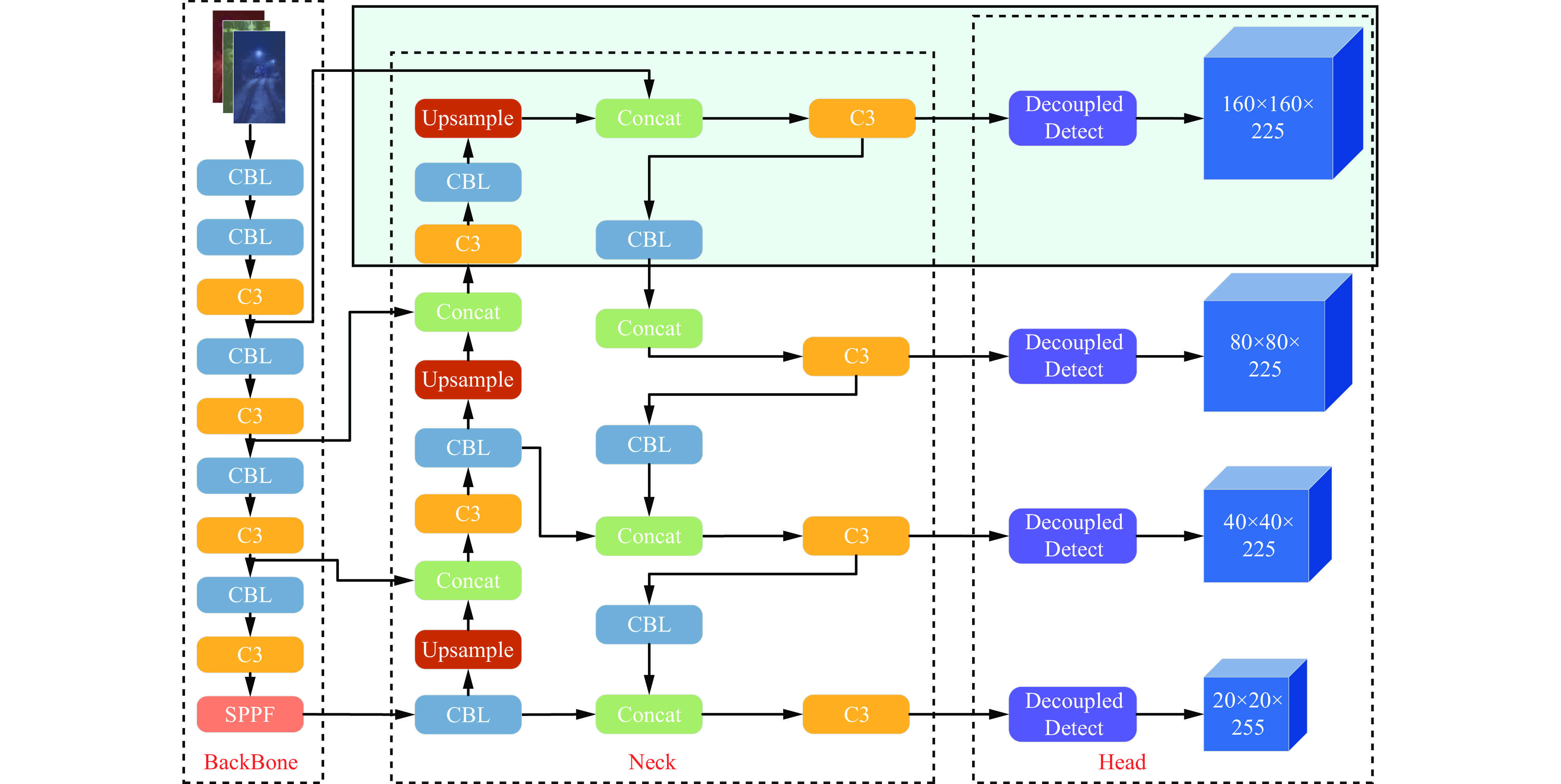
为了提高网络模型对小目标的检测性能,本文在YOLOv5s网络中增加了1层小目标检测层。将原三尺度检测层增至4层,增强了网络模型对小目标的关注度,使得更底层的特征信息得到进一步融合,对小目标检测精度的提升有着积极作用。结合前述改进方式,将改进后的网络模型命名为SD−YOLOv5s−4L,其网络结构如图3所示。
2. 实验与分析
2.1 数据集创建
本文所采用的电机车图像数据采集于淮南矿业(集团)有限责任公司顾桥煤矿、淮北矿业股份有限公司袁店一矿及中煤新集能源股份有限公司新集二矿3个不同矿井中电机车运行的多段运输巷。为进一步提高数据集多样性与检测算法鲁棒性,除YOLOv5s网络模型本身的数据增强方法外,本文还采用高斯噪声、运动模糊及随机光照等方式对数据集进行增强处理。经整理后共得到4 500张图像,包含辅助运输作业过程中低照度、高噪声、人机多目标混杂及运动模糊4种生产环境。部分数据集图像如图4所示。采用标注工具LabelImg对数据集进行标注,标注类别有“person”“stone”“signal light”,分别表示行人、石块和信号灯。最后将标注好的图像按照8∶1∶1比例随机划分为训练集、测试集和验证集。
2.2 实验环境及评价指标
2.2.1 实验环境
本文实验环境为Ubuntu 18.04操作系统下搭建的PyTorch 1.9.0 深度学习框架Python 3.8及CUDA11.1编程软件,具体配置见表1。
表 1 实验环境Table 1. Experimental environment实验环境 参数 操作系统 Ubuntu 18.04 CPU Intel(R) Xeon(R) Platinum 8350C CPU@2.6 GHz GPU RTX 3090(24 GiB) 深度学习框架 PyTorch 1.9.0 编程语言 Python 3.8 CUDA 11.1 为获得最优训练模型,在网络模型训练前,需对模型配置文件中的超参数进行设置,具体见表2。batch-size为一批训练样本的数量,该值根据实验设备性能而定;momentum为动量,表示网络每次迭代更新的变化程度,调整梯度下降达到最优值的速度;decay为权重衰减系数,用来防止模型过拟合;learning rate为初始学习率,用以控制参数的更新速度;epochs为迭代次数。网络模型的优化器为SGD。
表 2 超参数设置Table 2. Hyper-parameter setting参数名称 数值 batch-size 32 momentum 0.937 decay 0.0005 learning rate 0.01 epochs 301 2.2.2 评价指标
在目标检测领域中,常用的评价指标包括准确率P、召回率R、平均精度(Average Precision,AP)、平均精度均值(mean Average Precision,mAP)及调和均值F1。有关评价指标的计算公式为
$$ P = \frac{{T_{\mathrm{P}}}}{{T_{\mathrm{P}} + F_{\mathrm{P}}}} $$ (9) $$ R = \frac{{T_{\mathrm{P}}}}{{T_{\mathrm{P}} + F_{\mathrm{N}}}} $$ (10) $$ m_{\mathrm{AP}} = \frac{{\displaystyle\sum {P} }}{N} $$ (11) $$ {F_1} = 2 \frac{{P R}}{{P + R}} $$ (12) 式中:$ T_{\mathrm{P}} $为正样本被正确识别为正样本的数量;$ F_{\mathrm{P}} $为负样本被错误识别为正样本的数量;$ F_{\mathrm{N}} $为正样本被错误识别为负样本的数量;mAP为mAP的值;$ N $为类别总数。
2.3 实验结果分析
2.3.1 不同网络模型检测效果对比
为了直观说明SD−YOLOv5s−4L网络模型的检测效果,将其与YOLOv5n、YOLOv5m和YOLOv5s网络模型进行对比,检测结果如图5所示。
由图5可看出,在对信号灯和行人的检测中,YOLOv5n、YOLOv5m和YOLOv5s网络模型出现了目标置信度得分低的问题,而SD−YOLOv5s−4L网络模型的目标置信度得分较高;在对小目标(石块)的检测中,YOLOv5n网络模型出现了错检情况,YOLOv5m和YOLOv5s存在漏检现象,而SD−YOLOv5s网络模型能够实现精准检测且检测精度较高。因此,SD−YOLOv5s−4L网络模型更能满足煤矿井下电机车的多目标检测需求。
2.3.2 消融实验
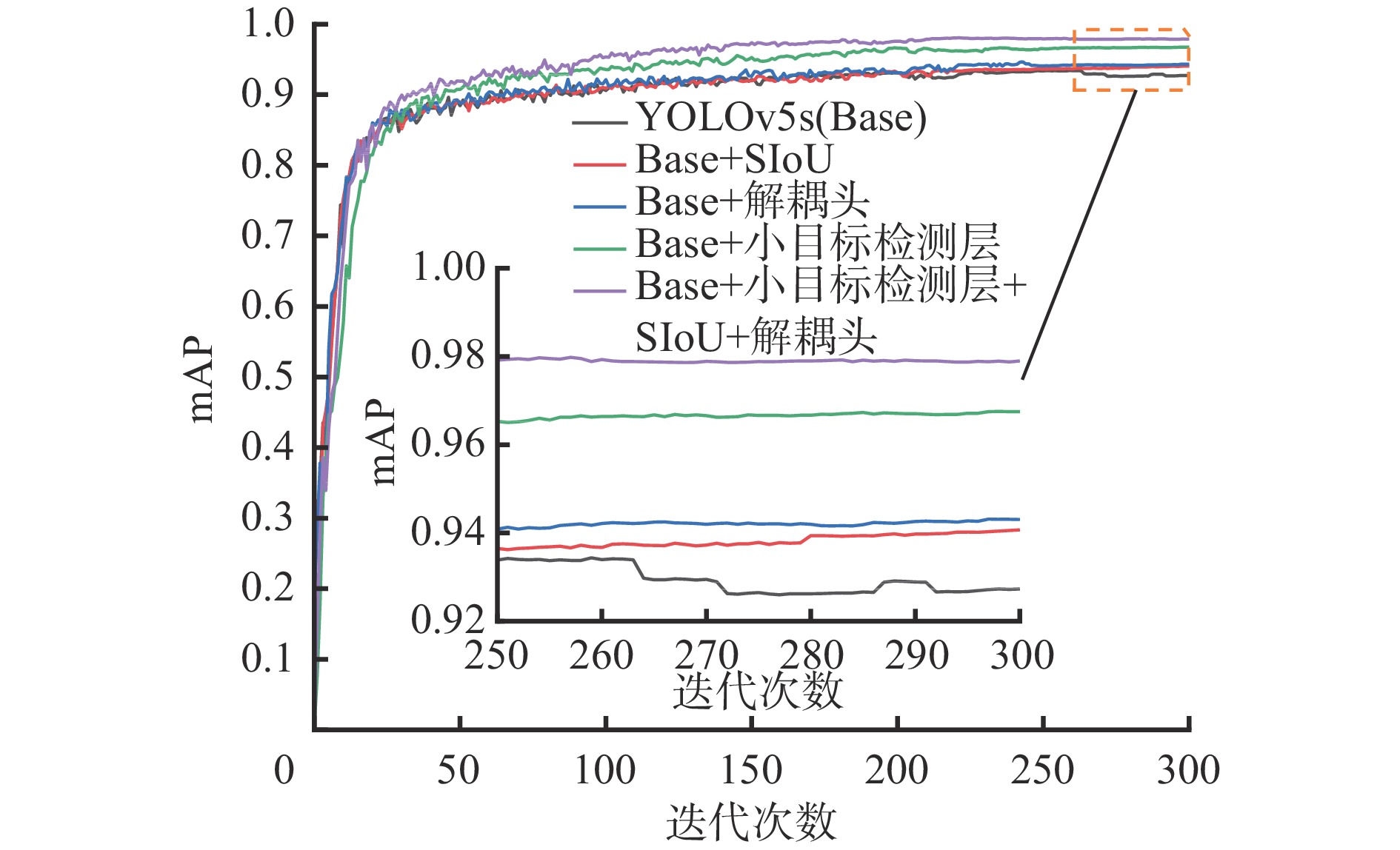
为了验证不同的改进策略对YOLOv5s网络模型的优化作用,设计了5组消融实验,实验结果见表3。
表 3 消融实验结果Table 3. Ablation experiment results实验 网络模型 AP mAP person signal light stone 1 YOLOv5s 0.945 0.945 0.891 0.927 2 YOLOv5s+ SIoU 0.946 0.942 0.931 0.940 3 YOLOv5s+解耦头 0.956 0.950 0.923 0.943 4 YOLOv5s+小目标检测层 0.972 0.959 0.971 0.968 5 YOLOv5s+SIoU+
小目标检测层+解耦头0.980 0.967 0.989 0.979 表3中每组消融实验mAP值的对比如图6所示。实验结果表明:引入SIoU损失函数,mAP为0.940,较YOLOv5s提升了1.3%,说明角度损失的加入降低了损失的总自由度,对模型检测精度的提升有着积极作用;引入解耦头后,mAP提升了1.6%,其中对行人、信号灯和石块分别提升了1.1%、0.5%及3.2%,说明解耦头的引入有利于增强网络模型的检测性能;添加小目标检测层后,mAP提高了4.1%,其中对石块的检测精度为97.1%,提高了8%,有效提升了网络模型对小目标的检测能力;将解耦头、SIoU及小目标检测层全部加入原YOLOv5s网络模型中,mAP为0.979,提升了5.2%,其中行人检测的平均精度提高了3.5%,信号灯检测的平均精度提升了2.2%,石块检测的平均精度提升高达9.8%。实验结果验证了各个改进策略对YOLOv5s网络模型均起到了较好的优化作用,有效解决了多目标检测精度低、小目标检测困难的问题。
2.3.3 对比实验
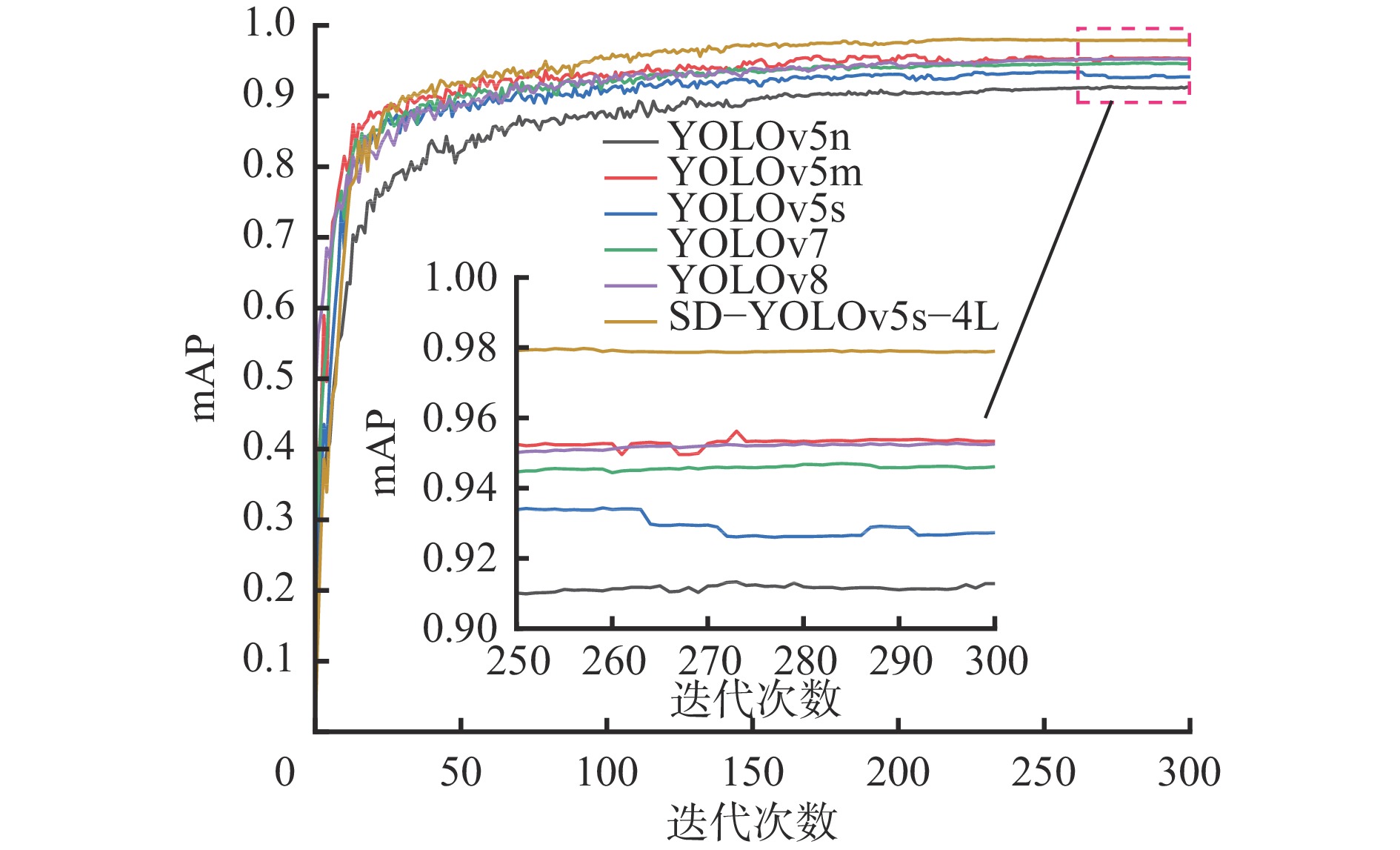
为了进一步验证SD−YOLOv5s−4L网络模型的检测性能,将其与YOLO系列的主流网络模型YOLOv5n,YOLOv5m,YOLOv5s,YOLOv7及YOLOv8进行对比,实验结果见表4。
表 4 对比实验结果Table 4. Comparative experimental results实验 网络模型 AP F1 mAP person signal light stone 1 YOLOv5n 0.900 0.913 0.923 0.89 0.912 2 YOLOv5m 0.965 0.960 0.935 0.93 0.954 3 YOLOv5s 0.945 0.945 0.891 0.91 0.927 4 YOLOv7 0.967 0.950 0.921 0.94 0.946 5 YOLOv8 0.948 0.926 0.985 0.92 0.953 6 SD−YOLOv5s−4L 0.980 0.967 0.989 0.96 0.979 表4中不同网络模型的mAP值对比如图7所示。实验结果表明:SD−YOLOv5s−4L网络模型对多种目标都有较高的检测精度,mAP较YOLOv5n,YOLOv5m,YOLOv5s,YOLOv7,YOLOv8分别提高了6.7%,2.5%,5.2%,3.3%和2.6%。调和均值F1为0.96,较YOLOv5n,YOLOv5m,YOLOv5s,YOLOv7,YOLOv8分别提高了7%,3%,5%,2%和4%,表明SD−YOLOv5s−4L网络模型具有更优异的性能。
3. 结论
1) 为解决真实框与预测框方向不匹配问题,引入损失函数SIoU,以降低损失的总自由度,使网络可以更好地学习目标的位置信息;为了缓解模型回归任务与分类任务之间的冲突,引入解耦头,使模型可以快速捕捉目标的多尺度特征;为解决小目标识别困难的问题,在YOLOv5的基础上增加小目标检测层,提升网络模型对小目标的检测性能。改进后的网络模型SD−YOLOv5s−4L的mAP较原YOLOv5s网络模型提升了5.2%,达97.9%。
2) SD−YOLOv5s−4L网络模型对小目标的检测精度高达98.9%,较YOLOv5s网络模型提升了9.8%,改进后的网络模型大幅提高了对小目标的检测能力,有效解决了小目标识别困难的问题。
3) 将SD−YOLOv5s−4L网络模型与YOLOv5n, YOLOv5m, YOLOv5s,YOLOv7,YOLOv8进行对比,实验结果表明:SD−YOLOv5s−4L网络模型对多种目标的检测精度均为最高且调和均值F1更逼近于1,为实现煤矿井下电机车的无人驾驶提供了技术支撑。
-
表 1 实验环境
Table 1 Experimental environment
实验环境 参数 操作系统 Ubuntu 18.04 CPU Intel(R) Xeon(R) Platinum 8350C CPU@2.6 GHz GPU RTX 3090(24 GiB) 深度学习框架 PyTorch 1.9.0 编程语言 Python 3.8 CUDA 11.1  下载: 导出CSV
下载: 导出CSV
表 2 超参数设置
Table 2 Hyper-parameter setting
参数名称 数值 batch-size 32 momentum 0.937 decay 0.0005 learning rate 0.01 epochs 301
下载: 导出CSV
表 3 消融实验结果
Table 3 Ablation experiment results
实验 网络模型 AP mAP person signal light stone 1 YOLOv5s 0.945 0.945 0.891 0.927 2 YOLOv5s+ SIoU 0.946 0.942 0.931 0.940 3 YOLOv5s+解耦头 0.956 0.950 0.923 0.943 4 YOLOv5s+小目标检测层 0.972 0.959 0.971 0.968 5 YOLOv5s+SIoU+
小目标检测层+解耦头0.980 0.967 0.989 0.979
下载: 导出CSV
表 4 对比实验结果
Table 4 Comparative experimental results
实验 网络模型 AP F1 mAP person signal light stone 1 YOLOv5n 0.900 0.913 0.923 0.89 0.912 2 YOLOv5m 0.965 0.960 0.935 0.93 0.954 3 YOLOv5s 0.945 0.945 0.891 0.91 0.927 4 YOLOv7 0.967 0.950 0.921 0.94 0.946 5 YOLOv8 0.948 0.926 0.985 0.92 0.953 6 SD−YOLOv5s−4L 0.980 0.967 0.989 0.96 0.979
下载: 导出CSV
-
[1] 王国法,赵国瑞,任怀伟. 智慧煤矿与智能化开采关键核心技术分析[J]. 煤炭学报,2019,44(1):34-41. DOI: 10.13225/j.cnki.jccs.2018.5034 WANG Guofa,ZHAO Guorui,REN Huaiwei. Analysis on key technologies of intelligent coal mine and intelligent mining[J]. Journal of China Coal Society,2019,44(1):34-41. DOI: 10.13225/j.cnki.jccs.2018.5034
[2] 孙继平. 煤矿智能化与矿用5G[J]. 工矿自动化,2020,46(8):1-7. SUN Jiping. Coal mine intelligence and mine-used 5G[J]. Industry and Mine Automation,2020,46(8):1-7.
[3] 于骞翔,张元生. 井下电机车轨道障碍物图像处理方法的智能识别技术[J]. 金属矿山,2021(8):150-157. DOI: 10.19614/j.cnki.jsks.202108024 YU Qianxiang,ZHANG Yuansheng. Track obstacle intelligent recognition technology of mine electric locomotive based on image processing[J]. Metal Mine,2021(8):150-157. DOI: 10.19614/j.cnki.jsks.202108024
[4] 韩江洪,卫星,陆阳,等. 煤矿井下机车无人驾驶系统关键技术[J]. 煤炭学报,2020,45(6):2104-2115. HAN Jianghong,WEI Xing,LU Yang,et al. Driverless technology of underground locomotive in coal mine[J]. Journal of China Coal Society,2020,45(6):2104-2115.
[5] 胡青松,孟春蕾,李世银,等. 矿井无人驾驶环境感知技术研究现状及展望[J]. 工矿自动化,2023,49(6):128-140. DOI: 10.13272/j.issn.1671-251x.18115 HU Qingsong,MENG Chunlei,LI Shiyin,et al. Research status and prospects of perception technology for unmanned mining vehicle driving environment[J]. Journal of Mine Automation,2023,49(6):128-140. DOI: 10.13272/j.issn.1671-251x.18115
[6] 李程,车文刚,高盛祥. 一种用于航拍图像的目标检测算法[J]. 山东大学学报(理学版),2023,58(9):59-70. LI Cheng,CHE Wengang,GAO Shengxiang. A object detection algorithm for aerial images[J]. Journal of Shandong University(Natural Science),2023,58(9):59-70.
[7] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition,Columbus,2014:580-587.
[8] HE Kaiming,GKIOXARI G,DOLLAR P,et al. Mask R-CNN[C]. 2017 IEEE International Conference on Computer Vision,Venice,2017:2980-2988.
[9] REDMON J,DIVVALA S,GIRSHICK R,et al. You only look once:unified,real-time object detection[C]. IEEE Conference on Computer Vision and Pattern Recognition,Las Vegas,2016:779-788.
[10] LIU Wei,ANGUELOV D,ERHAN D,et al. SSD:single shot multi-box Detector[C]. European Conference on Computer Vision,2016:21-37.
[11] 李伟山,卫晨,王琳. 改进的Faster RCNN煤矿井下行人检测算法[J]. 计算机工程与应用,2019,55(4):200-207. DOI: 10.3778/j.issn.1002-8331.1711-0282 LI Weishan,WEI Chen,WANG Lin. Improved faster RCNN approach for pedestrian detection in underground coal mine[J]. Computer Engineering and Applications,2019,55(4):200-207. DOI: 10.3778/j.issn.1002-8331.1711-0282
[12] HE Deqiang,LI Kai,CHEN Yanjun,et al. Obstacle detection in dangerous railway track areas by a convolutional neural network[J]. Measurement Science and Technology,2021,32(10). DOI: 10.1088/1361-6501/abfdde.
[13] HE Kaiming,ZHANG Xiangyu,REN Shaoqing,et al. Identity mappings in deep residual networks[C]. European Conference on Computer Vision,2016:630-645.
[14] 郝帅,张旭,马旭,等. 基于CBAM−YOLOv5的煤矿输送带异物检测[J]. 煤炭学报,2022,47(11):4147-4156. HAO Shuai,ZHANG Xu,MA Xu,et al. Foreign object detection in coal mine conveyor belt based on CBAM-YOLOv5[J]. Journal of China Coal Society,2022,47(11):4147-4156.
[15] 郑玉珩,黄德启. 改进MobileViT与YOLOv4的轻量化车辆检测网络[J]. 电子测量技术,2023,46(2):175-183. ZHENG Yuheng,HUANG Deqi. Lightweight vehicle detection network based on MobileViT and YOLOv4[J]. Electronic Measurement Technology,2023,46(2):175-183.
[16] 杨艺,付泽峰,高有进,等. 基于深度神经网络的综采工作面视频目标检测[J]. 工矿自动化,2022,48(8):33-42. YANG Yi,FU Zefeng,GAO Youjin,et al. Video object detection of the fully mechanized working face based on deep neural network[J]. Journal of Mine Automation,2022,48(8):33-42.
[17] 葛淑伟,张永茜,秦嘉欣,等. 基于优化SSD−MobileNetV2的煤矿井下锚孔检测方法[J]. 采矿与岩层控制工程学报,2023,5(2):66-74. GE Shuwei,ZHANG Yongqian,QIN Jiaxin,et al. Rock bolt borehole detection method for underground coal mines based on optimized SSD-MobileNetV2[J]. Journal of Mining and Strata Control Engineering,2023,5(2):66-74.
[18] GEVORGYAN Z. SIoU loss:more powerful learning for bounding box regression[EB/OL]. [2023-05-12]. https://arxiv.org/abs/2205.12740.
[19] ZHENG Zhaohui,WANG Ping,REN Dongwei,et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J]. IEEE Transactions on Cybernetics,2021,52(8):8574-8586.
[20] WU Yue,CHEN Yinpeng,YUAN Lu,et al. Rethinking classification and localization for object detection[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition,Seattle,2020:10183-10192.
[21] LIN T-Y,DOLLAR P,GIRSHICK R B,et al. Feature pyramid networks for object detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition,Honolulu,2017:936-944.
[22] LIU Shu,QI Lu,QIN Haifang,et al. Path aggregation network for instance segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition,Salt Lake City,2018:8759-8768.
[23] KARAKAYA M,CELEBI M F,GOK A E,et al. Discovery of agricultural diseases by deep learning and object detection[J]. Environmental Engineering and Management Journal,2022,21(1):163-173. DOI: 10.30638/eemj.2022.016


计量
- 文章访问数: 1307
- HTML全文浏览量: 35
- PDF下载量: 64
