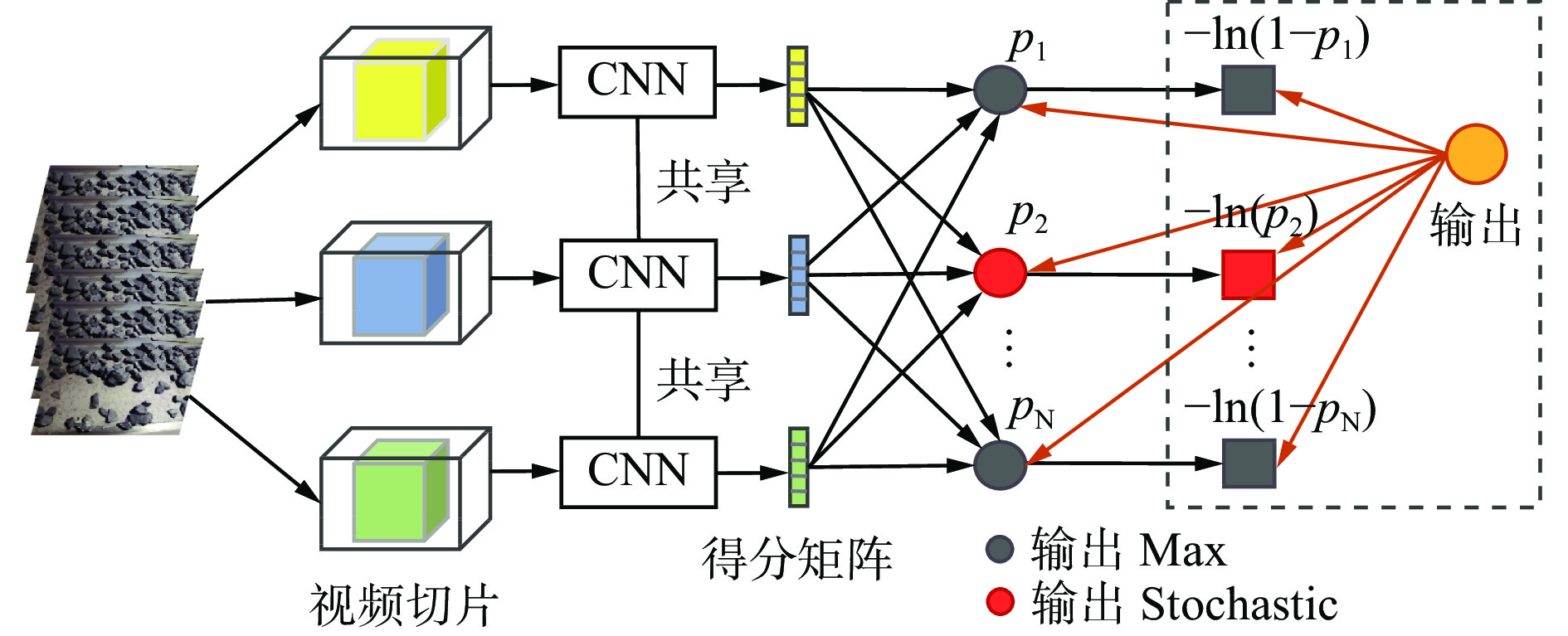
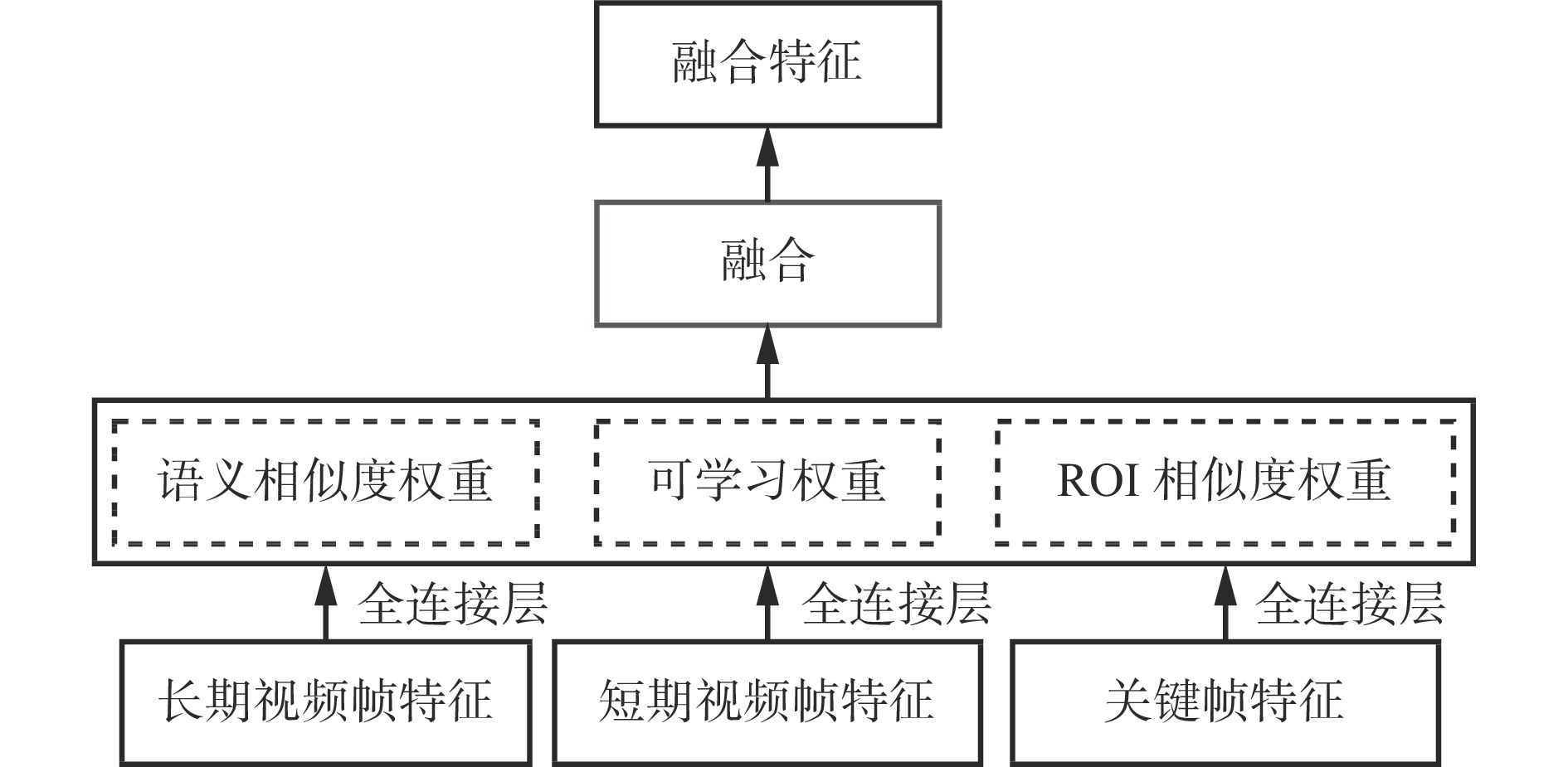
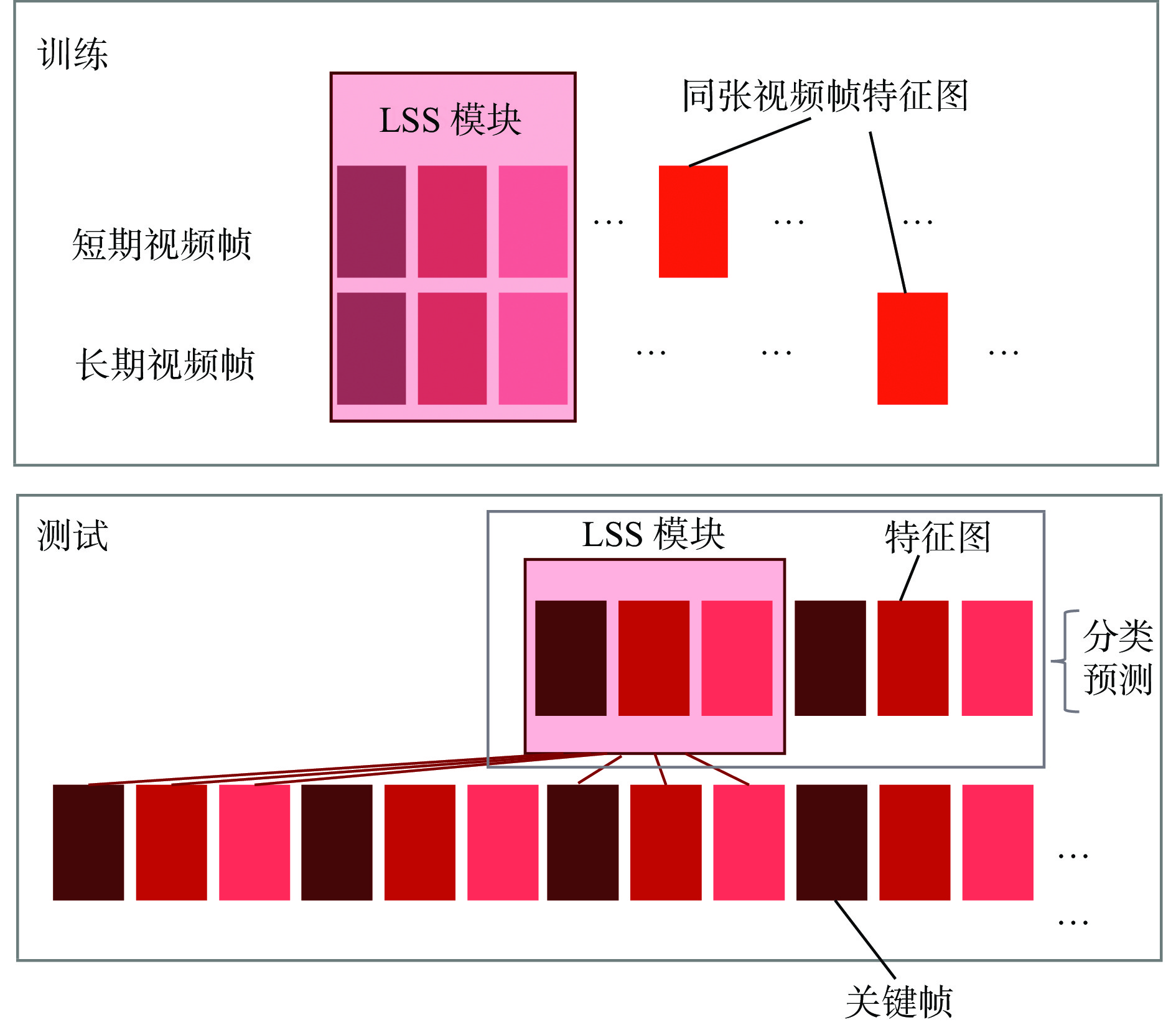
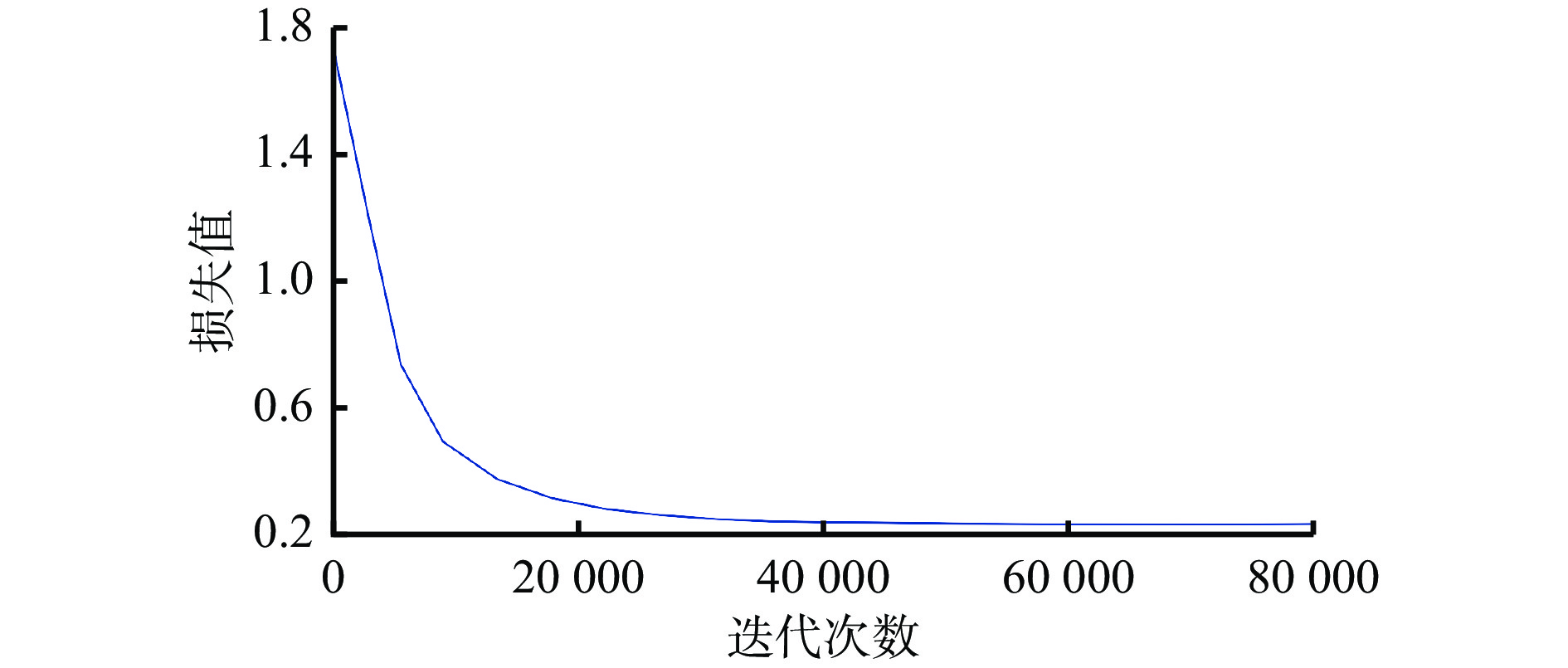
| Citation: | YANG Jun. Aggregation enhanced coal-gangue video recognition model based on long and short-term storage [J]. Journal of Mine Automation,2023,49(3):39-44, 62. doi: 10.13272/j.issn.1671-251x.18058

|
| [1] |
SHARMA V,GUPTA M,KUMAR A,et al. Video processing using deep learning techniques:a systematic literature review[J]. IEEE Access,2021,9:139489-139507. doi: 10.1109/ACCESS.2021.3118541
|
| [2] |
AICH A, ZHENG M, KAEANAM S, et al. Spatio-temporal representation factorization for video-based person re-identification[C]. International Conference on Computer Vision, Montreal, 2021: 152-162.
|
| [3] |
孙立新. 基于卷积神经网络的煤矸石识别方法研究[D]. 邯郸: 河北工程大学, 2020.
SUN Lixin. Research on coal gangue recognition method based on convolutional neural network[D]. Handan: Hebei University of Engineering, 2020.
|
| [4] |
PAN Hongguang,SHI Yuhong,LEI Xinyu,et al. Fast identification model for coal and gangue based on the improved tiny YOLO V3[J]. Journal of Real-Time Image Processing,2022,19(3):687-701. doi: 10.1007/s11554-022-01215-1
|
| [5] |
ZHU Xizhou, WANG Yujie, DAI Jifeng, et al. Flow-guided feature aggregation for video object detection[C]. IEEE International Conference on Computer Vision, Venice, 2017, 408-417.
|
| [6] |
张勇. 基于视频处理的煤矸石识别研究[D]. 徐州: 中国矿业大学, 2018.
ZHANG Yong. Research on gangue identification based on video processing[D]. Xuzhou: China University of Mining and Technology, 2018.
|
| [7] |
程健,王东伟,杨凌凯,等. 一种改进的高斯混合模型煤矸石视频检测方法[J]. 中南大学学报(自然科学版),2018,49(1):118-123.
CHENG Jian,WANG Dongwei,YANG Lingkai,et al. An improved Gaussian mixture model for coal gangue video detection[J]. Journal of Central South University (Science and Technology),2018,49(1):118-123.
|
| [8] |
LEI Xinyu,PAN Hongguang,HUANG Xiangdong. A dilated CNN model for image classification[J]. IEEE Access,2019,7:124087-124095. doi: 10.1109/ACCESS.2019.2927169
|
| [9] |
PAN Hongguang,WEN Fan,HUANG Xiangdong,et al. The enhanced deep plug-and-play super-resolution algorithm with residual channel attention networks[J]. Journal of Intelligent & Fuzzy Systems:Applicationgs in Engineering and Technology,2021,41(2):4069-4078.
|
| [10] |
ZHU Xizhou, DAI Jifeng, YUAN Lu, et al. Towards high performance video object detection[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, 2018: 7210-7218.
|
| [11] |
WANG Shiyao, ZHOU Yucong, YAN Junjie, et al. Fully motion-aware network for video object detection[C]. Proceedings of the European Conference on Computer Vision, Munich, 2018: 542-557.
|
| [12] |
WU Haiping, CHEN Yuntao, WANG Naiyan, et al. Sequence level semantics aggregation for video object detection[C]. The IEEE/CVF International Conference on Computer Vision, Seoul, 2019: 9217-9225.
|
| [13] |
FEICHTENHOFER C, PINZ A, ZISSERMAN A. Detect to track and track to detect[C]. The IEEE International Conference on Computer Vision, Venice, 2017: 3038-3046.
|
| [14] |
ZHOU Bolei, ANDONIAN A, TORRALBA A. Temporal relational reasoning in videos[C]. European Conference on Computer Vision, Munich, 2018: 803-818.
|
| [15] |
LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, 2017: 936-944.
|
| [16] |
HE Kaiming, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[C]. International Conference on Computer Vision, Venice, 2017: 2961-2969.
|
| [17] |
REN Shaoqing,HE Kaiming,GIRSHICK R,et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149. doi: 10.1109/TPAMI.2016.2577031
|
| [18] |
CHEN Yihong, CAO Yue, HU Han, et al. Memory enhanced global-local aggregation for video object detection[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2020: 10337-10346.
|
| [19] |
GIRSHICK R. Fast R-CNN[C]. IEEE International Conference on Computer Vision, Santiago, 2015, 1440-1448.
|
| [20] |
HOCHREITER S,SCHMIDHUBER J. Long short-term memory[J]. Neural Computation,1997,9(8):1735-1780. doi: 10.1162/neco.1997.9.8.1735
|
| [21] |
DENG Jiajun, PAN Yingwei, YAO Ting, et al. Relation distillation networks for video object detection[C]. The IEEE/CVF International Conference on Computer Vision, Seoul, 2019: 7023-7032.
|
| [22] |
ZHU Xizhou, XIONG Yuwen, DAI Jifeng, et al. Deep feature flow for video recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, 2017: 2349-2358.
|

Figures(7) / Tables(1)
Supported by:
Beijing Renhe Information Technology Co. Ltd.
Visits:




 DownLoad:
DownLoad: