
Intelligent fault diagnosis of hoist bearing based on feature transfer learning
-
摘要: 针对提升机复杂实际工况导致的现有故障诊断方法准确率低和适应性弱的问题,提出了一种基于深度迁移特征选取(DTF)与平衡分布自适应(BDA)的提升机轴承智能故障诊断方法。对不同工况下的轴承故障信号进行时频分析,提取时域、频域统计特征,采用深度置信网络进行高维深度特征提取。为从高维深度特征集中选取出既有利于故障模式识别,也有利于跨域故障诊断的特征,采用基于ReliefF与域间差异的迁移特征选取(TFRD)方法对各特征的可迁移性进行量化评估,利用TFRD方法对各特征进行类别区分度和域不变性量化评估,采用ReliefF算法处理各类特征数据,获得表征类别区分度的权重值;计算同一特征在不同域间的最大均值差异,构建一种新的特征可迁移性量化指标。基于TFRD 方法,选取特征可迁移性大的深度特征构建特征子集,利用BDA对源域和目标域的特征子集进行分布适应,降低两者间的分布差异。采用源域特征集训练故障模式识别分类器,对目标域样本进行故障识别与分类。采用经典机器学习方法、深度学习方法和迁移学习方法构建了8种故障诊断模型,用于与提出的DTF−BDA故障诊断模型进行故障诊断准确率对比。结果表明:① DTF−BDA故障诊断模型能够取得明显优于其他对比模型的性能,最高故障诊断准确率可达100%。② TFRD方法能有效提高基于迁移学习方法构建的故障诊断模型的性能,与迁移成分分析和联合分布自适应相结合情况下的最高故障诊断准确率分别可达96.46%和97.67%。Abstract: The complex actual working conditions of the hoist causes the problems of low accuracy and weak adaptability of existing fault diagnosis methods. In order to solve these problems, an intelligent fault diagnosis method of hoist bearing based on deep transferable feature selection(DTF) and balance distribution adaptation(BDA) is proposed. The bearing fault signals under different working conditions are subjected to time-frequency analysis. The time and frequency domain's statistical characteristics are extracted. The high-dimensional depth characteristics are extracted by adopting a deep belief network. In order to select features that are beneficial to fault mode identification and cross-domain fault diagnosis from a high-dimensional depth feature set, the transferable feature selection based on ReliefF and differences between domains(TFRD) method is adopted. The method carries out the quantitative evaluation of the transitivity of each feature. The TFRD method carries out the quantitative evaluation on the class discrimination and domain invariance of each feature. The ReliefF algorithm processes various feature data to obtain weight values representing class discrimination. This method calculates the maximum mean discrepancy of the same feature between different domains, and constructs a new quantitative index of feature transferability. Based on the TFRD method, depth features with high feature transferability are selected to construct feature subsets. The balance distribution adaptation is applied to carry out distribution adaptation on the feature subsets of the source domain and the target domain, so as to reduce the distribution difference between the two domains. The source domain feature set is used to train the fault pattern identification classifier, and the target domain samples are used for fault identification and classification. Eight fault diagnosis models are constructed by using the classical machine learning method, deep learning method and transfer learning method. The models are used for comparing the fault diagnosis accuracy with the proposed DTF-BDA fault diagnosis model. The results show the following points. ① The DTF-BDA fault diagnosis model can achieve better performance than other models, and the highest fault diagnosis accuracy can reach 100%. ② The TFRD method can effectively improve the performance of the fault diagnosis model based on the transfer learning method. The highest fault diagnosis accuracy can reach 96.46% and 97.67% respectively when combined with the transfer component analysis and joint distribution adaptation.
-
Keywords:
- mine hoist /
- bearing fault /
- fault diagnosis /
- transfer learning /
- deep features /
- balance distribution adaptation
-
0. 引言
矿井提升机作为连接煤矿井下与地面的关键设备,担负着提升煤炭、矸石,下放材料,升降人员和设备的重要任务,其运行状况将直接影响煤矿生产。轴承作为提升机的关键部件之一,一旦发生异常状态,可能造成重大安全生产事故,因此,研究提升机轴承故障诊断方法具有重要意义[1-4]。
近年来,许多研究者对基于人工智能的提升机轴承故障诊断方法进行了大量研究。张梅等[4]提出了一种基于模糊故障树和贝叶斯网络的矿井提升机故障诊断方法,实现了故障类型的快速识别。王保勤[5]提出了一种基于一维卷积神经网络的提升机轴承故障诊断方法,利用卷积神经网络算法对振动信号进行提取与处理,对提升机发生的故障进行分类。刘旭等[6]设计了一种基于小波包与隐马尔可夫的矿井提升机主轴故障诊断模型,实现了矿井提升机主轴故障数据特征提取,并提高了抗干扰性,实现了较高的故障诊断准确率。马辉等[7]为提高提升机轴承故障诊断精度,提出了一种基于深度神经网络的双层次故障诊断系统,该系统利用滑动窗口重叠采样技术对数据进行增强,利用自编码器减少噪声影响,实现了诊断精度的提升。虽然上述基于人工智能的提升机轴承故障诊断方法取得了一定的效果,但缺乏足量有标签故障数据用于故障诊断模型训练,未充分考虑提升机在实际工作中常处于变工况,会导致相同故障数据间存在分布差异,使故障诊断准确率下降和适应性减弱。 针对上述问题,本文在深度学习方法基础上,融合近年来逐渐被研究者关注的迁移学习方法,提出了一种基于深度迁移特征选取(Deep Transferable Feature Selection,DTF)与平衡分布自适应(Balance Distribution Adaptation,BDA)的提升机轴承智能故障诊断方法。首先利用深度置信网络(Deep Belief Network,DBN)[8-9]对原始故障信号进行高维深度特征提取;其次利用基于ReliefF与域间差异的迁移特征选取(Transferable Feature Selection Based on ReliefF and Differences between Domains,TFRD)方法对各特征的可迁移性进行量化评估,选取可迁移特征构建深度特征子集;然后采用BDA处理源域和目标域特征集,降低域间分布差异;最后采用源域特征集训练故障模式识别分类器,对目标域样本进行故障识别与分类。
1. 提升机轴承故障诊断
1.1 故障诊断流程
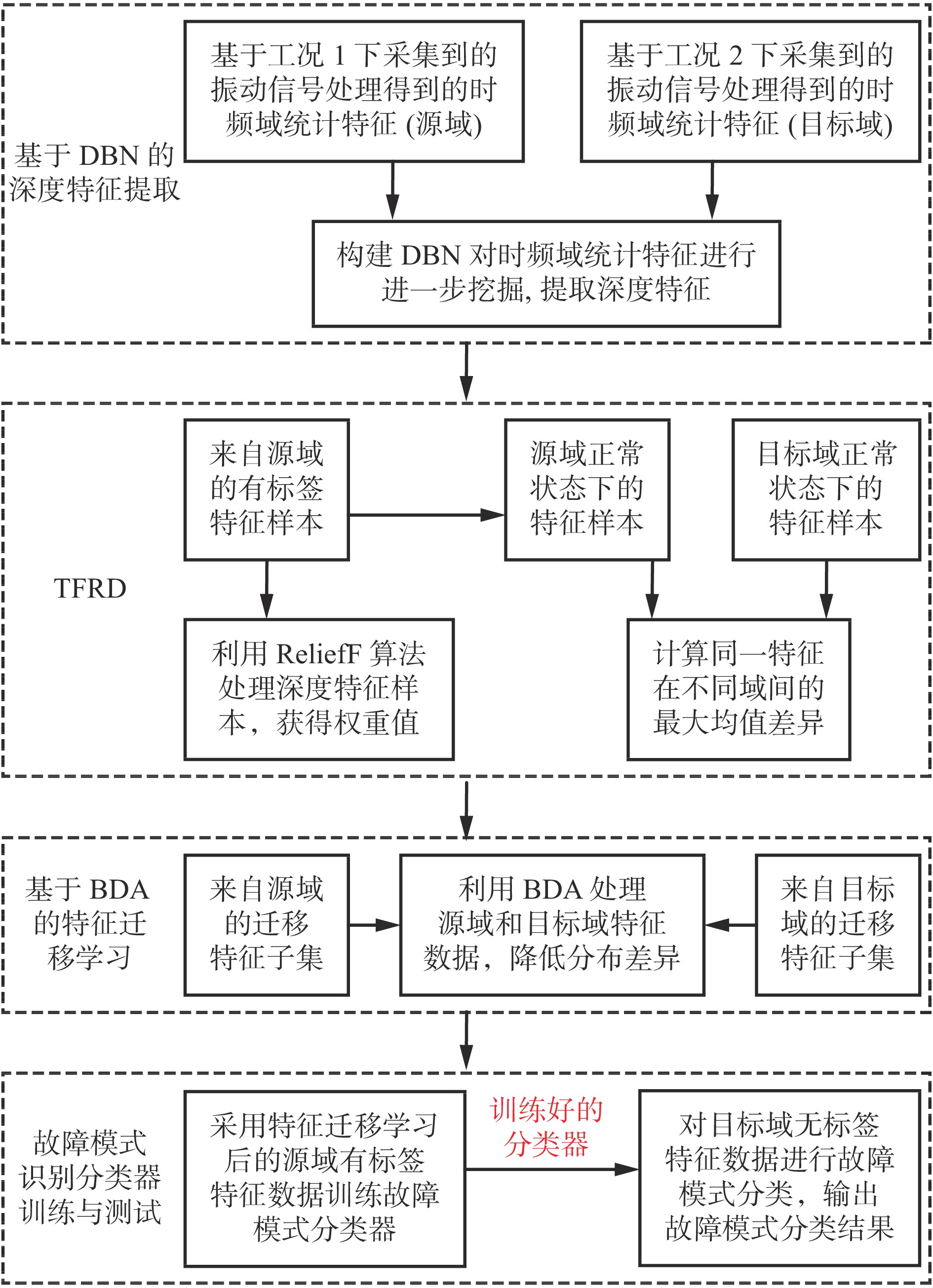
基于DTF−BDA的提升机轴承智能故障诊断流程如图1所示,具体步骤如下。
![]() 图 1 基于 DTF−BDA 的提升机轴承智能故障诊断流程Figure 1. Flow of hoist bearing intelligent fault diagnosis based on deep transferable feature selection and balance distribution adaptation
图 1 基于 DTF−BDA 的提升机轴承智能故障诊断流程Figure 1. Flow of hoist bearing intelligent fault diagnosis based on deep transferable feature selection and balance distribution adaptation(1) 对不同工况下的轴承故障信号进行时频分析,提取时域、频域统计特征,采用DBN提取深度特征。
(2) 为从高维深度特征集中选取出既有利于故障模式识别,也有利于跨域故障诊断的特征,采用TFRD方法对各深度特征进行类别区分度和域不变性量化评估。采用ReliefF算法处理各类特征数据,获得表征类别区分度的权重值;计算同一特征在不同域间的最大均值差异(Maximum Mean Discrepancy,MMD),表征其域不变性,构建一种新的特征可迁移性量化指标。
(3) 基于TFRD 方法,选取特征可迁移性大的深度特征构建特征子集,利用BDA对源域和目标域的特征子集进行分布适应,降低两者间的分布差异。
(4) 基于特征迁移学习后的源域有标签特征数据训练故障模式识别分类器,本文采用支持向量机(Support Vector Machine,SVM)作为模式识别分类器。将迁移学习后的目标域无标签特征数据输入训练好的分类器,输出故障模式分类结果。
1.2 基于DBN的深度特征提取
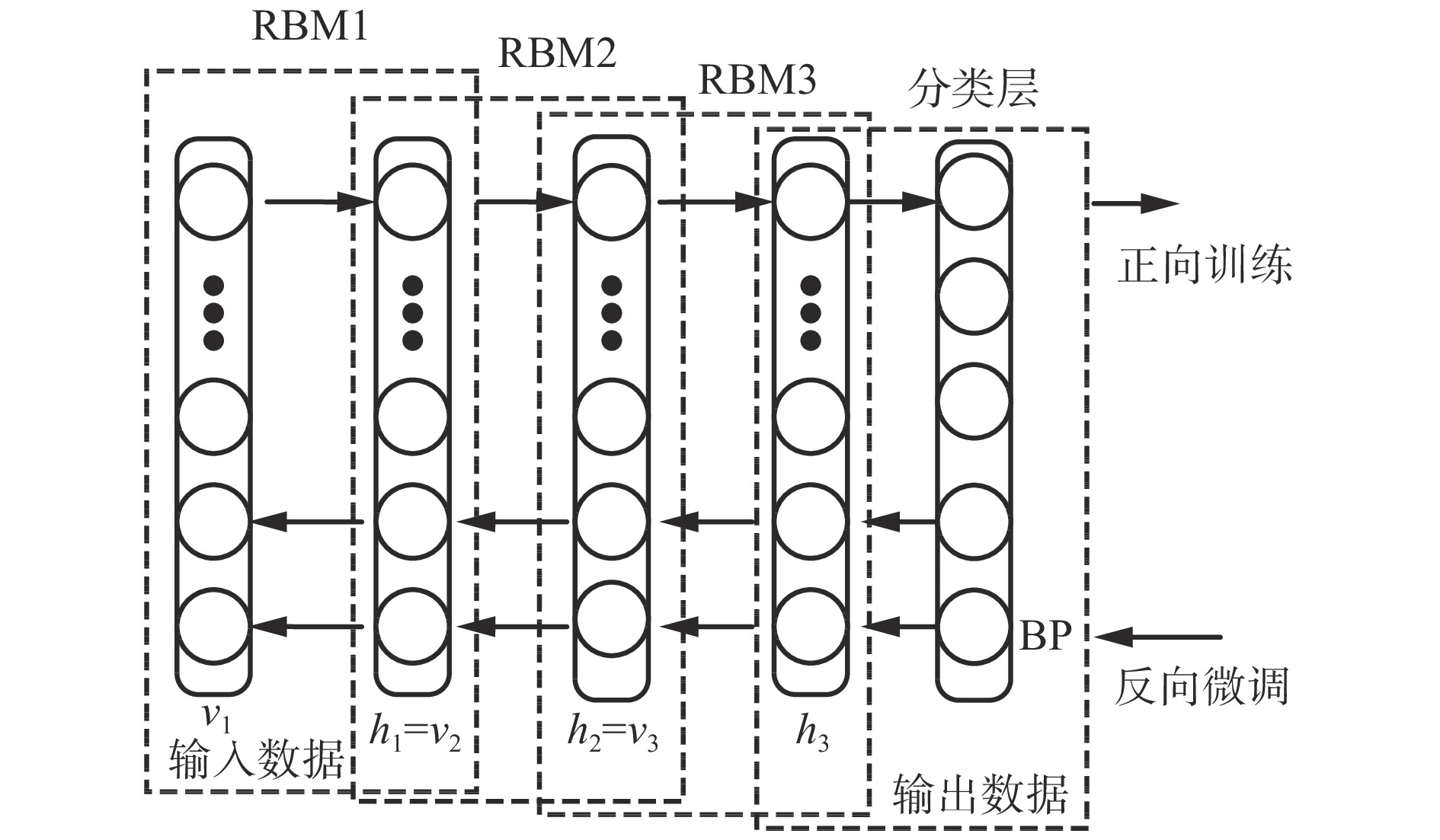
采用经典的DBN从时频域统计特征集中进一步挖掘深度特征。本文采用受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)和反向传播(Back Propagation,BP)网络堆叠而成的多隐含层神经网络构建深度特征提取网络,如图2所示,图中,
$ {v_1} $ ,$ {v_2} $ ,$ {v_3} $ 分别为RBM1,RBM2和RBM3的输入层数据,$ {h_1} $ ,$ {h_2} $ ,$ {h_3} $ 分别为RBM1,RBM2和RBM3的隐藏层数据[9]。本文将RBM3的隐性神经元作为深度特征,构建深度特征集,用于后续的特征可迁移性量化分析和特征迁移学习。![]() 图 2 基于3层RBM构建的DBNFigure 2. Deep belief network based on three layer restricted Boltzmann machine
图 2 基于3层RBM构建的DBNFigure 2. Deep belief network based on three layer restricted Boltzmann machine1.3 TFRD
虽然深度学习具有强大的隐藏特征挖掘能力,但其挖掘出来的特征并非全部都具有良好的故障模式识别和分类能力,尤其在变工况情况下,相同故障数据间存在分布差异,导致大多数基于深度学习的故障诊断模型会出现诊断效果不佳且泛化能力较弱的结果。因此,本文通过对深度特征的可迁移性进行量化分析,提出了TFRD方法,选取既有利于故障模式识别,也有利于迁移学习的深度特征,用于特征迁移学习和故障诊断模型训练。TFRD方法从特征的类别区分度和特征域不变性2个方面对深度特征的可迁移性进行量化评估。
1.3.1 特征的类别区分度量化
ReliefF算法作为经典的特征评价方法,能够根据各个特征与类别的相关性赋予特征不同的权重,实现特征类别区分度的量化[10]。在TFRD方法中,采用ReliefF算法对各深度特征数据进行处理,获取表征类别区分度的权重值。
给定包含P种特征样本源域特征集
${{\boldsymbol{F}}_{\rm{S}}}= [ {\bar f_1^{\rm{s}}}\;{\bar f_2^{\rm{s}}}\; \cdots \;{\bar f_P^{\rm{s}}}]^{{\rm{T}}}$ ,共有K种故障类别数据,其中,第p($p \in [1,P]$ )个特征为$$ {\bar {\boldsymbol{f}}_p^{\rm{s}}}{\text{ = }}\left[ {\begin{array}{*{20}{c}} {f_{11}^p}&{f_{12}^p}& \cdots &{f_{1N}^p} \\ {f_{21}^p}&{f_{22}^p}& \cdots &{f_{2N}^p} \\ \vdots & \vdots & & \vdots \\ {f_{K1}^p}&{f_{K2}^p}& \cdots &{f_{KN}^p} \end{array}} \right] $$ (1) 式中
$f_{kn}^p$ ($k \in [1,K],n \in [1,N] $ ,N为各种特征样本数)为第k种故障类别的第n个特征样本。基于ReliefF算法,获得P种特征的权重值,构成类别区分度权重值序列:
$$ {L_W} = \{ w(1),w(2), \cdots ,w(P)\} $$ (2) 式中
$ w(p) $ 为第p个特征经ReliefF算法得到的权重值,当特征的权重值越大,其类别区分度越好,则越有益于故障模式识别与分类。1.3.2 特征域不变性量化
MMD目前被广泛用于迁移学习中度量数据间分布差异[11-12]。因此,本文采用MMD来计算同一特征在不同域下的分布差异。给定概率分布不同的源域样本
${{{D}}_{\rm{S}}}{\text{ = \{ }}{x_1},{x_2}, \cdots ,{x_{{n_{\rm{S}}}}}{\text{\} }}$ 和目标域样本${{{D}}_{\rm{T}}}{\text{ = \{ }}{x_{{n_{\rm{S}}} + 1}}, {x_{{n_{\rm{S}}} + 2}}, \cdots ,{x_{{n_{\rm{S}}} + {n_{\rm{T}}}}}{\text{\} }}$ ,${n_{\rm{S}}}$ 与${n_{\rm{T}}}$ 分别为源域和目标域样本数。$ {{{D}}_{\rm{S}}} $ 和$ {{{D}}_{\rm{T}}} $ 间边缘概率分布的分布差异为$$ B = \left\| {\frac{1}{{{n_{\rm{S}}}}}\sum\limits_{{x_i} \in {{{D}}_{\rm{S}}}} {\phi ({x_i}) - \frac{1}{{{n_{\rm{T}}}}}\sum\limits_{{x_j} \in {{{D}}_{\rm{T}}}} {\phi ({x_j})} } } \right\|_{{H}}^2 $$ (3) 式中:
$x_i $ ,$x_j $ 分别为第i个源域样本和第j个目标域样本,$i \in [1,{n_{\rm{S}}}],j \in [{n_{\rm{S}}} + 1,{n_{\rm{S}}} + {n_{\rm{T}}}]$ ;H为再生核Hilbert空间;$ \phi (\cdot)$ 为H中的非线性映射函数。本文采用轴承正常状态下的源域特征集和目标域特征集样本计算特征的分布差异,可获得各特征的分布差异序列:
$$ {J_{\rm{M}}} = \{ m(1),m(2), \cdots ,m(P)\} $$ (4) 式中
$ m(p) $ 为第p个特征在源域和目标域间的分布差异。当分布差异越大,表明该特征在不同工况下数据分布差异越大,因此,特征在不同域下样本的分布差异越小,其域不变性越好,越有利于特征迁移学习。
1.3.3 特征可迁移性量化指标构建
基于表征特征类别区分度的权重值和表征域不变性的分布差异,构建一种新的特征可迁移性量化指标−类别权重与最大均值差异比(Ratio of Class Weight and Maximum Mean Discrepancy,RCM),表达式如下:
$$ r(p){\text{ = }}\frac{{w(p)}}{{m(p)}} $$ (5) 对于P种特征,基于式(5),可获得对应的RCM序列:
$$ {O_{\rm{R}}} = \{ r(1),r(2), \cdots ,r(P)\} $$ (6) 当特征的RCM值越大,其类别区分度和域不变性的综合性能越好,即可迁移性越好,越有利于特征迁移学习。因此,本文将计算各深度特征的RCM序列,并对其降序排列,选取排序靠前的深度特征构建新的可迁移特征集,用于后续的特征迁移学习和故障诊断分类器的训练。
1.4 基于BDA的特征迁移学习
BDA是由Wang Jindong等[13]于2017年提出的一种新的特征迁移学习方法,用于不同域数据之间的分布适应,降低分布差异。BDA旨在解决经典的特征迁移学习方法的迁移成分分析(Transfer Component Analysis,TCA)和联合分布自适应(Joint Distribution Adaptation,JDA)在进行不同域数据间分布适应时,边缘概率分布和条件概率分布存在的问题。为此,BDA引入了一种动态平衡因子,对边缘概率分布和条件概率分布的自适应进行动态调整,进而提高不同域间分布自适应的效果。
给定2个边缘概率分布和条件概率分布均不相等的域数据,有标签源域
${{{D}}_{{\text{S\_Class}}}}{\text{ = \{ }}({x_1},{c_1}),({x_2},{c_2}), \cdots , ({x_{{n_{\rm{S}}}}},{c_{{n_{\rm{S}}}}}){\text{\} }}$ (${c_i}$ 为对应样本${x_i}$ 的类别标签)和无标签目标域${{{D}}_{\text{T}}}{\text{ = \{ }}{x_{{n_{\rm{S}}}{\text{ + }}1}},{x_{{n_{\rm{S}}}{\text{ + }}2}}, \cdots ,{x_{{n_{\rm{S}}} + {n_{\rm{T}}}}}{\text{\} }}$ 。BDA的优化目标是通过源域有标签样本和目标域无标签样本学习得到一个映射矩阵A,使得映射变换后的源域和目标域间分布差异最小:$$ \left\{ \begin{array}{l} \mathop {{\text{min}}}\limits_{\boldsymbol{A}} {\left( {\mu Y({{{D}}_{{\text{S\_Class}}}}, {{{D}}_{\text{T}}}){{ + (1 - }}\mu {\text{)}}{Y_{{\rm{Conditional}}}}({{{D}}_{{\text{S\_Class}}}}, {{{D}}_{\text{T}}})} \right)_{{H}}}{{ + \lambda }}\left\| {\boldsymbol{A}} \right\|_{{F}}^{\text{2}} \\ {\text{s}}{\text{.t}}{\text{.}}\;\;{{\boldsymbol{A}}^{\mathbf{T}}}{\boldsymbol{X}}{{\boldsymbol{H}}_0}{{\boldsymbol{X}}^{\mathbf{T}}}{\boldsymbol{A}}={\boldsymbol{I}} \end{array} \right. $$ (7) 式中:
$ \mu $ 为平衡因子,$ \mu \in [0,1] $ ,根据人工经验确定数值,实现动态调整对源域和目标域的边缘概率分布和条件概率分布的适应;$ {Y_{}}({{{D}}_{{\text{S\_Class}}}},{{{D}}_{\text{T}}}) $ 和${Y_{{\rm{Conditional}}}} ({{{D}}_{{\text{S\_Class}}}},{{{D}}_{\text{T}}})$ 分别为经映射矩阵A变换后的源域和目标域数据间的边缘概率分布距离和条件概率分布距离,采用的度量方法为经典的MMD距离;$\lambda \left\| {\boldsymbol{A}} \right\|_{{F}}^{\text{2}}$ 为Frobenius规范正则项,$\lambda$ 为权衡参数;X为源域和目标域样本矩阵;$ {{\boldsymbol{H}}_0} $ 为中心矩阵;I为单位矩阵。$$ \begin{split} Y({{{D}}_{\text{S\_Class}}},{{{D}}_{\text{T}}}) =& \left\| {\frac{1}{{n_{\text{S}}^{}}}\sum\limits_{i = 1}^{{n_{\rm{S}}}} {{{\boldsymbol{A}}^{\text{T}}}{{{x}}_i} - \frac{1}{{n_{\text{T}}^{}}}\sum\limits_{j = {n_{\rm{S}}} + 1}^{{n_{\rm{S}}} + {n_{\rm{T}}}} {{{\boldsymbol{A}}^{\text{T}}}{{{x}}_j}} } } \right\|_{{H}}^2 = \\ & {\rm{tr}}({{\boldsymbol{A}}^{\text{T}}}{\boldsymbol{X}}{{\boldsymbol{M}}_{\bf{0}}}{{\boldsymbol{X}}^{\text{T}}}{\boldsymbol{A}}) \end{split} $$ (8) $${\{{\boldsymbol{M}}_{\bf{0}}\}}_{ij}{\rm{ = }}\left\{ {\begin{array}{*{20}{l}} {\dfrac{1}{{{n_{\rm{S}}}{n_{\rm{S}}}}}}&{{x_i},{x_j} \in {{D}}_{\rm{S}}^{}}\\ {\dfrac{1}{{{n_{\rm{T}}}{n_{\rm{T}}}}}}&{{x_i},{x_j} \in {{D}}_{\rm{T}}^{}}\\ {\dfrac{{ - 1}}{{{n_{\rm{S}}}{n_{\rm{T}}}}}}&{其他} \end{array}} \right. $$ (9) $$ \begin{split} {Y_{{\rm{Conditional}}}}({{{D}}_{\text{S\_Class}}},{{{D}}_{\text{T}}}) = & \sum\limits_{c = 1}^Z {\left\| {\frac{1}{{n_{\text{S}}^{(c)}}} \sum\limits_{{x_i} \in {{D}}_{\text{S}}^{{{(c)}}}} {{{\boldsymbol{A}}^{\text{T}}}{{{x}}_i} - \frac{1}{{n_{\text{T}}^{(c)}}} \sum\limits_{{x_j} \in {{D}}_{\text{T}}^{{{(c)}}}} {{{\boldsymbol{A}}^{\text{T}}}{{{x}}_j}} } } \right\|_{{H}}^2} = \\ & \sum\limits_{c = 1}^Z {{\rm{tr}}({{\boldsymbol{A}}^{\text{T}}}{\boldsymbol{X}}{{\boldsymbol{M}}_c}{{\boldsymbol{X}}^{\text{T}}}{\boldsymbol{A}})} \\[-15pt] \end{split} $$ (10) $${\{{{\boldsymbol{M}}_{\boldsymbol{c}}}\}_{ij}}{\rm{ = }}\left\{ {\begin{array}{*{20}{l}} {\dfrac{1}{{n_{\rm{S}}^{(c)}n_{\rm{S}}^{(c)}}}}&{{x_i},{x_j} \in {{D}}_{\rm{S}}^{({{c}})}}\\ {\dfrac{1}{{n_{\rm{T}}^{(c)}n_{\rm{T}}^{(c)}}}}&{{x_i},{x_j} \in {{D}}_{\rm{T}}^{({{c}})}}\\ {\dfrac{{ - 1}}{{n_{\rm{S}}^{(c)}n_{\rm{T}}^{(c)}}}}&\begin{array}{l} {x_i} \in {{D}}_{\rm{S}}^{({{c}})},{x_j} \in {{D}}_{\rm{T}}^{({{c}})}\\ {x_i} \in {{D}}_{\rm{T}}^{({{c}})},{x_j} \in {{D}}_{\rm{S}}^{({{c}})} \end{array}\\ 0&{其他} \end{array}} \right. $$ (11) 式中:
$ c \in [1,Z] $ ,Z为目标域样本类别;$ {{D}}_{\text{S}}^{{{(c)}}} $ 为第c类的源域样本;$ {{D}}_{\text{T}}^{{{(c)}}} $ 为第c类的目标域样本;$ n_{\text{S}}^{{{(c)}}} $ 为第c类的源域样本数;$ n_{\text{T}}^{{{(c)}}} $ 为第c类的目标域样本数。2. 实验验证
2.1 实验数据与任务设置
为验证基于DTF−BDA的提升机轴承智能故障诊断方法的有效性与优越性,采用美国凯斯西储大学轴承故障数据集[4,5,8,13]开展不同工况下数据故障诊断的实验分析。实验台如图3所示,数据集见表1。本文采用4种工况下的12种轴承状态数据开展实验验证,设置4个域数据:电动机转速为1 797 r/min时的12种状态数据为1个域数据(域1),电动机转速分别为1 772,1 750,1 730 r/min时的12种状态数据为另外3个域数据(域2−域4)。每个域数据中包含随机抽取的720个样本,每个样本由2 000个连续数据点构成。
表 1 凯斯西储大学轴承故障数据集Table 1. Bearing fault dataset of Case Western Reserve University轴承状态 缺陷尺
寸/cm不同轴承工况下的样本数 类别标签 域1 域2 域3 域4 正常状态 0 60 60 60 60 1 滚动体缺陷 0.017 78 60 60 60 60 2 0.035 56 60 60 60 60 3 0.053 34 60 60 60 60 4 0.071 12 60 60 60 60 5 内圈缺陷 0.017 78 60 60 60 60 6 0.035 56 60 60 60 60 7 0.053 34 60 60 60 60 8 0.071 12 60 60 60 60 9 外圈缺陷 0.017 78 60 60 60 60 10 0.035 56 60 60 60 60 11 0.053 34 60 60 60 60 12 由于实际工业场景下的提升机轴承运行状态常为变工况,与训练故障诊断模型的样本所处工况不同,因此,实验分析共设置4个故障诊断任务。任务1:电动机转速为1 750 r/min时的数据作为源域(训练样本),电动机转速为1 730 r/min时的数据作为目标域(测试样本);任务2:电动机转速为1 730 r/min时的数据作为源域,电动机转速为1 750 r/min时的数据作为目标域;任务3:电动机转速为1 772 r/min时的数据作为源域,电动机转速为1 750 r/min时的数据作为目标域;任务4:电动机转速为1 750 r/min时的数据作为源域,电动机转速为1 772 r/min时的数据作为目标域。在该4个任务下进行故障诊断对比实验。
2.2 实验结果分析
根据图1所示的基于DTF−BDA的提升机轴承智能故障诊断流程构建对应的DTF−BDA故障诊断模型。首先,将原始轴承振动信号经小波包变换(Wavelet Packet Transform, WPT)4层分解后,对终端16个节点进行单支重构,提取重构信号的Hilbert包络谱和边际谱,再计算11种统计参数(能量、偏度、波峰因子、能量熵、平均值、极差、峰度、标准差、形状因子、脉冲因子和纬度因子)[9,14-15],共获得352个特征,即原始时频特征集。将352个时频特征输入DBN进行深度特征提取。激活函数选用sigmoid函数,隐含层神经元个数设置为500,300,200,学习率为0.01。本文共提取200个深度特征构建深度特征集。其次,采用TFRD方法对深度特征集中各特征进行可迁移性量化,获得RCM序列,并对其降序排列,选取RCM值大的深度特征构建特征子集。然后,使用BDA对来自源域有标签和目标域无标签的特征子集进行分布适应,减少分布差异。最后,利用BDA处理后的源域特征集训练故障模式识别分类器(SVM),将已训练好的SVM分类器用于目标域无标签样本的故障模式识别与分类。
本文采用经典机器学习方法、深度学习方法和迁移学习方法构建了8种故障诊断模型,分别为FS(Feature Set,特征集)−SVM,FS−KNN(k-Nearest Neighbor,K−最近邻),FS−DBN−Softmax(Soft Version of Max),FS−DAE(Deep Auto-Encoder,深度自编码器)−Softmax,FS−TCA−SVM,FS−JDA−SVM,FS−TFRD−TCA和FS−TFRD−JDA,用于与DTF−BDA故障诊断模型进行对比。FS−SVM模型是将原始数据经时频方法处理后提取的时频特征集直接输入SVM进行模型训练和测试。FS−KNN模型是将原始数据经时频方法处理后提取的时频特征集直接输入KNN进行模型训练和测试。FS−DBN−Softmax模型是将时频特征经DBN做深度特征提取,再输入Softmax模型进行模型训练和测试。FS−DAE−Softmax模型是将时频特征经DAE做深度特征提取,再输入Softmax模型进行模型训练和测试。FS−TCA−SVM模型是将时频特征集经TFRD特征选取后输入TCA进行特征迁移学习,再采用SVM分类器进行故障模式识别与分类。FS−JDA−SVM模型是将时频特征集经TFRD特征选取后输入JDA进行特征迁移学习,再采用SVM分类器进行故障模式识别与分类。FS−TFRD−TCA模型是将时频特征集经TFRD特征选取后输入TCA进行特征迁移学习,再采用SVM分类器进行故障模式识别与分类。FS−TFRD−JDA模型是将时频特征集经TFRD特征选取后输入TCA进行特征迁移学习,再采用SVM分类器进行故障模式识别与分类。
9种模型在不同工况下故障诊断准确率对比结果见表2,FS−TFRD−TCA,FS−TFRD−JDA和DTF−BDA模型的故障诊断实验结果见表3。
表 2 不同故障诊断模型在4个任务下的故障诊断准确率对比Table 2. Comparison of fault diagnosis accuracy of different fault diagnosis models under 4 fault diagnosis tasks% 故障模型 故障诊断准确率 任务1 任务2 任务3 任务4 FS−SVM 95.00 73.13 87.50 78.96 FS−KNN 96.88 82.50 90.13 85.00 FS−DBN−Softmax 85.21 85.63 82.50 80.13 FS−DAE−Softmax 59.17 53.96 53.33 51.67 FS−TCA−SVM 77.50 78.75 72.67 76.13 FS−JDA−SVM 83.33 81.67 79.17 77.50 FS−TFRD−TCA 96.88 96.67 95.42 95.00 FS−TFRD−JDA 98.13 98.96 97.71 97.08 DTF−BDA 100.00 100.00 100.00 100.00 表 3 不同故障诊断模型实验结果Table 3. Experimental results of different fault diagnosis models可迁移特征
选取数故障诊断准确率/% FS−TFRD−TCA FS−TFRD−JDA DTF−BDA 任务1 任务2 任务3 任务4 任务1 任务2 任务3 任务4 任务1 任务2 任务3 任务4 20 66.04 67.08 60.67 63.17 68.67 65.83 61.67 60.50 71.33 69.83 70.33 68.17 40 71.67 73.13 66.83 68.50 74.50 73.17 72.50 71.33 77.50 76.67 75.00 74.83 60 79.79 81.88 76.00 78.67 80.00 81.67 80.33 79.29 83.33 82.67 82.67 82.50 80 83.54 86.04 82.67 84.50 89.83 87.00 87.50 88.13 91.67 92.00 92.50 93.13 100 88.96 88.33 84.83 86.50 95.17 96.83 94.83 94.50 99.50 99.17 99.67 99.50 120 95.00 95.63 91.33 89.17 97.67 96.00 97.50 96.33 98.33 98.17 99.13 98.67 140 96.46 96.00 96.33 95.50 95.67 95.17 94.83 94.33 96.67 96.50 97.67 96.46 160 89.38 92.67 86.50 84.83 88.00 86.83 89.33 87.00 94.83 93.33 95.50 94.83 180 80.83 82.50 76.33 82.67 84.33 82.50 86.17 84.67 92.17 91.50 93.13 92.67 200 77.50 78.75 72.67 76.13 83.33 81.67 79.17 77.50 88.75 86.46 83.75 82.08 (1) 从表2可看出:在4个故障诊断任务下,DTF−BDA模型的故障诊断准确率明显高于其他模型,最高可达100%,验证了基于DTF−BDA的提升机轴承智能故障诊断方法的有效性。
(2) 从表2还可看出:仅采用经典机器学习方法SVM,KNN和经典深度学习方法DBN和DAE构建的故障诊断模型用于不同工况下的故障诊断,其故障诊断性能较低,FS−SVM和FS−KNN模型仅任务1的故障诊断准确率可达95%以上,其余任务的故障诊断准确率均明显降低;FS−DBN−Softmax和FS−DAE−Softmax模型的故障诊断准确率更低,与DTF−BDA模型的故障诊断准确率差距较大。FS−TFRD−TCA和FS−TFRD−JDA模型的最高故障诊断准确率均能达到95%以上,明显高于FS−TCA−SVM和FS−JDA−SVM模型,表明由于TFRD方法的引入,使故障诊断准确率得到了明显提高。
(3) 从表3可看出:选取不同数量的可迁移特征时,对模型故障诊断准确率有明显影响:FS−TFRD−TCA模型在选取140个可迁移特征时,任务1能够达到96.46%的故障诊断准确率,比200个可迁移特征时(即未使用TFRD方法,此时与FS−TCA−SVM模型等效)的故障诊断准确率高18.96%;FS−TFRD−JDA和DTF−BDA模型也有类似的规律。基于表2中FS−TCA−SVM,FS−JDA−SVM,FS−TFRD−TCA和FS−TFRD−JDA模型的结果对比和表3结果,表明了TFRD能够明显提升基于迁移学习方法的故障诊断模型在不同工况下的故障诊断性能。
(4) BDA相比于TCA和JDA在提升故障诊断模型在不同工况下的故障诊断性能上更具优势。根据表3中当可迁移特征数为200时,3个模型在4个任务下的故障诊断准确率可知,DTF−BDA模型在任务1−4下的故障诊断准确率分别为88.75%,86.46%,83.75%和82.08%,均明显高于FS−TFRD−TCA和FS−TFRD−JDA模型的准确率,表明BDA方法的故障诊断性能优于TCA和JDA。
3. 结论
(1) 提出了一种基于DTF−BDA的提升机轴承智能故障诊断方法。首先利用DBN对原始故障信号进行高维深度特征提取;其次利用TFRD方法对各特征的可迁移性进行量化评估,选取可迁移特征构建深度特征子集;然后采用BDA处理源域和目标域特征集,降低域间分布差异;最后采用源域特征集训练故障模式识别分类器,对目标域样本进行故障识别与分类。
(2) 为验证基于DTF−BDA的提升机轴承智能故障诊断方法的有效性和TFRD与BDA方法的优势,采用美国凯斯西储大学轴承故障数据集开展了故障诊断对比实验分析。实验结果表明:① DTF−BDA在获得理想的故障诊断准确率方面优势突出,最高故障诊断准确率达100%。② TFRD在提升迁移学习方法的故障诊断性能方面具有明显优势,FS−TFRD−TCA和FS−TFRD−JDA模型最高故障诊断准确率分别可达96.46%和97.67%。③ BDA相比于TCA和JDA,在提升故障诊断模型在不同工况下的故障诊断性能上更具优势,DTF−BDA模型在使用所有200个可迁移特征时在任务1−4的故障诊断准确率分别为88.75%,86.46%,83.75%和82.08%,均明显高于FS−TFRD−TCA和FS−TFRD−JDA模型的故障诊断准确率。
【编者按】机械设备是矿山生产运行的基础,其结构复杂,工况环境多变。随着智慧矿山的提出,煤矿对于矿山机械设备的安全性、可靠性及经济性等方面提出了更高的要求,加强矿山机械设备的状态监测与故障诊断成为矿山机械设备安全、高效和稳定运行的基础条件。为进一步总结、交流我国矿山机械设备健康状态监测与故障诊断技术最新进展,《工矿自动化》特邀安徽理工大学郭永存教授担任专题客座主编,胡坤、姜阔胜和马天兵教授担任客座副主编,于2022年第9期策划出版“矿山机械设备健康状态监测与故障诊断技术及应用”专题。在专题刊出之际,衷心感谢各位专家学者的大力支持! -
![]()
图 1 基于 DTF−BDA 的提升机轴承智能故障诊断流程
Figure 1. Flow of hoist bearing intelligent fault diagnosis based on deep transferable feature selection and balance distribution adaptation
![]()
图 2 基于3层RBM构建的DBN
Figure 2. Deep belief network based on three layer restricted Boltzmann machine
表 1 凯斯西储大学轴承故障数据集
Table 1 Bearing fault dataset of Case Western Reserve University
轴承状态 缺陷尺
寸/cm不同轴承工况下的样本数 类别标签 域1 域2 域3 域4 正常状态 0 60 60 60 60 1 滚动体缺陷 0.017 78 60 60 60 60 2 0.035 56 60 60 60 60 3 0.053 34 60 60 60 60 4 0.071 12 60 60 60 60 5 内圈缺陷 0.017 78 60 60 60 60 6 0.035 56 60 60 60 60 7 0.053 34 60 60 60 60 8 0.071 12 60 60 60 60 9 外圈缺陷 0.017 78 60 60 60 60 10 0.035 56 60 60 60 60 11 0.053 34 60 60 60 60 12  下载: 导出CSV
下载: 导出CSV
表 2 不同故障诊断模型在4个任务下的故障诊断准确率对比
Table 2 Comparison of fault diagnosis accuracy of different fault diagnosis models under 4 fault diagnosis tasks
% 故障模型 故障诊断准确率 任务1 任务2 任务3 任务4 FS−SVM 95.00 73.13 87.50 78.96 FS−KNN 96.88 82.50 90.13 85.00 FS−DBN−Softmax 85.21 85.63 82.50 80.13 FS−DAE−Softmax 59.17 53.96 53.33 51.67 FS−TCA−SVM 77.50 78.75 72.67 76.13 FS−JDA−SVM 83.33 81.67 79.17 77.50 FS−TFRD−TCA 96.88 96.67 95.42 95.00 FS−TFRD−JDA 98.13 98.96 97.71 97.08 DTF−BDA 100.00 100.00 100.00 100.00
下载: 导出CSV
表 3 不同故障诊断模型实验结果
Table 3 Experimental results of different fault diagnosis models
可迁移特征
选取数故障诊断准确率/% FS−TFRD−TCA FS−TFRD−JDA DTF−BDA 任务1 任务2 任务3 任务4 任务1 任务2 任务3 任务4 任务1 任务2 任务3 任务4 20 66.04 67.08 60.67 63.17 68.67 65.83 61.67 60.50 71.33 69.83 70.33 68.17 40 71.67 73.13 66.83 68.50 74.50 73.17 72.50 71.33 77.50 76.67 75.00 74.83 60 79.79 81.88 76.00 78.67 80.00 81.67 80.33 79.29 83.33 82.67 82.67 82.50 80 83.54 86.04 82.67 84.50 89.83 87.00 87.50 88.13 91.67 92.00 92.50 93.13 100 88.96 88.33 84.83 86.50 95.17 96.83 94.83 94.50 99.50 99.17 99.67 99.50 120 95.00 95.63 91.33 89.17 97.67 96.00 97.50 96.33 98.33 98.17 99.13 98.67 140 96.46 96.00 96.33 95.50 95.67 95.17 94.83 94.33 96.67 96.50 97.67 96.46 160 89.38 92.67 86.50 84.83 88.00 86.83 89.33 87.00 94.83 93.33 95.50 94.83 180 80.83 82.50 76.33 82.67 84.33 82.50 86.17 84.67 92.17 91.50 93.13 92.67 200 77.50 78.75 72.67 76.13 83.33 81.67 79.17 77.50 88.75 86.46 83.75 82.08
下载: 导出CSV
-
[1] 李娟莉,闫方元,梁思羽,等. 基于卷积神经网络的矿井提升机制动系统故障诊断方法[J]. 太原理工大学学报,2022,53(3):524-530. LI Juanli,YAN Fangyuan,LIANG Siyu,et al. Fault diagnosis method of mine hoist braking system based on convolutional neural network[J]. Journal of Taiyuan University of Technology,2022,53(3):524-530.
[2] 康守强,刘旺辉,王玉静,等. 基于深度在线迁移的变负载下滚动轴承故障诊断方法[J]. 控制与决策,2022,37(6):1521-1530. KANG Shouqiang,LIU Wanghui,WANG Yujing,et al. Fault diagnosis method of rolling bearing under varying loads based on deep online transfer[J]. Control and Decision,2022,37(6):1521-1530.
[3] 丁恩杰,俞啸,廖玉波,等. 基于物联网的矿山机械设备状态智能感知与诊断[J]. 煤炭学报,2020,45(6):2308-2319. DOI: 10.13225/j.cnki.jccs.zn20.0340 DING Enjie,YU Xiao,LIAO Yubo,et al. Key technology of mine equipment state perception and online diagnosis under Internet of things[J]. Journal of China Coal Society,2020,45(6):2308-2319. DOI: 10.13225/j.cnki.jccs.zn20.0340
[4] 张梅,许桃,孙辉煌,等. 基于模糊故障树和贝叶斯网络的矿井提升机故障诊断[J]. 工矿自动化,2020,46(11):1-5,45. DOI: 10.13272/j.issn.1671-251x.17562 ZHANG Mei,XU Tao,SUN Huihuang,et al. Fault diagnosis of mine hoist based on fuzzy fault tree and Bayesian network[J]. Industry and Mine Automation,2020,46(11):1-5,45. DOI: 10.13272/j.issn.1671-251x.17562
[5] 王保勤. 基于一维卷积神经网络的提升机轴承故障诊断方法研究[J]. 矿山机械,2021,49(9):29-34. DOI: 10.3969/j.issn.1001-3954.2021.09.007 WANG Baoqin. Research on fault diagnosis method for hoist bearing based on one-dimensional convolutional neural network[J]. Mining & Processing Equipment,2021,49(9):29-34. DOI: 10.3969/j.issn.1001-3954.2021.09.007
[6] 刘旭,朱宗玖,杨明亮. 基于小波包与隐马尔可夫的矿井提升机主轴故障诊断[J]. 煤炭技术,2022,41(1):214-216. LIU Xu,ZHU Zongjiu,YANG Mingliang. Fault diagnosis of mine hoist spindle based on wavelet packet and HMM[J]. Coal Technology,2022,41(1):214-216.
[7] 马辉,车迪,牛强,等. 基于深度神经网络的提升机轴承故障诊断研究[J]. 计算机工程与应用,2019,55(16):123-129,184. DOI: 10.3778/j.issn.1002-8331.1903-0010 MA Hui,CHE Di,NIU Qiang,et al. Research on fault diagnosis of hoisting bearing based on deep neural network[J]. Computer Engineering and Applications,2019,55(16):123-129,184. DOI: 10.3778/j.issn.1002-8331.1903-0010
[8] 俞啸,范春旸,董飞,等. 基于EMD与深度信念网络的滚动轴承故障特征分析与诊断方法[J]. 机械传动,2018,42(6):157-163. DOI: 10.16578/j.issn.1004.2539.2018.06.033 YU Xiao,FAN Chunyang,DONG Fei,et al. Fault feature analysis and diagnosis method of rolling bearing based on empirical mode decomposition and deep belief network[J]. Journal of Mechanical Transmission,2018,42(6):157-163. DOI: 10.16578/j.issn.1004.2539.2018.06.033
[9] 廖玉波,俞啸,李伟生,等. 基于深度置信网络的旋转机械迁移故障诊断[J]. 机电工程,2022,39(2):193-201. DOI: 10.3969/j.issn.1001-4551.2022.02.008 LIAO Yubo,YU Xiao,LI Weisheng,et al. Transfer fault diagnosis for rotating machinery based on deep belief network[J]. Journal of Mechanical & Electrical Engineering,2022,39(2):193-201. DOI: 10.3969/j.issn.1001-4551.2022.02.008
[10] 黄定洪. 基于深度置信网络的旋转机械设备故障诊断方法研究[D]. 武汉: 武汉理工大学, 2020. HUANG Dinghong. Research on fault diagnosis method of rotating machinery equipment based on deep belief networks[D]. Wuhan: Wuhan University of Technology, 2020.
[11] 丁思凡,王锋,魏巍. 一种基于标签相关度的Relief 特征选择算法[J]. 计算机科学,2021,48(4):91-96. DOI: 10.11896/jsjkx.200800025 DING Sifan,WANG Feng,WEI Wei. Relief feature selection algorithm based on label correlation[J]. Computer Science,2021,48(4):91-96. DOI: 10.11896/jsjkx.200800025
[12] 董飞. 基于数据驱动的滚动轴承故障诊断研究[D]. 徐州: 中国矿业大学, 2018. DONG Fei. Research on rolling bearing fault diagnosis based on data-driven[D]. Xuzhou: China University of Mining and Technology, 2018.
[13] WANG Jindong, CHEN Yiqiang, HAO Shuji, et al. Balanced distribution adaptation for transfer learning[EB/OL]. [2022-05-16]. https://ieeexplore.ieee.org/document/82156132017.
[14] 范春旸. 基于多源信息融合的井下皮带机驱动电机状态识别方法研究[D]. 徐州: 中国矿业大学, 2019. FAN Chunyang. Research on state recognition method of driving motor of mine belt conveyor based on multi-source information fusion[D]. Xuzhou: China University of Mining and Technology, 2019.
[15] YU Xiao,DONG Fei,DING Enjie,et al. Rolling bearing fault diagnosis using modified LFDA and EMD with sensitive feature selection[J]. IEEE Access,2018,6:3715-3730. DOI: 10.1109/ACCESS.2017.2773460
-
期刊类型引用(11)
1. 尹波,彭雷祥,王正超,张磊,尹宜辰. 基于精细地质建模的开采沉陷预计算法优化与应用研究. 煤炭工程. 2025(01): 23-28 .  百度学术
百度学术
2. 王忠宾,李福涛,司垒,魏东,戴嘉良,张森. 采煤机自适应截割技术研究进展及发展趋势. 煤炭科学技术. 2025(01): 296-311 . 百度学术
3. 文广超,王一博,冯雅杰,周彦斌,张一帆,赵梦余. 煤矿井下三维透明地质环境建设探索. 河南理工大学学报(自然科学版). 2025(03): 71-80 . 百度学术
4. 韩晓刚,王江梅,朱万成,李荟,徐晓冬,秦涛,景树柱,韩国平. 多源数据融合的双阳煤矿精细化建模及虚拟现实平台搭建. 矿业研究与开发. 2024(03): 178-184 . 百度学术
5. 于建军,王建成,刘百祥. 基于地质物探数据的工作面透明地质模型构建研究与应用. 山东煤炭科技. 2024(04): 157-161+167+173 . 百度学术
6. 赵亦辉,周转会,杨青,孙永锋,吴振. 采煤机单刀截割曲线最优生成算法研究. 煤炭技术. 2024(06): 224-227 . 百度学术
7. 王海军,郑三龙,王相业,董敏涛,吴艳,马良,杨伟,朱玉英. 地质构造隐蔽致灾因素透明化勘查技术——以新疆屯宝煤矿为例. 煤炭科学技术. 2024(09): 173-188 . 百度学术
8. 李蔚林,赵嘉良,阮柳谭,李泽荃. 基于空间自回归插值方法的煤层厚度预测研究. 煤炭工程. 2024(S1): 112-119 . 百度学术
9. 贾建称,贾茜,桑向阳,吴艳. 我国煤矿地质保障系统建设30年:回顾与展望. 煤田地质与勘探. 2023(01): 86-106 . 百度学术
10. 李森,李重重,刘清. 基于透明地质的综采工作面规划截割协同控制系统. 煤炭科学技术. 2023(04): 175-184 . 百度学术
11. 刘亚,王静宜. 煤层智能化开采设备状态远程监测系统设计. 自动化与仪器仪表. 2023(05): 332-336 . 百度学术
其他类型引用(3)
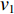
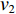
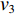
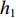
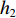
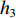
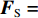
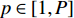
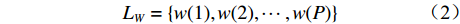
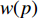
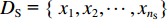
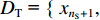
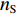
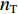
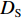
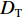
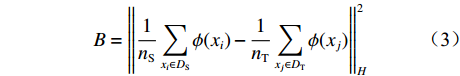
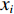
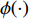
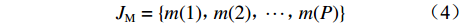
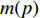
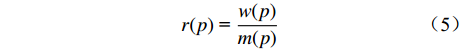
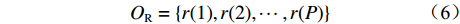
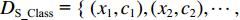
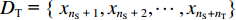
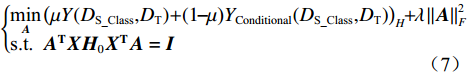

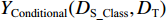
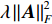
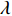
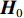
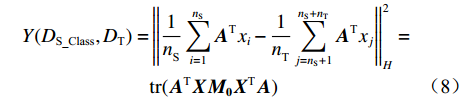
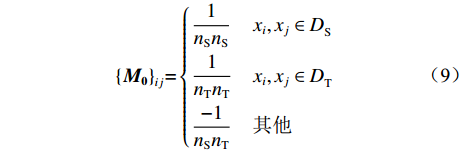
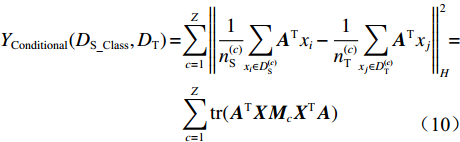
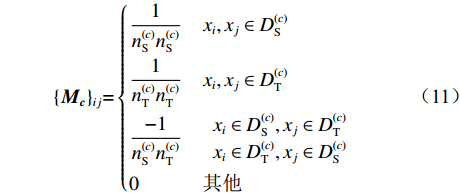
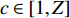
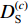
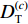
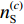
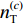

计量
- 文章访问数: 371
- HTML全文浏览量: 162
- PDF下载量: 95
- 被引次数: 14
