
Unsafe action recognition in underground coal mine based on cross-attention mechanism
-
摘要: 对煤矿井下人员不安全行为进行实时视频监控及报警是提升安全生产水平的重要手段。煤矿井下环境复杂,监控视频质量不佳,导致常规基于图像特征或基于人体关键点特征的行为识别方法在煤矿井下应用受限。提出了一种基于交叉注意力机制的多特征融合行为识别模型,用于识别煤矿井下人员不安全行为。针对分段视频图像,采用3D ResNet101模型提取图像特征,采用openpose算法和ST−GCN(时空图卷积网络)提取人体关键点特征;采用交叉注意力机制对图像特征和人体关键点特征进行融合处理,并与经自注意力机制处理后的图像特征和人体关键点特征拼接,得到最终行为识别特征;识别特征经全连接层及归一化指数函数softmax处理后,得到行为识别结果。基于公共数据集HMDB51和UCF101、自建的煤矿井下视频数据集进行行为识别实验,结果表明:采用交叉注意力机制可使行为识别模型更有效地融合图像特征和人体关键点特征,大幅提高识别准确率;与目前应用最广泛的行为识别模型SlowFast相比,基于交叉注意力机制的多特征融合行为识别模型在HMDB51和UCF101数据集上的识别准确率分别提高1.8%,0.9%,在自建数据集上的识别准确率提高6.7%,验证了基于交叉注意力机制的多特征融合行为识别模型更适用于煤矿井下复杂环境中人员不安全行为识别。Abstract: The real-time video monitoring and alarming of unsafe actions of coal mine personnel is an important means to improve the level of safety in production. The coal mine underground environment is complex, and the monitoring video quality is poor. The conventional action recognition method based on image features or human body key point features is limited in application in the underground coal mine. An action recognition model of multi-feature fusion based on cross-attention mechanism is proposed to recognize unsafe actions of coal mine personnel. For segment video images, the 3D ResNet101 model is adopted to extract image features. The openpose algorithm and ST-GCN (space-time graph convolutional network) are adopted to extract human body key point features. The cross-attention mechanism is used to fuse the image features and human key point features. The fused features are spliced respectively with the image features or human key point features processed by the self-attention mechanism to obtain the final action recognition features. The recognition features is processed by the fully connected layer and the normalized exponential function softmax to obtain action recognition result. Based on the public data sets HMDB51 and UCF101, and the self-built coal mine video dataset, the action recognition experiment is carried out. The results show that the cross-attention mechanism can make the action recognition model more effective in fusing image features and human key point features, and greatly improve the recognition accuracy. At present, SlowFast is the most widely used action recognition model. Compared with the SlowFast, the recognition accuracy of the action recognition model of multi-feature fusion based on cross-attention mechanism has been improved by 1.8% and 0.9% for HMDB51 and UCF101 datasets respectively. The recognition accuracy on the self-built dataset has increased by 6.7%. It is verified that the action recognition model of multi-feature fusion based on cross-attention mechanism is more suitable for the recognition of unsafe actions in the complex coal mine environment.
-
0. 引言
煤矿生产是劳动密集型产业,且矿井地质条件复杂,生产环境恶劣,工作人员的不安全、不规范行为容易引发安全生产事故。据统计,85%的安全事故是由生产人员的不安全行为引发的[1]。通过视频监控实时掌握矿井生产重点区域的人员行为,并对不安全行为进行实时报警,是提升煤矿生产安全水平的重要手段[2]。
行为识别是计算机视觉领域的研究热点。目前主流的行为识别方法大致分为基于图像特征的行为识别方法和基于人体关键点特征的行为识别方法2类。其中基于图像特征的行为识别方法应用最广泛。文献[3]首次将深度学习网络用于视频行为识别,提出了经典的双流模型,其中一流用于提取视频中关键帧的图像特征,另一流用于提取视频中每一帧变化带来的光流特征,通过融合图像特征和光流特征进行视频行为识别。文献[4-5]提出了TSN(Temporal Segment Networks,时间切片网络)和TSM(Temporal Shift Module,时间转换模块)模型,其基于双流模型结构,通过改进卷积神经网络性能来提升视频行为识别能力。文献[6]提出了C3D(Convolutional 3D,三维卷积)模型,将图像特征和光流特征提取整合到1个网络结构中进行。文献[7]提出了SlowFast模型,将双流模型与C3D模型结合来感知瞬时行为与长期行为,是目前应用最广泛的视频行为识别模型。
在煤矿井下,基于图像特征的行为识别方法得到一定应用[8-9],但仍面临以下挑战[10]:① 煤矿井下环境复杂,存在粉尘、水雾干扰,且光照度远低于地面环境,极大地影响了监控视频质量。② 井下监控区域一般存在较多的设备和管线等复杂背景物体,增加了有效视觉信息提取难度。③ 井下人员穿着的工作服、安全帽等对视觉信息提取产生影响。考虑上述挑战,基于人体关键点特征的行为识别方法成为煤矿井下行为识别的有效途径。该方法从图像中提取人体关键点进行连接,构建人体骨架图,去除无关图像特征的干扰后,通过GCN(Graph Convolutional Network,图卷积网络)对连续的人体骨架图进行行为识别[11-12]。基于人体关键点特征的行为识别方法可有效去除与行为识别无关的视觉特征,应用于煤矿井下环境中时识别性能优于基于图像特征的行为识别方法[13]。但人体关键点特征提取依赖openpose等算法,直接从监控视频中提取人体关键点时准确度较低,影响识别性能。另外,基于人体关键点特征的行为识别方法需采用特殊摄像头采集人体关键点特征用于模型训练,增大了训练数据的采集难度和成本,不利于该方法推广和应用[14]。
考虑2种行为识别方法的优势和不足,可通过构建复合模型来同时提取图像特征和人体关键点特征,并将2种特征有效融合后用于煤矿井下不安全行为识别,从而在不增大数据采集难度的前提下,有效提高识别性能。本文提出一种基于交叉注意力机制的多特征融合行为识别模型,通过交叉注意力机制将监控视频中的图像特征和人体关键点特征进行有效融合,结合不同特征的特点,降低了煤矿井下环境对行为识别的影响,同时在不额外采集人体关键点特征的情况下,提升了行为识别准确率。
1. 多特征融合行为识别模型架构
图像特征与人体关键点特征在行为识别中关注的重点不同,图像特征关注不同帧之间图像的变化,而人体关键点特征关注关键点之间位置关系的变化,因此使用常规的特征融合函数,如concate(),average(),max()等无法很好地将2种特征进行有效融合。注意力机制可使网络自主寻找关键特征,从而提升网络整体性能。因此,通过注意力机制来提取图像特征和人体关键点特征的有效信息,并通过交叉注意力机制进行特征融合,是一种更为可行的多特征融合方案。
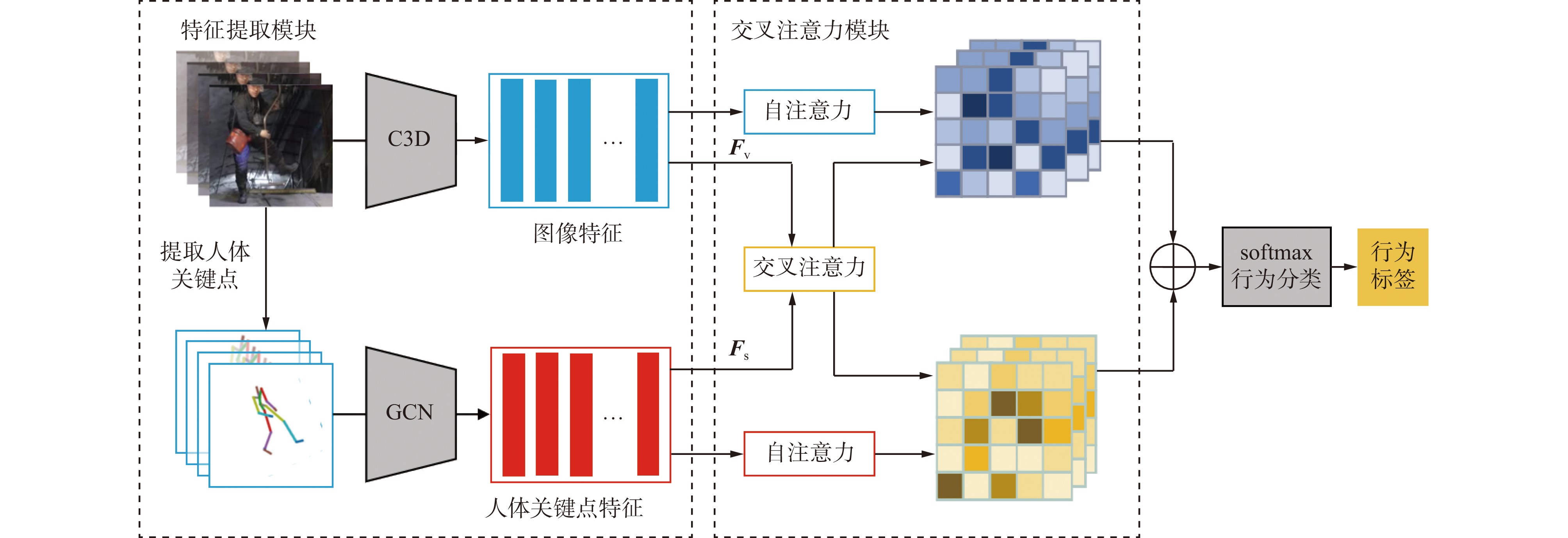
基于交叉注意力机制的多特征融合行为识别模型整体结构如图1所示。该模型主要包括特征提取模块和交叉注意力模块。特征提取模块负责提取待检测视频的三维图像特征
${{\boldsymbol{F}}_{\rm{v}}}$ 和人体关键点特征${{\boldsymbol{F}}_{\rm{s}}}$ ,交叉注意力模块通过自注意力机制和交叉注意力机制对2种特征进行融合。融合后的特征经归一化指数函数softmax进行行为分类。![]() 图 1 基于交叉注意力机制的多特征融合行为识别模型结构Figure 1. Structure of action recognition model of multi-feature fusion based on cross-attention mechanism
图 1 基于交叉注意力机制的多特征融合行为识别模型结构Figure 1. Structure of action recognition model of multi-feature fusion based on cross-attention mechanism2. 行为识别原理
2.1 图像特征提取算法
为了降低计算量,对于一段视频,将其等分为m段。m根据待检测视频长度设定,保证等分后的视频片段长度为1~3 s。通常行为识别视频长度约为10 s,因此本文中m设为8。从每段视频片段中抽取10个连续视频帧,用于图像特征提取。采用3D ResNet101模型[15]提取视频片段的图像特征,共得到m个图像特征。对于任意待检测视频,其图像特征为
${{\boldsymbol{F}}_{\rm{v}}} = \left\{ {{{\boldsymbol{f}}_{{\rm{v}}1}},{{\boldsymbol{f}}_{{\rm{v}}2}},\cdots ,{{\boldsymbol{f}}_{{\rm{v}}m}}} \right\}$ ,${{\boldsymbol{f}}_{{\rm{v}}k}}$ (k=1,2,…,m)为第k个视频片段的图像特征。2.2 人体关键点特征提取算法
提取人体关键点特征时需从视频中提取相应的人体关键点。目前常用openpose算法提取人体关键点,其通过2条并行的卷积神经网络从视频中提取人体的关键点位置和类别[16],如图2所示。
![]() 图 2 openpose算法提取人体关键点效果Figure 2. Human body key points extracted by openpose algorithm
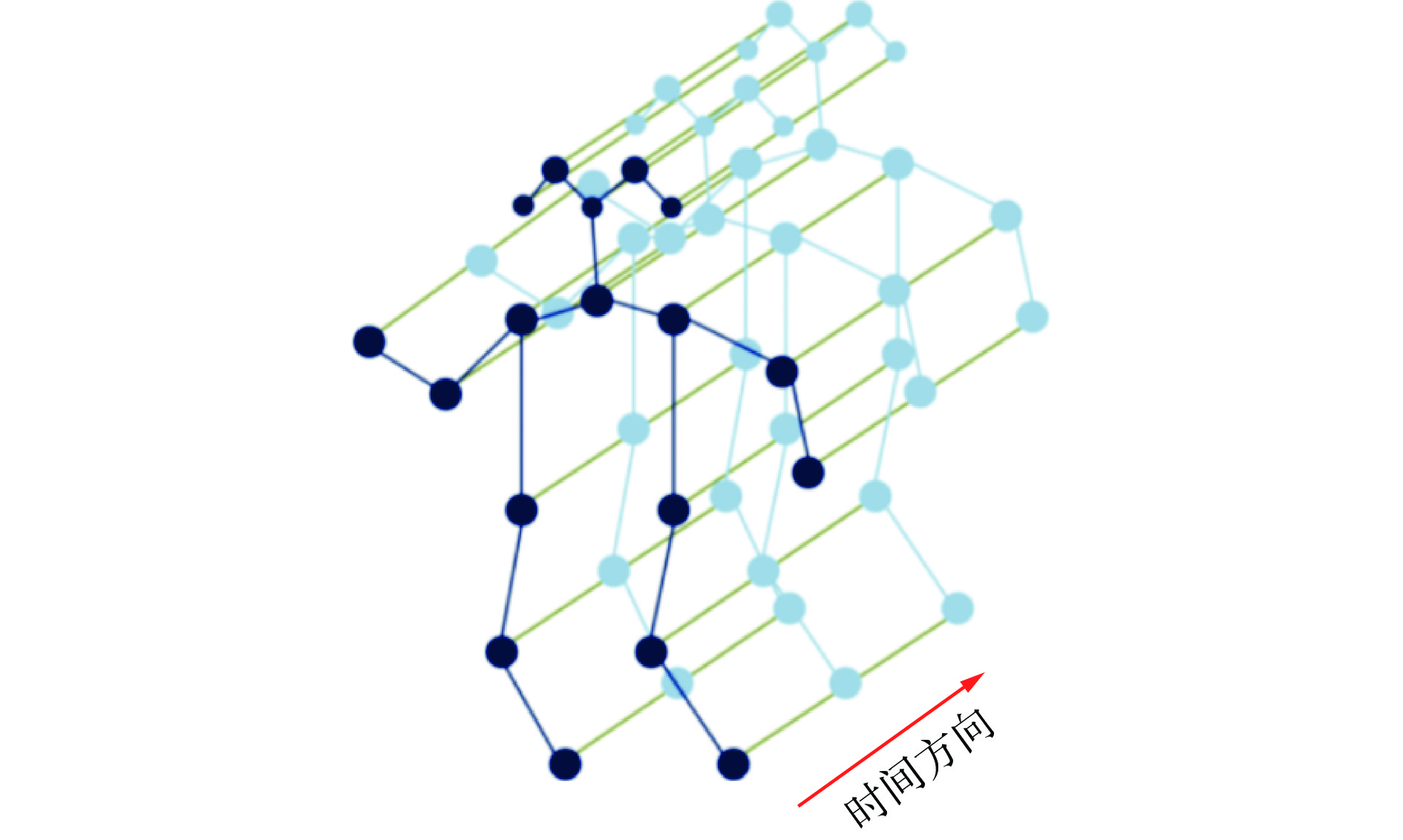
图 2 openpose算法提取人体关键点效果Figure 2. Human body key points extracted by openpose algorithm对于等分后的视频片段,采用openpose算法得到每一帧图像的人体关键点,将关键点按照固定的顺序连接起来,得到该帧图像的人体骨架图。将该视频片段中所有帧图像的人体骨架图按时间顺序排列,得到人体骨架序列图。采用ST−GCN(Spatial Temporal GCN,时空图卷积网络)从人体骨架序列图中提取人体关键点特征[7]。对于给定的人体骨架序列,构建人体骨架时空图
$ {G_{{\rm{ST}}}} = (X,E) $ 来存储人体关键点之间的位置和时间关系。其中顶点集X为人体关键点vi(i=1,2,…,n,n为人体关键点总数)集合,即$ X = \{ {v_i}\} $ ,且X被边E连接,$ E = \{ {e_{\rm{S}}},{e_{\rm{T}}}\} $ ,${e_{\rm{S}}} $ 为不同关键点的连接(即人体骨架图),${e_{\rm{T}}} $ 为同一关键点在不同时刻的连接(即运动轨迹图)。顶点间的连接需符合2个条件:① 在空间上,同一人体骨骼的关键点被空间边${e_{\rm{S}}} $ 连接。② 在时间上,相邻帧的同一个关键点被时间边${e_{\rm{T}}} $ 连接。人体骨架时空图如图3所示,其中蓝色边为空间边${e_{\rm{S}}} $ ,绿色边为空间边${e_{\rm{T}}} $ 。通过ST−GCN提取的人体关键点特征为
$$ {{{\boldsymbol{F}}_{{\rm{s}}}} = \{ {{\boldsymbol{f}}_{{\rm{s}}i}}\} } { = \left\{ { \displaystyle\sum\limits_{{v_j} \in {B_i}} {\boldsymbol{w}} p({v_j}) } \right\}} $$ (1) 式中:
${{{{\boldsymbol{f}}}}_{{{{\rm{s}}i}}}} $ 为第i个人体关键点特征;vj为第i个关键点vi(中心节点)的邻居节点,j=1,2,…,n,且j≠i;Bi为vi的邻居节点集合;w为待学习的权重;${p{({{{v}}_{{j}}})}} $ 为邻居节点vj的采样函数,表示卷积涉及的节点范围,本文设为1,表示只使用中心节点及与其相连的邻居节点。2.3 图像特征自注意力机制
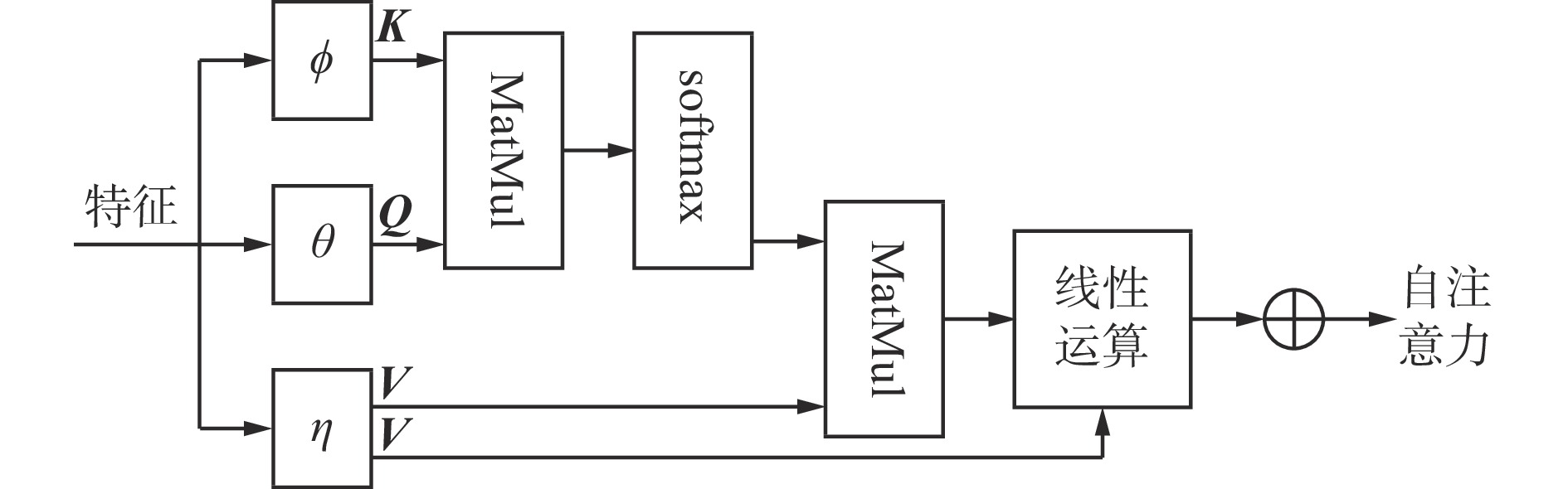
得到待检测视频的图像特征后,采用自注意力机制对其进行处理[17]。图像特征自注意力机制可通过分析整幅图像的全局信息来判断图像各部分对于最终分析结果的影响权重,从而有效去除冗余信息对分析结果的干扰。自注意力机制如图4所示。K,Q,V分别代表键(Key)、查询(Query)和值(Value),分别由可学习的线性映射函数
$ \phi ,\theta ,\eta $ 对特征进行处理得到;MatMul为矩阵相乘函数;$ \oplus $ 为元素相加运算符号。图像特征经线性运算处理后,得到图像特征的键、查询、值为
${{\boldsymbol{K}}_{\rm{v}}} = \phi ({{\boldsymbol{F}}_{\rm{v}}}), {{\boldsymbol{Q}}_{\rm{v}}} = \theta ({{\boldsymbol{F}}_{\rm{v}}}),{{\boldsymbol{V}}_{\rm{v}}} = \eta ({{\boldsymbol{F}}_{\rm{v}}})$ 。通过缩放点积运算可得到图像特征的注意力分数:$$ {{\boldsymbol{S}}_{\rm{v}}}({{\boldsymbol{Q}}_{\rm{v}}},{{\boldsymbol{K}}_{\rm{v}}}) = {\text{softmax}}\left( { \frac{{{{\boldsymbol{Q}}_{\rm{v}}}{\boldsymbol{K}}_{\rm{v}}^{\rm{T}}}}{{\sqrt {{d{{}}}} }} } \right) $$ (2) 式中
$ {d} $ 为$ {{\boldsymbol{Q}}_{\rm{v}}}{\boldsymbol{K}}_{\rm{v}}^{\rm{T}} $ 的维度,用于控制注意力分数的分布范围。经自注意力机制处理后的图像特征为
$$ {{\boldsymbol{Z}}_{\rm{v}}} = {{{{\boldsymbol{S}}}}_{\rm{v}}}{({\boldsymbol{Q}}_{{\rm{v}}},{\boldsymbol{K}_{{\rm{v}}}}){\boldsymbol{V}}_{\rm{v}}^{\rm{T}}} $$ (3) 为便于模型训练,将原图像特征与经自注意力机制处理后的图像特征通过残差连接,得到最终的图像特征:
$$ {{\boldsymbol{F}}'_{\rm{v}}} = {{\boldsymbol{F}}_{\rm{v}}} + {{\boldsymbol{W}}_{\rm{v}}}{{\boldsymbol{Z}}_{\rm{v}}} $$ (4) 式中
$ {{\boldsymbol{W}}_{\rm{v}}} $ 为可学习的图像特征注意力权重矩阵。2.4 人体关键点特征自注意力机制
采用图注意力机制对人体关键点特征进行处理。图注意力机制通过获取图中每个节点的邻域特征为不同节点分配权重,如对于吸烟行为,更关注手部关键点的运动轨迹。图注意力机制原理与图像特征自注意力相似[18],但由于图中节点只有1种特征表示,可认为图注意力机制中人体关键点特征的键、查询、值为
${{\boldsymbol{K}}_{\rm{s}}} = {{\boldsymbol{Q}}_{\rm{s}}} = {{\boldsymbol{V}}_{\rm{s}}} = {\boldsymbol{D}}{{\boldsymbol{F}}_{\rm{s}}}$ ,其中D为可学习的线性变换矩阵。对于任意人体关键点特征
${\boldsymbol{f}}_{{\rm{s}}{i}} $ ,可通过其邻居节点特征${\boldsymbol{f}}_{{\rm{s}}{j}} $ 得到注意力分数:$$ {{\boldsymbol{S}}_{ \rm{s}}} = {{\boldsymbol{c}}_{ij}} = {{\boldsymbol{ a}}^{\rm{T}}}[{\boldsymbol{D}}{{\boldsymbol{f}}_{{\rm{s}}{i}}}||{\boldsymbol{D}}{{\boldsymbol{f}}_{{\rm{s}}{j}}}] $$ (5) 式中:
${{\boldsymbol{c}}_{ij}}$ 为中心节点vi在其邻居节点vj中的注意力分数,可通过权重向量为$ {\boldsymbol{a}} $ 的单层前馈神经网络计算得到;||为拼接运算符号。对
${{\boldsymbol{c}}_{ij}}$ 进行归一化处理,得到归一化后的注意力分数:$$ {{\boldsymbol{b}}_{ij}} = {\text{softmax}}(\delta ({{\boldsymbol{c}}_{ij}})) $$ (6) 式中
$ \delta ( \cdot ) $ 为激活函数,本文采用LeakyRelu函数。经图注意力机制处理后的关键点特征为
$$ {{{\boldsymbol{Z}}_{\rm{s}}} = } {\left\{ { \delta \left( { \displaystyle\sum\limits_{v_{j} \in {B_i}} {{{\boldsymbol{b}}_{ij}}{\boldsymbol{D}}{{\boldsymbol{f}}_{{\rm{s}}{i}}}} } \right) } \right\}} $$ (7) 通过残差将原人体关键点特征与经图注意力机制处理后的人体关键点特征连接,得到最终的人体关键点特征:
$$ {{\boldsymbol{F}}_{\rm{s}}'} = {{\boldsymbol{F}}_{\rm{s}}} + {{\boldsymbol{W}}_{\rm{s}}}{{\boldsymbol{Z}}_{\rm{s}}} $$ (8) 式中
${{\boldsymbol{W}}_{{\rm{s}}}} $ 为可学习的人体关键点特征注意力权重矩阵。2.5 交叉注意力机制
自注意力机制可通过分析全局找出影响最终模型表现的关键特征。但对于多特征模型,还需要通过交叉注意力机制挖掘不同类别特征间的关系。由于图像特征自注意力机制与图注意力机制的原理基本相同,所以可在计算注意力分数时将2种特征交换,从而得到不同特征间的关系。
用
$ {{\boldsymbol{F}}_{\rm{s}}} $ 代替$ {{\boldsymbol{F}}_{\rm{v}}} $ 得到关键点特征在图像特征中的注意力分数${{\boldsymbol{S}}_{{\rm{v}} \leftarrow {\rm{s}}}}({{\boldsymbol{Q}}_{\rm{v}}},{{\boldsymbol{K}}_{\rm{s}}})$ ,$ {{\boldsymbol{F}}_{\rm{v}}} $ 代替$ {{\boldsymbol{F}}_{\rm{s}}} $ 得到图像特征在关键点特征中的注意力分数${{\boldsymbol{S}}_{{\rm{s}} \leftarrow {\rm{v}}}}({{\boldsymbol{Q}}_{\rm{s}}},{{\boldsymbol{K}}_{\rm{v}}})$ ,由此得到经交叉注意力机制融合后的图像特征${{\boldsymbol{Z}}_{\rm{v}}'}$ 和人体关键点特征${{\boldsymbol{Z}}_{\rm{s}}'}$ :$$ \left\{ \begin{array}{l} {{\boldsymbol{Z}}_{\rm{v}}'} = {{\boldsymbol{S}}_{{\rm{v}} \leftarrow {\rm{s}}}}({{\boldsymbol{Q}}_{\rm{v}}},{{\boldsymbol{K}}_{\rm{s}}}){{\boldsymbol{V}}_{\rm{v}}} \\ {{\boldsymbol{Z}}_{\rm{s}}'} = {{\boldsymbol{S}}_{{\rm{s}} \leftarrow {\rm{v}}}}({{\boldsymbol{Q}}_{\rm{s}}},{{\boldsymbol{K}}_{\rm{v}}}){{\boldsymbol{V}}_{\rm{s}}} \end{array} \right. $$ (9) 通过残差连接得到最终的图像融合特征
${{\boldsymbol{F}}_{\rm{v}}''}$ 和人体关键点融合特征${{\boldsymbol{F}}_{\rm{s}}''}$ :$$ \left\{ \begin{array}{l} {{\boldsymbol{F}}_{\rm{v}}''}= {{\boldsymbol{F}}_{\rm{v}}} + {{\boldsymbol{W}}_{\rm{v}}}{{\boldsymbol{Z}}_{\rm{v}}'} \\ {{\boldsymbol{F}}_{\rm{s}}''} = {{\boldsymbol{F}}_{\rm{s}}} + {{\boldsymbol{W}}_{\rm{s}}}{{\boldsymbol{Z}}_{\rm{s}}'} \end{array} \right. $$ (10) 对经过图像特征自注意力机制处理后的图像特征
${{\boldsymbol{F}}_{\rm{v}}'}$ 、图注意力机制处理后的人体关键点特征${{\boldsymbol{F}}_{\rm{s}}'}$ 、交叉注意力机制处理后的融合特征${{\boldsymbol{F}}_{\rm{v}}''} 和{{\boldsymbol{F}}_{\rm{s}}''}$ 进行拼接处理,之后通过全连接层和softmax函数即可得到行为分类结果。3. 实验与结果分析
3.1 实验数据集
为了全面评估基于交叉注意力机制的多特征融合行为识别模型的性能,分别在公开数据集HMDB51[19]和UCF101[20]、自建的煤矿井下视频数据集上进行实验验证。
HMDB51数据集包含51种日常动作,共有6 849段视频,每种动作至少有51段视频,分辨率为320×240。UCF101数据集包含101种动作,可分为人与物体交互、单纯的肢体动作、人与人交互、演奏乐器和体育运动5类,共有13 320段视频。2种公共数据集视频主要来自youtube等网站。自建数据集来自井下实际监控视频,包含井下人员的6种不安全行为,分别为抽烟、打架、徘徊、跌倒、摘安全帽和脱工作服。每种行为各采集120段10 s左右的监控视频片段,共有720段视频,分辨率为640×480。
3.2 实验环境
本文模型使用在Kinetic 400数据集上预训练的3D ResNet101和ST−GCN分别提取图像特征和人体关键点特征。在提取特征前,需将输入视频图像尺寸调整为224×224。模型通过随机梯度下降法进行优化,权值衰减为0.000 5,动量为0.9,学习率为0.001,迭代次数为50,并在第20次迭代和第40次迭代时对学习率进行衰减调整。模型采用pytorch1.7机器学习框架,运行在2块Nvidia Tesla V100 16 GB显卡上。
3.3 公共数据集实验结果及分析
采用公共数据集HMDB51和UCF101,对本文模型与主流的基于图像特征的行为识别模型C3D[6],3D ResNet101[15],TSN[4],SlowFast[7],以及基于人体关键点特征的行为识别模型ST−GCN[8],2S−ACGN(Two-Stream Adaptive GCN,双流渐进图卷积网络)[9]进行对比实验,结果见表1。
表 1 不同行为识别模型在公共数据集上的对比实验结果Table 1. Comparison experiment results of different action recognition models by use of public data sets% 模型 准确率 HMDB51 UCF101 C3D 56.8 82.3 3D ResNet101 61.7 88.9 TSN 68.5 93.4 SlowFast 72.3 95.8 ST−GCN 48.6 78.3 2S−AGCN 51.8 80.2 本文模型 74.1 96.7 从表1可看出,基于图像特征的行为识别模型在HMDB51,UCF101数据集上的表现优于基于人体关键点特征的行为识别模型,原因是HMDB51和UCF101数据集直接采集相关行为视频,而人体关键点特征需通过openpose算法从视频中提取,提取过程中会产生精度损失,影响分类结果。本文模型在所有模型中取得了最优的分类结果,在HMDB51和UCF101数据集上的分类准确率较SlowFast模型分别提高了1.8%和0.9%,验证了本文模型可有效结合图像特征和人体关键点特征,消除了基于人体关键点特征的行为识别模型因关键点提取导致精度损失而难以在实际中应用的缺点。
为了验证本文模型中各模块的有效性,在HMDB51和UCF101数据集上进行消融实验,结果见表2,其中√和×分别表示采用和未采用相关模块。从表2可看出,不管是图像特征还是人体关键点特征,添加自注意力模块均能提升模型的行为识别准确率,验证了自注意力机制的有效性。因图像特征与人体关键点特征差别较大,直接将2种特征进行拼接融合与采用单一特征提取网络+自注意力机制相比并无明显优势。而采用自注意力机制后,可在一定程度上去除影响结果的冗余信息,提升融合效果,但识别准确率仍低于SlowFast模型。采用交叉注意力机制后,图像特征和人体关键点特征得到更有效的融合,识别准确率大幅提升。
表 2 消融实验结果Table 2. Ablation experiment results% 图像特征
提取网络人体关键点特
征提取网络自注意力
机制交叉注意力
机制准确率 HMDB51 UCF101 √ × × × 61.7 88.9 √ × √ × 63.3 89.7 × √ × × 48.6 78.3 × √ √ × 51.8 81.4 √ √ × × 63.2 88.5 √ √ √ × 69.0 92.7 √ √ √ √ 74.1 96.7 3.4 自建数据集实验结果及分析
在自建数据集上对本文模型与主流的行为识别模型进行对比实验,结果见表3。可看出主流的行为识别模型在自建数据集上的识别准确率较UCF101数据集有一定程度的下降,原因是UCF101数据集中图像背景简单,自建数据集中图像背景较复杂,说明复杂背景对行为识别准确率有一定影响。本文模型在自建数据集上的识别准确率较其他模型高,且结合表1数据可知,本文模型对不同场景下数据集的识别性能更加稳定,更适用于煤矿井下复杂环境下的人员不安全行为识别。
表 3 不同行为识别模型在自建数据集上的对比实验结果Table 3. Comparison experiment results of different action recognition models by use of built underground video data sets% 模型 准确率 模型 准确率 C3D 75.4 ST−GCN 63.4 3D ResNet101 78.7 2S−AGCN 70.9 TSN 81.5 本文模型 91.3 SlowFast 84.6 本文模型对不同行为类别的识别准确率见表4。其中抽烟、打架、徘徊和跌倒动作因特征较明显,识别准确率较高。而脱工作服和摘安全帽这2种行为动作幅度较小,且因监控视频分辨率较低,识别准确率较其他行为类别低。不同模型对摘安全帽行为的识别结果如图5所示,可看出本文模型更关注头部特征,与SlowFast模型和2S−AGCN模型相比,能更准确地检测出摘安全帽行为。
表 4 本文模型对不同行为类别的识别结果Table 4. Action recognition results of different action types by the proposed model% 行为类别 准确率 行为类别 准确率 抽烟 93.7 跌倒 95.8 打架 91.5 摘安全帽 84.2 徘徊 93.2 脱工作服 89.4 ![]() 图 5 不同模型对摘安全帽行为的识别结果Figure 5. Recognition results of removing safety helmet by different models
图 5 不同模型对摘安全帽行为的识别结果Figure 5. Recognition results of removing safety helmet by different models4. 结论
(1) 分析了基于图像特征和基于人体关键点特征的行为识别方法优缺点,提出采用交叉注意力机制将2种不同特征有效结合,构建了一种基于交叉注意力机制的多特征融合行为识别模型。
(2) 在公共数据集HMDB51,UCF101上对基于交叉注意力机制的多特征融合行为识别模型进行消融实验,结果表明,该模型采用交叉注意力机制可更有效地融合图像特征和人体关键点特征,大幅提高了识别准确率。
(3) 在公共数据集HMDB51,UCF101及自建的煤矿井下视频数据集上对主流的行为识别模型和基于交叉注意力机制的多特征融合行为识别模型进行对比实验,结果表明,与目前应用最广泛的行为识别模型SlowFast相比,基于交叉注意力机制的多特征融合行为识别模型在HMDB51和UCF101数据集上的识别准确率分别提高了1.8%,0.9%,在自建数据集上的识别准确率提高了6.7%,验证了基于交叉注意力机制的多特征融合行为识别模型更适用于煤矿井下复杂环境中人员不安全行为识别。
-
![]()
图 1 基于交叉注意力机制的多特征融合行为识别模型结构
Figure 1. Structure of action recognition model of multi-feature fusion based on cross-attention mechanism
![]()
图 2 openpose算法提取人体关键点效果
Figure 2. Human body key points extracted by openpose algorithm
![]()
图 5 不同模型对摘安全帽行为的识别结果
Figure 5. Recognition results of removing safety helmet by different models
表 1 不同行为识别模型在公共数据集上的对比实验结果
Table 1 Comparison experiment results of different action recognition models by use of public data sets
% 模型 准确率 HMDB51 UCF101 C3D 56.8 82.3 3D ResNet101 61.7 88.9 TSN 68.5 93.4 SlowFast 72.3 95.8 ST−GCN 48.6 78.3 2S−AGCN 51.8 80.2 本文模型 74.1 96.7  下载: 导出CSV
下载: 导出CSV
表 2 消融实验结果
Table 2 Ablation experiment results
% 图像特征
提取网络人体关键点特
征提取网络自注意力
机制交叉注意力
机制准确率 HMDB51 UCF101 √ × × × 61.7 88.9 √ × √ × 63.3 89.7 × √ × × 48.6 78.3 × √ √ × 51.8 81.4 √ √ × × 63.2 88.5 √ √ √ × 69.0 92.7 √ √ √ √ 74.1 96.7
下载: 导出CSV
表 3 不同行为识别模型在自建数据集上的对比实验结果
Table 3 Comparison experiment results of different action recognition models by use of built underground video data sets
% 模型 准确率 模型 准确率 C3D 75.4 ST−GCN 63.4 3D ResNet101 78.7 2S−AGCN 70.9 TSN 81.5 本文模型 91.3 SlowFast 84.6
下载: 导出CSV
表 4 本文模型对不同行为类别的识别结果
Table 4 Action recognition results of different action types by the proposed model
% 行为类别 准确率 行为类别 准确率 抽烟 93.7 跌倒 95.8 打架 91.5 摘安全帽 84.2 徘徊 93.2 脱工作服 89.4
下载: 导出CSV
-
[1] 党伟超,史云龙,白尚旺,等. 基于条件变分自编码器的井下配电室巡检行为检测[J]. 工矿自动化,2021,47(12):98-105. DOI: 10.13272/j.issn.1671-251x.2021030087 DANG Weichao,SHI Yunlong,BAI Shangwang,et al. Inspection behavior detection of underground power distribution room based on conditional variational auto-encoder[J]. Industry and Mine Automation,2021,47(12):98-105. DOI: 10.13272/j.issn.1671-251x.2021030087
[2] 王国法,任怀伟,赵国瑞,等. 煤矿智能化十大“痛点”解析及对策[J]. 工矿自动化,2021,47(6):1-11. DOI: 10.13272/j.issn.1671-251x.17808 WANG Guofa,REN Huaiwei,ZHAO Guorui,et al. Analysis and countermeasures of ten 'pain points' of intelligent coal mine[J]. Industry and Mine Automation,2021,47(6):1-11. DOI: 10.13272/j.issn.1671-251x.17808
[3] SIMONYAN K, ZISSERMAN A. Two-streamconvolutional networks for action recognition in videos[Z]. arXiv Preprint, arXiv:1406.2199v2.
[4] WANG Limin, XIONG Yuanjun, WANG Zhe, et al. Temporal segment networks: towards good practices for deep action recognition[C]. European Conference on Computer Vision, Amsterdam, 2016: 20-36.
[5] JI Lin, GAN Chuang, HAN Song. TSM: temporal shift module for efficient video understanding[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, 2019: 7083-7093.
[6] LIU Kun, LIU Wu, GAN Chuang, et al. T-C3D: temporal convolutional 3D network for real-time action recognition[C]. The AAAI Conference on Artificial Intelligence, New Orleans, 2018: 7138-7145.
[7] FEICHTENHOFER C, FAN H, MALIK J, et al. Slowfast networks for video recognition[C]. The IEEE International Conference on Computer Vision, Long Beach, 2019: 6202-6211.
[8] 党伟超,张泽杰,白尚旺,等. 基于改进双流法的井下配电室巡检行为识别[J]. 工矿自动化,2020,46(4):75-80. DOI: 10.13272/j.issn.1671-251x.2019080074 DANG Weichao,ZHANG Zejie,BAI Shangwang,et al. Inspection behavior recognition of underground power distribution room based on improved two-stream CNN method[J]. Industry and Mine Automation,2020,46(4):75-80. DOI: 10.13272/j.issn.1671-251x.2019080074
[9] 刘浩,刘海滨,孙宇,等. 煤矿井下员工不安全行为智能识别系统[J]. 煤炭学报,2021,46(增刊2):1159-1169. DOI: 10.13225/j.cnki.jccs.2021.0670 LIU Hao,LIU Haibin,SUN Yu,et al. Intelligent recognition system of unsafe behavior of underground coal miners[J]. Journal of China Coal Society,2021,46(S2):1159-1169. DOI: 10.13225/j.cnki.jccs.2021.0670
[10] 张立亚. 基于图像识别的煤矿井下安全管控技术[J]. 煤矿安全,2021,52(2):165-168. DOI: 10.13347/j.cnki.mkaq.2021.02.032 ZHANG Liya. Safety control technology of coal mine based on image recognition[J]. Safety in Coal Mines,2021,52(2):165-168. DOI: 10.13347/j.cnki.mkaq.2021.02.032
[11] YAN Sijie, XIONG Yuanjun, LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]. The AAAI Conference on Artificial Intelligence, New Orleans, 2018: 7444-7452.
[12] SHI Lei, ZHANG Yifan, CHENG Jian, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, 2019: 12026-12035.
[13] 黄瀚,程小舟,云霄,等. 基于DA−GCN的煤矿人员行为识别方法[J]. 工矿自动化,2021,47(4):62-66. DOI: 10.13272/j.issn.1671-251x.17721 HUANG Han,CHENG Xiaozhou,YUN Xiao,et al. DA-GCN-based coal mine personnel action recognition method[J]. Industry and Mine Automation,2021,47(4):62-66. DOI: 10.13272/j.issn.1671-251x.17721
[14] 王璇,吴佳奇,阳康,等. 煤矿井下人体姿态检测方法[J]. 工矿自动化,2022,48(5):79-84. DOI: 10.13272/j.issn.1671-251x.17867 WANG Xuan,WU Jiaqi,YANG Kang,et al. Human posture detection method in coal mine[J]. Journal of Mine Automation,2022,48(5):79-84. DOI: 10.13272/j.issn.1671-251x.17867
[15] HARA K, KATAOKA H, SATOH Y. Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and imagenet[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, 2018: 6546-6555.
[16] CAO Zhe, SIMON T, WEI S-E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]. The IEEE International Conference on Computer Vision, Honolulu, 2017: 7291-7299.
[17] WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. The IEEE International Conference on Computer Vision, Salt Lake City, 2018: 7794-7803.
[18] VELICKOVIC P, CUCURULL G, CASANOVA A, et al. Graph attention networks[Z]. arXiv Preprint, arXiv: 1710.10903.
[19] KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: a large video database for human motion recognition[C]. International Conference on Computer Vision, Barcelona, 2011: 2556-2563.
[20] SOOMORO K, ZAMIR A R, SHAH M. UCF101: a dataset of 101 human actions classes from videos in the wild[Z]. arXiv Preprint, arXiv: 1212.0402.






















































计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
