
Underground personnel recognition based on low-light enhancement of infrared and visible light image fusion
-
摘要:
井下环境存在低光照,人员特征不明显。现有的基于深度学习的红外与可见光图像融合方法在弱光条件下,只使用红外信息来填补可见光图像光照退化造成的场景缺陷,导致在黑暗环境下可见光图像中丰富的场景信息无法在融合图像中表达出来;将图像增强和图像融合作为单独的任务来处理,导致融合结果较差。针对上述问题,提出了一种基于低光照增强的红外和可见光图像融合的井下人员识别模型。首先,将可见光和红外传感器图像进行灰度化、几何校正等预处理操作,然后,将处理后的图像传入低光照增强网络,在特征层面去除退化可见光图像的照度分量,最后,经过纹理−对比度增强网络实现特征级融合,从纹理和对比度等方面增强了整体的视觉感知。实验结果表明,所提模型的井下人员识别结果相比较可见光图像,准确率平均提高了8.2%,召回率提高了12.5%,mAP@0.5提高了8.3%;相比红外图像,准确率平均提高了2.1%,召回率提高了5.1%,mAP@0.5提高了4.1%;检测速度达31.2帧/s,解决了井下低光照场景下人员特征不明显所导致的错检、漏检等问题。
-
关键词:
- 井下人员识别 /
- 低光照增强 /
- 红外和可见光图像融合 /
- 边缘纹理增强 /
- 对比度增强
Abstract:In underground environments, there is low light, and personnel features are not clearly visible. Existing infrared and visible light image fusion methods based on deep learning use only infrared information to fill in the scene defects caused by the light degradation of visible images under weak lighting conditions. As a result, rich scene information from visible images is lost in the fused image in dark environments. Moreover, treating image enhancement and image fusion as separate tasks leads to poor fusion results. To address the above issues, a model for underground personnel recognition based on low-light enhancement of infrared and visible light image fusion was proposed. First, the visible and infrared sensor images underwent preprocessing steps such as grayscaling and geometric correction. Then, the processed images were passed into a low-light enhancement network, which removed the illumination component from the degraded visible light images at the feature level. Finally, texture-contrast enhancement networks performed feature-level fusion, enhancing overall visual perception in terms of texture and contrast. Experimental results showed that the proposed model improved underground personnel recognition results compared to the visible light modality, with an average accuracy increase of 8.2%, recall rate increase of 12.5%, and mAP@0.5 increase of 8.3%. Compared to the infrared modality, accuracy increased by an average of 2.1%, recall rate increased by 5.1%, and mAP@0.5 increased by 4.1%. Meanwhile, the detection speed reached 31.2 frames/s, solving problems such as misdetection and missed detection caused by unclear personnel features in low-light underground scenarios.
-
0. 引言
带式输送机是井下煤炭运输的关键设备,在煤矿带式输送机运输煤流过程中,可能有锚杆、木条、铁块、纺织物等异物掺杂在煤块中,易造成输送带损毁甚至撕裂,引发安全事故,且这些异物还可能对煤炭的质量造成一定的影响。因此,实时、精准识别带式输送机异物对于确保煤矿安全生产尤为重要[1]。
传统的带式输送机异物检测方法主要包括人工检测法、金属探测器检测法、雷达检测法3种[2]。人工检测法效率低、工作量大;金属探测器检测法检测类型不全面,只能检测金属类异物;雷达检测法成本高、难以广泛应用。随着目标检测技术的发展,众多学者利用深度学习方法进行异物识别。基于深度学习的目标检测算法主要分为Two−stage和One−stage 2类。Two−stage代表算法有R−CNN系列,其将输入图像先经过候选框生成网络,再经过分类网络对候选框中内容进行分类[3]。吴守鹏等[4]提出了一种Faster−RCNN+双向金子塔网络的运煤输送带异物识别模型,有效提升了小尺寸异物的检测能力。One−stage代表算法有YOLO系列,该类算法直接对网络进行端对端训练,生成的结果中同时包含位置和类别信息。郝帅等[5]提出一种融合卷积注意力模型的YOLOv5煤矿输送带异物检测算法,较好地解决了异物目标检测时易受煤尘干扰、输送带高速运动影响目标检测精度等问题。任国强等[6]采用Fast YOLOv3算法,利用StiPic数据增强方法提高对胶带运输异物的平均检测精度。陈永等[7]利用稀疏化和通道剪枝方法对YOLOv3模型进行压缩,构建了轻量级异物检测模型,其检测速度分别是YOLOv3模型和Faster R−CNN模型的1.3,3.4倍。杨锦辉等[8]在YOLOv5s网络中引入GhostConv卷积减少模型参数量,实现了检测速度的提升。胡璟皓等[9]采用Focal Loss函数替代YOLOv3模型中的交叉熵损失函数及调整最佳超参数来平衡样本之间比例,有效解决了现有非煤异物图像识别法识别目标单一、模型缺乏定位等问题。
基于深度学习的目标检测算法在异物检测中具有较好的识别效果,但模型内存需求大,检测速度慢;轻量化深度学习网络能够大幅减少模型内存需求,提升检测速度,然而,在井下弱光环境中检测精度低。为此,本文提出了一种基于Faster−YOLOv7的带式输送机异物实时检测方法。通过轻量化设计YOLOv7主干网络来降低模型的内存需求,进而提升模型对异物的检测速度;利用限制对比度自适应直方图均衡化(Contrast Limited Adaptive Histogram Equalization,CLAHE)[10]算法来提升煤矿井下弱光环境下的检测效果;设计有效通道注意力机制来缓解高层信息丢失对目标检测精度的影响;使用Alpha−IoU回归损失函数提高检测精度。
1. 异物检测流程
基于Faster−YOLOv7的带式输送机异物实时检测流程如图1所示。首先,采集带式输送机运煤监控视频数据。其次,截取监控视频中包含异物的数据帧,构建异物数据集,并通过数据增强操作来提高数据集质量。然后,对Faster−YOLOv7异物检测模型进行训练,并存储最优的权重文件。最后,输入实时监控视频数据,经过图像增强预处理后,读取Faster−YOLOv7模型实现异物检测,并存储异物信息。
2. 图像增强
煤矿井下弱光环境导致摄像头采集的实时图像存在模糊、异物边缘不清晰等问题,从而影响模型的推理结果,本文采用CLAHE算法对采集到的图像进行弱光增强,通过限制对比度,避免直方图中出现陡峭部分。CLAHE裁剪再分配过程如图2所示,带式输送机上运煤视频图像经过限制对比度自适应直方图均衡化处理后的效果如图3所示。可看出经过CLAHE算法处理后,在图像较暗处物体的边缘变得清晰,特征较原图更明显。
为了客观评价CLAHE算法对煤矿井下带式输送机运煤图像弱光增强的有效性,选取Brenner梯度函数、Energy of Gradient函数、Roberts函数作为评价指标来衡量图像增强后的清晰度,评价结果见表1。可看出经过CLAHE算法处理后的Brenner函数值、Energy of Gradient函数值、Roberts函数值均大于原图,说明该算法可使煤矿井下带式输送机运煤视频图像更清晰,表明CLAHE算法可有效解决煤矿井下弱光环境导致的图像不清晰、对比度低、边缘信息模糊等问题,达到了图像增强的效果。经过弱光环境图像增强,可提高图像的对比度,使模型的推理结果更精准。
表 1 图像增强评价结果Table 1. Evaluation results of image enhancement评价指标 原图 CLAHE Brenner函数值 81.447 152.479 Energy of Gradient函数值 55.311 99.494 Roberts函数值 103.655 186.282 3. 改进YOLOv7模型
YOLOv7模型[11]主要由Input、Backbone、Head 3个部分组成。Input部分沿用YOLOv5采取的mosaic数据增强、自适应锚框计算、图像自适应缩放等对数据进行预处理。Backbone部分用于特征提取。Head部分主要由SPPCSPC模块、ELAN−H模块、REP模块等组成,其中SPPCSCP模块[12]通过最大池化操作来获得不同的感受野,使网络适应不同分辨率的图像;ELAN−H模块[13]通过控制最短和最长梯度路径,使网络能够学习更多特征,且具有更强的鲁棒性;REP模块[14]通过结构重参数实现训练和推理时的解耦合,降低网络的计算量,提升速度。然而,YOLOv7模型内存需求大,难以满足在嵌入式设备上实现井下带式输送机异物实时、精准检测的需求。鉴此,本文设计了Faster−YOLOv7模型,其网络结构如图4所示。
3.1 主干特征提取网络轻量化
YOLOv7主干网络的核心模块是ELAN结构[15],如图5所示,该结构的优势是在每个branch操作中,输入和输出的通道数保持一致,符合设计网络的高效准则之一。然而采用原始主干网络进行特征提取,所得到的模型内存需求大,难以部署在嵌入式设备上实现实时异物检测[16]。因此,本文采用MobileNetv3[17]作为主干网络来构建Faster−YOLOv7。
Bneck是MobileNetv3的核心模块,主要由通道可分离卷积、压缩与激励网络(Squeeze-and-Excitation,SE)通道注意力机制、残差连接实现,其结构如图6所示。首先经过$ 1 \times 1 $卷积操作实现升维。其次经过$ 3 \times 3 $ 深度可分离卷积保持通道数不变。再次经过SE通道注意力模块,使网络通过学习来自动获取每个特征通道的重要程度。在SE模块中,利用exp size代表第1层1×1卷积升级的维度,先对每个通道全局平均池化得到($ 1 \times 1 \times \exp {\text{ size}} $)向量,再经过全连接层、ReLU激活函数得到($ 1 \times 1 \times ( {\exp {\text{ size}}/4} ) $)向量,然后经过全连接层、h-sigmoid激活函数得到($ 1 \times 1 \times \exp {\text{ size}} $)向量,向量内元素取值为$ (0,1) $,将该向量中的每个元素乘以对应权重后,输入到与之相对应通道的特征矩阵中,得到1个与原始特征图大小相等的新特征图。最后通过$ 1 \times 1 $卷积实现降维处理。
3.2 有效通道注意力机制
SE模块中采用的降维操作会对通道注意力的预测效果产生负面影响,低效获取所有通道之间的依赖关系。因此,本文在主干网络的末端添加有效通道注意力机制(Effective Channel Attention Mechanism,ECA)模块[18],加强整体的通道特征,提高模型性能。
ECA模块结构如图7所示。在空间维度上,使用全局平均池化(Global Average Pooling,GAP)对维度为$ H \times W \times C $的特征图A进行特征压缩,得到一个维度为$ 1 \times 1 \times C $的特征图B。通过$ 1 \times 1 $卷积对特征图B进行通道特征学习,并将$ 1 \times 1 \times C $的通道注意力的特征图与$ H \times W \times C $原始输入特征图进行逐通道相乘,输出具有通道注意力的特征图[19]。
卷积操作中的卷积核大小会影响感受野。卷积核大小和通道数C之间存在一种映射关系(式(1)),ECA模块为了避免维度缩减,并有效捕获跨通道交互,通过一维卷积来完成跨通道间的信息交互,该卷积核的大小通过函数$ \psi (C) $自适应变化(式(2)),使通道数较大的层可以更多地进行跨通道交互。
$$ C=2^{\gamma k-\delta} $$ (1) $$ k=\psi(C)=\left|\frac{{\mathrm{log}}_2C}{\gamma}+\frac{\delta}{\gamma}\right|_\mathrm{{odd}} $$ (2) 式中:$ k $为卷积核大小;$ \gamma,\delta $为常数,$ \gamma = 2,\delta = 1 $,用于改变通道数和卷积核之间的比例;$ |\cdot {|_{{\mathrm{odd}}}} $为$ k $只能取奇数。
3.3 Alpha−IoU损失函数
在Head部分,损失函数的选取尤为重要,期望值和真实值越接近,其损失函数值越小。YOLOv7的损失函数主要包含分类损失、物体置信度损失、边界框回归损失,其中分类损失和置信度损失使用交叉熵损失,回归损失使用CIoU[20]。然而,CIoU损失函数反映纵横比的差异,而不是宽高与其置信度的真实差异,阻碍模型有效地优化相似性。因此,本文采用Alpha−IoU代替CIoU作为回归损失函数,Alpha−IoU损失函数可泛化成具有多个惩罚项的IoU损失函数[21]。当权重系数$ \alpha>1 $时,能够提升高置信度目标的损失值和梯度,获得更好的框回归效果,使得网络对异物的预测结果更精准。
$$ {L_{\alpha - {\mathrm{CIoU}}}} = 1 - {Y^\alpha } + \frac{{{\rho ^{2\alpha }}(b,{b^{{\mathrm{gt}}}})}}{{{c^{2\alpha }}}} + {(\beta v)^\alpha } $$ (3) 式中:$ {L_{\alpha - {\mathrm{CIoU}}}} $为Alpha−IoU损失函数;Y为交并比的值;$ \rho^{2\alpha}(b,b\mathrm{^{gt}}) $为预测框和真实框的中心点之间的欧氏距离;$ b $为预测框的中心点;$ b\mathrm{^{gt}} $为真实框的中心点;$ c $为预测框和真实框形成外接矩形的对角线长度;$\, \beta $为trade-off参数;$ v $为度量高宽比的一致性参数。
4. 实验结果与分析
带式输送机异物实时检测实验平台环境:Windows11操作系统,CPU为Inter i5−12400F,GPU为NVIDIA GeForce RTX 3070,Faster−YOLOv7使用Pytorch进行模型搭建。
实验所采用的数据集来自某煤矿井下带式输送机运行时的监控视频数据。经过数据增强后,数据集由2 920张图像组成,将异物标签设置为YW,随机选取2 190张图像作为训练集,730张图像作为测试集。
为了验证本文所提Faster−YOLOv7模型的优势,将其与YOLOv5模型、YOLOv7模型进行对比,模型训练损失函数对比如图8所示,模型检测速度、内存需求、准确率对比见表2。
表 2 检测模型性能Table 2. Detection model performance模型 检测速度/(帧·s−1) 模型内存/MiB 准确率/% YOLOv5 25 43 82.5 YOLOv7 22 71 94.5 Faster−YOLOv7 42 14 91.3 由图8可看出,YOLOv5模型在迭代次数为25时,损失值降为0.09,并最终稳定在0.069左右;YOLOv7模型的初始损失值为0.089,在迭代次数为25时,损失值降为0.053,并最终稳定在0.028左右;Faster−YOLOv7模型的初始损失值为0.143,最终稳定在0.039左右。这说明Faster−YOLOv7模型的训练效果优于YOLOv5模型;由于对YOLOv7主干网络进行轻量化设计、引入ECA机制、使用Alpha−IoU损失函数,导致训练效果略差于YOLOv7模型。
由表2可看出,Faster−YOLOv7模型的检测速度可达42帧/s,较YOLOv5模型、YOLOv7模型分别提升了17,20帧/s;Faster−YOLOv7模型内存为14 MiB,较YOLOv5模型、YOLOv7模型分别降低了29,57 MiB;检测准确率达91.3%,较YOLOv5模型提升了8.8%。这说明Faster−YOLOv7模型更加灵活,检测效率更高,便于部署在嵌入式设备上实现实时检测。
为测试本文改进模型的效果,进行消融实验。首先,使用MobileNetv3轻量化设计YOLOv7主干网络的模型为基础模型;然后,分别测试使用CLAHE进行图像预处理、引入ECA机制、使用Alpha−IoU损失函数的效果;最后,将3种改进策略同时加入基础模型。消融实验结果见表3。
表 3 消融实验结果Table 3. Ablation test results改进策略 准确率/% 检测速度/(帧·s−1) CLAHE ECA Alpha−IoU × × × 83.4 53 √ × × 85.8 49 × √ × 85.9 46 × × √ 85.1 48 √ √ √ 91.3 42 由表3可看出,在该模型中分别单独使用CLAHE进行图像预处理、引入ECA机制、使用Alpha−IoU损失函数后,模型的检测准确率分别提升了2.4%、2.5%和1.7%,检测速度分别降低了4,7,5帧/s;使用CLAHE进行图像预处理、添加ECA模块及Alpha−IoU损失函数的完整改进模型检测准确率达91.3%,检测速度保持在42 帧/s,性能提升明显。
为验证Faster−YOLOv7优势,将Faster−YOLOv7部署到NVIDIA Jetson TX2嵌入式设备上,对煤矿井下带式输送机运煤图像及视频进行检测,并与SSD、YOLOv5、轻量化YOLOv7目标检测算法进行对比,检测结果如图9所示。
由图9可看出,SSD模型在视频检测时发生了漏检现象,YOLO系列模型均有效地识别出待测异物,且Faster−YOLOv7识别结果的置信度更高。从SSD模型、YOLOv5模型、轻量化YOLOv7模型的检测效果来看,均发生了误检现象,而本文在引入ECA机制、使用Alpha−IoU损失函数后,使得异物具有更显著的特征表达,因此模型更关注异物,较好地避免了误检现象的发生。
5. 结论
1) 为了减少井下弱光环境对轻量化神经网络模型推理造成的影响,采用CLAHE算法进行预处理后,检测精度提升了2.4%。
2) 采用MobileNetv3轻量化设计YOLOv7的主干网络、添加ECA机制及引入Alpha−IoU损失函数,显著提升了模型的检测效率。改进后的模型与YOLOv7模型相比,内存需求降低了57 MiB,检测速度提升了20帧/s。
3) 对Faster−YOLOv7算法的异物检测效果进行实验验证,结果表明,在检测精度达91.3%的同时,检测速度达42 帧/s,模型的内存需求仅为14 MiB,满足煤矿井下带式输送机异物实时、精准检测的需求。
4) 将Faster−YOLOv7模型部署在嵌入式设备上,对带式输送机进行异物检测,其识别结果的置信度与SSD模型、YOLOv5模型及轻量化YOLOv7模型相比均有所提高,且有效减少了误检、漏检现象的发生。
-
![]()
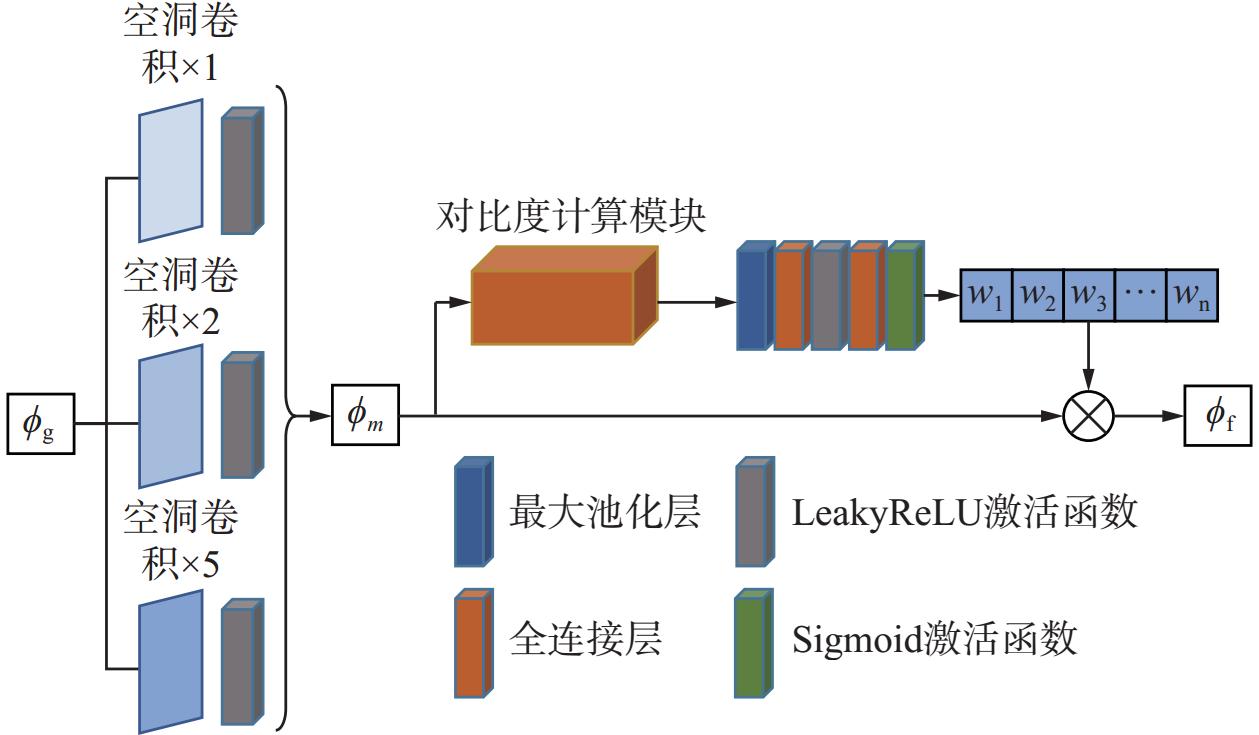
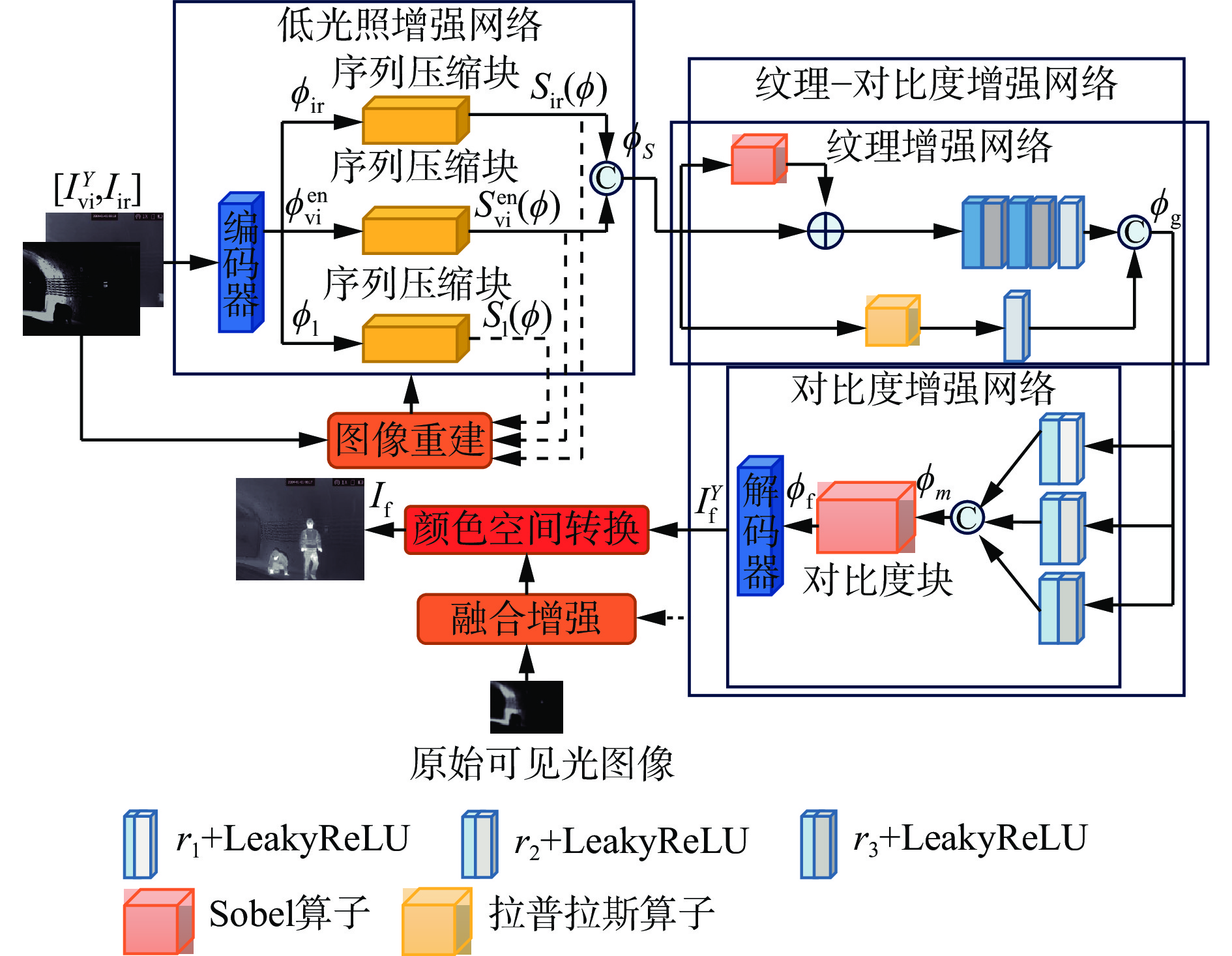
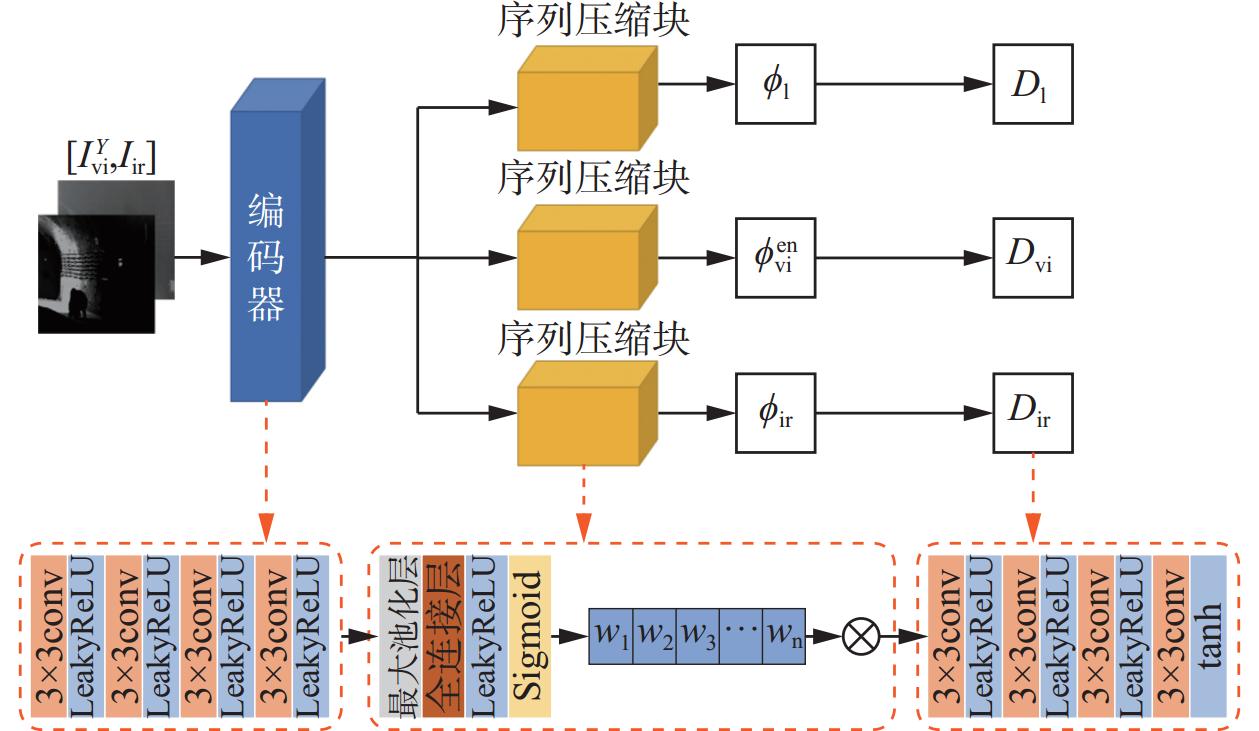
图 4 基于低光照增强的红外和可见光图像融合模型结构
Figure 4. Structure of infrared and visible light image fusion model based on low light enhancement
![]()
图 5 各融合模型在LLVIP数据集上的可视化结果
Figure 5. Visualization results of each fusion model on the LLVIP dataset
![]()
图 6 不同检测网络下人员识别效果对比
Figure 6. Comparison of personnel recognition effects in different detection networks
![]()
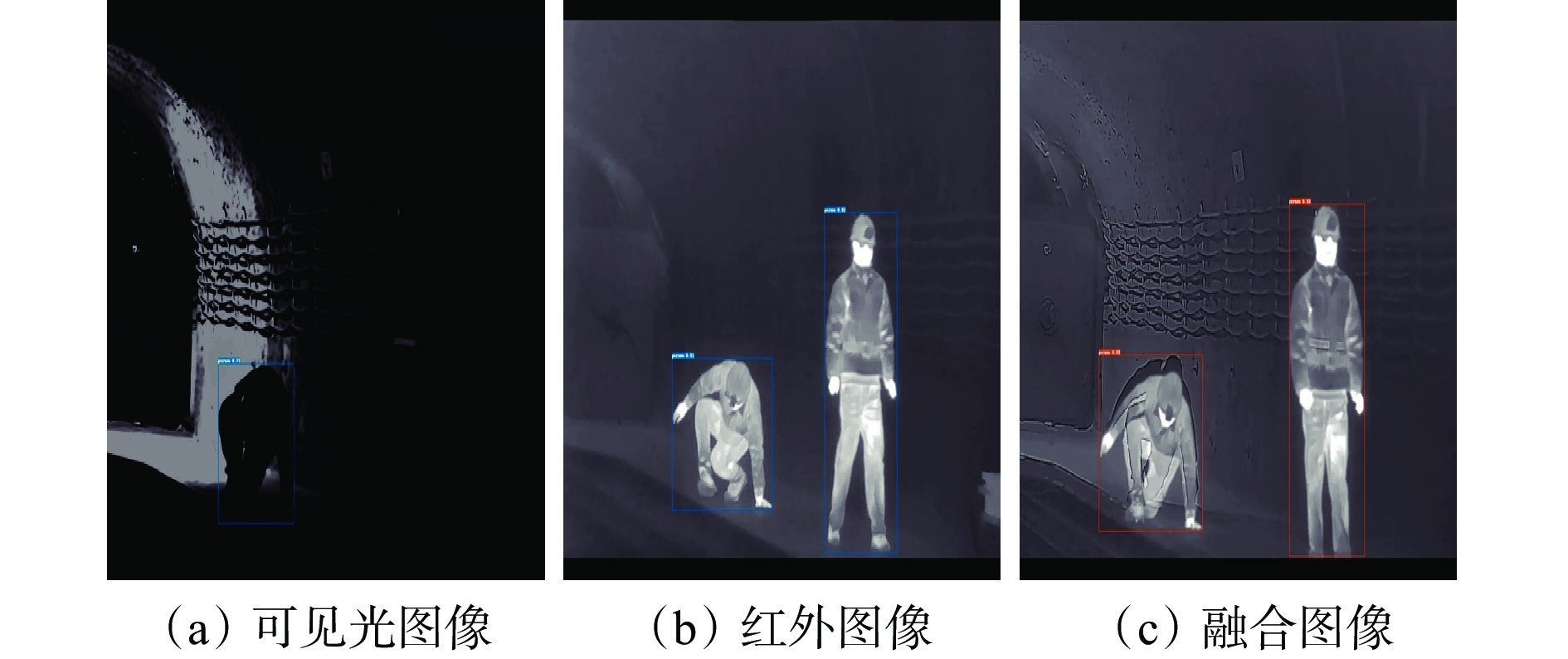
图 7 不同图像下人员识别可视化
Figure 7. Visualization of personnel identification in different modalities
表 1 软件配置
Table 1 Software configuration
库 版本 库 版本 Python 3.9 OpenCV 4.7 Pytorch 1.13 NumPy 1.23 TorchVision 0.14 Matplotlib 3.7 CUDA 11.7 SciPy 1.10  下载: 导出CSV
下载: 导出CSV
表 2 不同模型各指标对比
Table 2 Comparison of various indicators of different models
模型 EN SD SF MI SCD VIF $ {{\text{Q}}^{{\text{AB/F}}}} $ SSIM Densefuse 6.93 45.49 8.21 1.78 1.27 0.91 0.41 0.96 SeAFusion 7.57 46.44 11.15 2.69 1.57 1.14 0.50 0.64 CDDFusion 7.18 44.96 13.28 3.12 1.55 0.94 0.62 0.94 本文模型 7.59 49.68 16.36 3.45 1.69 1.10 0.69 1.03
下载: 导出CSV
表 3 不同图像在矿井双模态人员数据集上的人员识别结果
Table 3 The personnel recognition results of different images on the mine bi-modal personnel data set
输入图像 准确率/% 召回率/% mAP@0.5/% 帧速率/(帧·s−1) 可见光 85.5 79.1 86.1 46.7 红外 91.6 86.5 90.3 53.4 融合 93.7 91.6 94.4 31.2
下载: 导出CSV
表 4 不同融合模型在矿井双模态人员数据集上的人员识别结果
Table 4 Personnel recognition results of different fusion models on the underground personnel data set
模型 准确率/% 召回率/% mAP@0.5/% 帧速率/(帧·s−1) Densefuse 89.5 80.9 88.2 30.1 SeAFusion 90.6 88.6 91.3 30.5 CDDFusion 83.5 79.6 82.6 29.8 本文模型 93.7 91.6 94.4 31.2
下载: 导出CSV
-
[1] 袁智,蒋庆友,庞振忠. 我国煤矿智能化综采开采技术装备应用现状与发展思考[J]. 煤炭科学技术,2024,52(9):189-198. DOI: 10.12438/cst.2024-1054 YUAN Zhi,JIANG Qingyou,PANG Zhenzhong. Application status and development thinking of intelligent mining technology and equipment in coal mines in China[J]. Coal Science and Technology,2024,52(9):189-198. DOI: 10.12438/cst.2024-1054
[2] 赵开林,保丹梅,张照伦,等. 浅谈煤炭开采过程中的开采技术与安全管理建议[J]. 内蒙古煤炭经济,2025(5):94-96. DOI: 10.3969/j.issn.1008-0155.2025.05.033 ZHAO Kailin,BAO Danmei,ZHANG Zhaolun,et al. Discussion on mining technology and safety management suggestions in coal mining process[J]. Inner Mongolia Coal Economy,2025(5):94-96. DOI: 10.3969/j.issn.1008-0155.2025.05.033
[3] 郝帅,安倍逸,付周兴,等. 基于小波变换和各向异性扩散的红外和可见光图像融合算法[J]. 西安科技大学学报,2022,42(1):184-190. HAO Shuai,AN Beiyi,FU Zhouxing,et al. Infrared and visible image fusion algorithm based on wavelet transform and anisotropic diffusion[J]. Journal of Xi'an University of Science and Technology,2022,42(1):184-190.
[4] MA Weihong,WANG Kun,LI Jiawei,et al. Infrared and visible image fusion technology and application:a review[J]. Sensors,2023,23(2). DOI: 10.3390/s23020599.
[5] YANG Kaixuan,XIANG Wei,CHEN Zhenshuai,et al. A review on infrared and visible image fusion algorithms based on neural networks[J]. Journal of Visual Communication and Image Representation,2024. DOI: 10.1016/j.jvcir.2024.104179.
[6] LIU Yu,CHEN Xun,CHENG Juan,et al. Infrared and visible image fusion with convolutional neural networks[J]. International Journal of Wavelets,Multiresolution and Information Processing,2018,16(3). DOI: 10.1142/S0219691318500182.
[7] HOU Ruichao,ZHOU Dongming,NIE Rencan,et al. VIF-net:an unsupervised framework for infrared and visible image fusion[J]. IEEE Transactions on Computational Imaging,2020,6:640-651. DOI: 10.1109/TCI.2020.2965304
[8] TANG Linfeng,XIANG Xinyu,ZHANG Hao,et al. DIVFusion:darkness-free infrared and visible image fusion[J]. Information Fusion,2023,91:477-493. DOI: 10.1016/j.inffus.2022.10.034
[9] FU Yu,WU Xiaojun. A dual-branch network for infrared and visible image fusion[C]. The 25th International Conference on Pattern Recognition,Milan,2021:10675-10680.
[10] MA Jiayi,YU Wei,LIANG Pengwei,et al. FusionGAN:a generative adversarial network for infrared and visible image fusion[J]. Information Fusion,2019,48:11-26. DOI: 10.1016/j.inffus.2018.09.004
[11] LI Bicao,LU Jiaxi,LIU Zhoufeng,et al. SBIT-Fuse:infrared and visible image fusion based on symmetrical bilateral interaction and transformer[J]. Infrared Physics & Technology,2024,138. DOI: 10.1016/j.infrared.2024.105269.
[12] KHAN M J,JIANG Shu,DING Weiping,et al. An infrared and visible image fusion using knowledge measures for intuitionistic fuzzy sets and Swin Transformer[J]. Information Sciences,2024,684. DOI: 10.1016/J.INS.2024.121291.
[13] JOBSON D J,RAHMAN Z,WOODELL G A. A multiscale retinex for bridging the gap between color images and the human observation of scenes[J]. IEEE Transactions on Image Processing,1997,6(7):965-976. DOI: 10.1109/83.597272
[14] JOBSON D J,RAHMAN Z,WOODELL G A. Properties and performance of a center/surround retinex[J]. IEEE Transactions on Image Processing,1997,6(3):451-462. DOI: 10.1109/83.557356
[15] WU Wenhui,WENG Jian,ZHANG Pingping,et al. URetinex-net:retinex-based deep unfolding network for low-light image enhancement[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition,New Orleans,2022:5901-5910.
[16] FU Huiyuan,ZHENG Wenkai,MENG Xiangyu,et al. You do not need additional priors or regularizers in retinex-based low-light image enhancement[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition,Vancouver,2023:18125-18134.
[17] RASHEED M T,GUO Guiyu,SHI Daming,et al. An empirical study on retinex methods for low-light image enhancement[J]. Remote Sensing,2022,14(18). DOI: 10.3390/RS14184608.
[18] LI Hui,WU Xiaojun. DenseFuse:a fusion approach to infrared and visible images[J]. IEEE Transactions on Image Processing,2019,28(5):2614-2623. DOI: 10.1109/TIP.2018.2887342
[19] TANG Linfeng,YUAN Jiteng,MA Jiayi. Image fusion in the loop of high-level vision tasks:A semantic-aware real-time infrared and visible image fusion network[J]. Information Fusion,2022,82. DOI: 10.1016/J.INFFUS.2021.12.004.
[20] ZHAO Zixiang,BAI Haowen,ZHANG Jiangshe,et al. CDDFuse:correlation-driven dual-branch feature decomposition for multi-modality image fusion[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition,Vancouver,2023:5906-5916.
[21] MA Jiayi,MA Yong,LI Chang. Infrared and visible image fusion methods and applications:a survey[J]. Information Fusion,2019,45:153-178. DOI: 10.1016/j.inffus.2018.02.004
[22] OSORIO F,VALLEJOS R,BARRAZA W,et al. Statistical estimation of the structural similarity index for image quality assessment[J]. Signal,Image and Video Processing,2022,16(4):1035-1042. DOI: 10.1007/s11760-021-02051-9
-
期刊类型引用(8)
1. 安龙辉,王满利,张长森. 基于轻量化YOLOv7的带式输送机输送带撕裂检测算法. 电子测量技术. 2025(01): 64-75 .  百度学术
百度学术
2. 安龙辉,王满利,张长森. 基于改进RT-DETR的井下输送带跑偏故障检测算法. 工矿自动化. 2025(03): 54-62 . 本站查看
3. 何泽珅,黄操军,许善祥,袁鑫宇,高学文,赵清. 基于改进YOLO v5的水稻害虫识别方法. 江苏农业科学. 2025(05): 223-230 . 百度学术
4. 南迪,纪宇. 煤矿井下带式输送机异常振动及对策分析. 中国机械. 2024(24): 100-103 . 百度学术
5. 梅晓虎,吕小强,雷萌. 基于Stair-YOLOv7-tiny的煤矿井下输送带异物检测. 工矿自动化. 2024(08): 99-104+111 . 本站查看
6. 韦明. 信息系统工程视域下基于YOLOv7的船舶检测研究. 自动化与仪器仪表. 2024(10): 79-83+88 . 百度学术
7. 范守俊,陈希琳,魏良跃,王青玉,张世源,董飞,雷少华. 一种煤矿井下多目标检测算法. 工矿自动化. 2024(12): 173-182 . 本站查看
8. 赵万里. 基于永磁同步直驱电机的煤矿井下带式输送机节能性能分析. 内蒙古石油化工. 2024(12): 53-55 . 百度学术
其他类型引用(3)












计量
- 文章访问数: 17
- HTML全文浏览量: 6
- PDF下载量: 3
- 被引次数: 11
