
Deep learning-based face detection method under low illumination conditions in coal mines
-
摘要: 煤矿井下光线昏暗、人工光源干扰等造成监控系统采集到的人脸图像对比度低、人脸特征模糊,传统人脸检测算法应用于煤矿井下时会出现误检、漏检。针对上述问题,提出了一种基于深度学习的煤矿井下低光照人脸检测方法。采用基于无监督学习的生成对抗网络(GAN)对煤矿井下低光照图像进行对比度增强,使用自调整注意力引导的U−Net作为生成器,利用双判别器对全局和局部信息进行引导,并使用自特征保留损失函数来指导训练过程和维护图像中人脸的纹理结构,强化人脸特征,避免出现曝光、人脸细节信息丢失等现象,得到较为清晰的人脸图像;利用RetinaFace人脸检测框架对增强后的人脸特征进行检测,其采用特征金字塔结构和单阶段检测模式对人脸图像进行检测,在基本不增加计算量的同时,提高对小尺度人脸检测的能力。在公开低光照人脸数据集DARK FACE和自建煤矿井下人脸数据集上的实验结果表明,该方法提高了图像对比度,清晰地恢复了图像中的人脸特征,在准确率、召回率、平均精度方面均表现较好,有效提高了煤矿井下人脸检测精度。Abstract: The low contrast and blurry facial features of facial images collected by the monitoring system are caused by dim illumination and interference from artificial illumination sources in coal mines. Traditional facial detection algorithms may cause false or missed detections when applied in coal mines. In order to solve the above problems, a deep learning-based face detection method under low illumination conditions in coal mines is proposed. A generative adversarial network (GAN) based on unsupervised learning is used to enhance the contrast of low illumination images in coal mines. A self-adjusting attention guided U-Net is used as the generator, and dual discriminators are used to guide global and local information. The self-feature retention loss function is used to guide the training process and maintain the texture structure of the face in the image and strengthen facial features. It can avoid phenomena such as exposure and loss of facial detail information, and obtain clearer facial images. The RetinaFace face detection framework is used to detect the enhanced facial features. It uses a feature pyramid structure and a single stage detection mode to detect facial images. It improves the capability to detect small-scale faces without increasing computational complexity. The experimental results on the public low illumination face dataset DARK FACE and the self built coal mine underground face dataset show that this method improves image contrast, clearly restores facial features in the image, and performs well in accuracy, recall, and average accuracy, effectively improving the accuracy of coal mine underground face detection.
-
0. 引言
在智能化矿山建设中[1],采用计算机视觉技术对井下巷道入口、工作面等区域进行人脸检测,可实时检测矿工的状态和位置,及时发现并处理异常情况,对于提高煤矿安全具有重要意义。
随着深度学习的发展,人脸检测可使用通用目标检测算法完成,如RCNN(Regions with Convolutional Neural Network features)[2],Faster RCNN[3],YOLO(You Only Look Once)[4],SSD(Single Shot Detector)[5]等,也可通过专门为人脸检测任务设计的算法完成,如DSFD(Dual Shot Face Detector)[6],PyramidBox[7],MTCNN(Multi-Task Convolutional Neural Network)[8],RetinaFace[9]等。RCNN是一种简单可放缩的目标检测算法,使用区域的方法进行识别,解决了卷积神经网络提取候选区域特征定位不准确的问题。Faster RCNN算法使用VGG−16作为骨干网络,摒弃了传统的滑动窗口和选择性搜索方法,直接使用区域候选网络生成检测框,大大提高了检测精度和效率。YOLO算法最突出的优势是速度快,可用于实时系统,直接通过主干网络同时检测出图像中物体的位置和类别信息。SSD从多个角度对目标检测做出创新,结合Faster RCNN和YOLO各自的优点,使得目标检测速度和精度有了很大提升。DSFD在继承SSD检测框架的基础上,引入了一种特征增强模块来转换原始特征图,通过使用一些更小的锚点在底层引入辅助检测来有效简化特征。PyramidBox通过低层级金字塔来更好地融合环境特征和面部特征,实现了较小、模糊和部分遮挡情况下的人脸检测。MTCNN采用多任务级联人脸检测和人脸对齐框架,使得其能够在小型设备上运行。RetinaFace是一种鲁棒性较强的单阶段人脸检测框架,通过联合外监督和自监督的多任务学习,可对各种尺度条件下的人脸做到像素级别的定位,并且通过采用轻量级骨干网络,可对视频图像进行实时检测,达到很好的检测效果。
上述算法在通用人脸检测数据集[10-11]上都达到了较高的检测水平,但煤矿井下光线昏暗、人工光源干扰等复杂环境导致监控视频图像存在对比度低、光照不均匀、人脸特征模糊等问题,上述算法应用在煤矿井下图像时会对人脸敏感度变弱,出现较多的误检、漏检现象,无法满足煤矿井下人脸检测要求。因此,本文将GAN(Generative Adversarial Network,生成对抗网络)与RetinaFace人脸检测框架结合,提出了一种煤矿井下低光照人脸检测方法。该方法通过基于GAN的增强模块提高输入图像的对比度和亮度,强化人脸区域,最大限度地保留图像中的人脸特征,再通过RetinaFace检测模块对增强后的图像进行人脸检测,有效提高了煤矿井下人脸图像的检测精度。
1. 方法原理
1.1 增强模块
常用的低光照图像增强方法包括基于直方图的方法[12]、基于Retinex的方法[13]、基于频域变换和图像融合的方法[14]和基于深度学习的方法[15-17]等。基于直方图的方法可有效提高图像对比度,但易造成色彩保真度损失并产生噪声,导致图像失真。基于Retinex的方法增强效果好,但可能会导致在某些边界清晰的区域出现光晕或导致整个图像太亮。基于频域变换和图像融合的方法需要同一场景的2幅或多幅不同图像,很难在短时间内实现图像增强。基于深度学习的方法可解决图像存在的光照不均匀、局部曝光、视觉自然度低等问题,主要分为有监督学习和无监督学习,其中有监督学习需要大量同一场景下不同光照的图像作为数据集进行网络训练,而煤矿井下环境特殊,无法采集大量成对图像,因此本文使用无监督学习对煤矿井下图像进行增强。
增强模块由基于无监督学习的GAN[18]构成,其通过生成器对输入图像进行注意力自调整,使用双判别器来引导全局和局部信息,并利用自特征保留损失函数来指导训练过程并保持低光照图像的纹理结构。
1.1.1 生成器
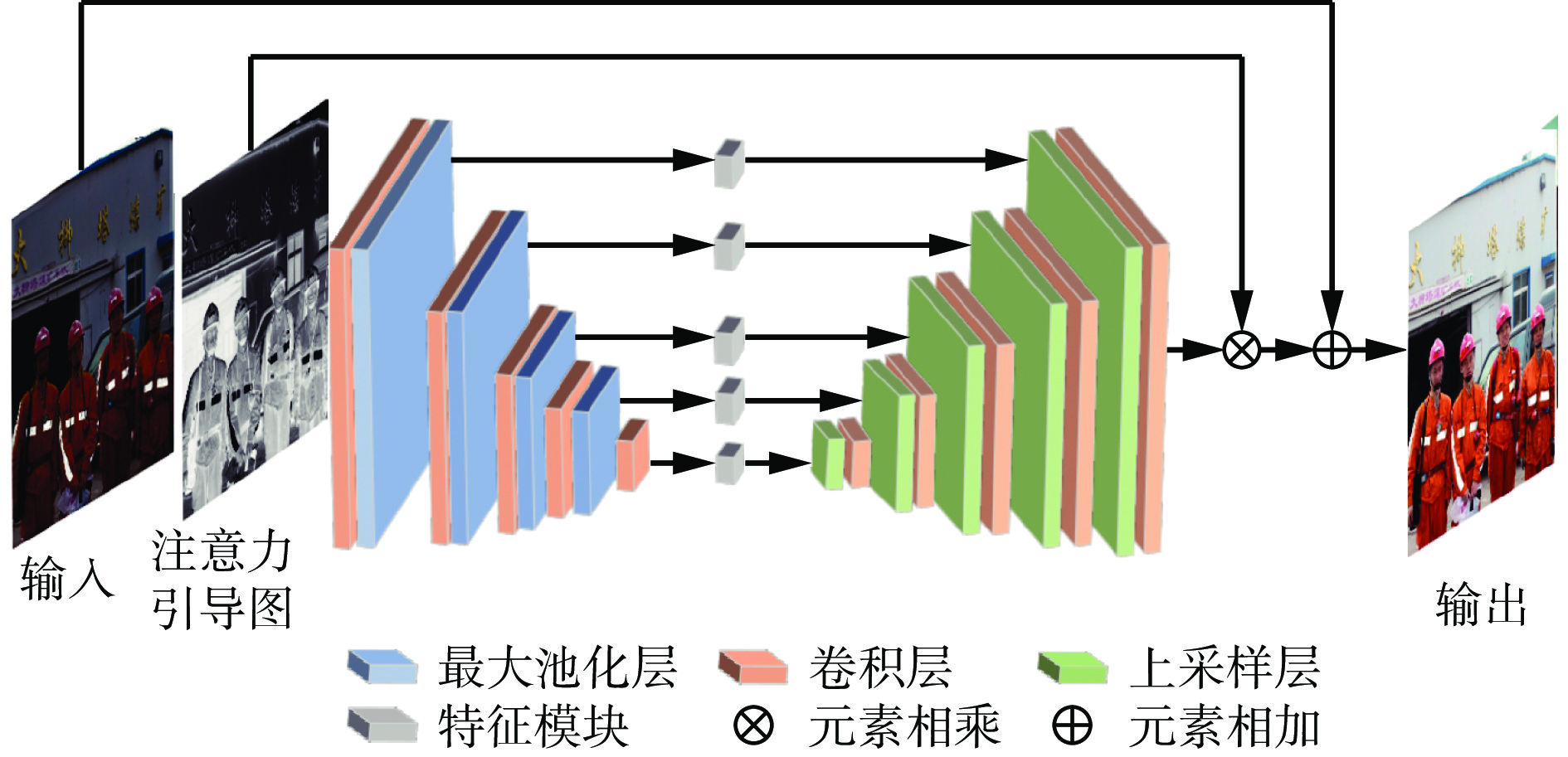
GAN采用自调整注意力引导的U−Net[19]作为生成器,结构如图1所示。将输入RGB图像的光照通道归一化为[0,1],使用光照通道的反通道图作为注意力引导图,这样能在光线空间变换中尽可能地增强光线较暗区域,避免出现曝光或对比度增强不足的现象。将注意力引导图输入U−Net中,注意力引导图经过5次卷积和4次最大池化操作后,裁剪注意力引导图的大小以适应每个特征图层。在上采样阶段,用1个双线性上采样层和卷积层代替标准的反卷积层,以减轻特征图的伪影。U−Net通过提取不同深度的多层次特征,保留了丰富的纹理信息,并利用多尺度上下文信息合成高质量的增强结果。
1.1.2 判别器
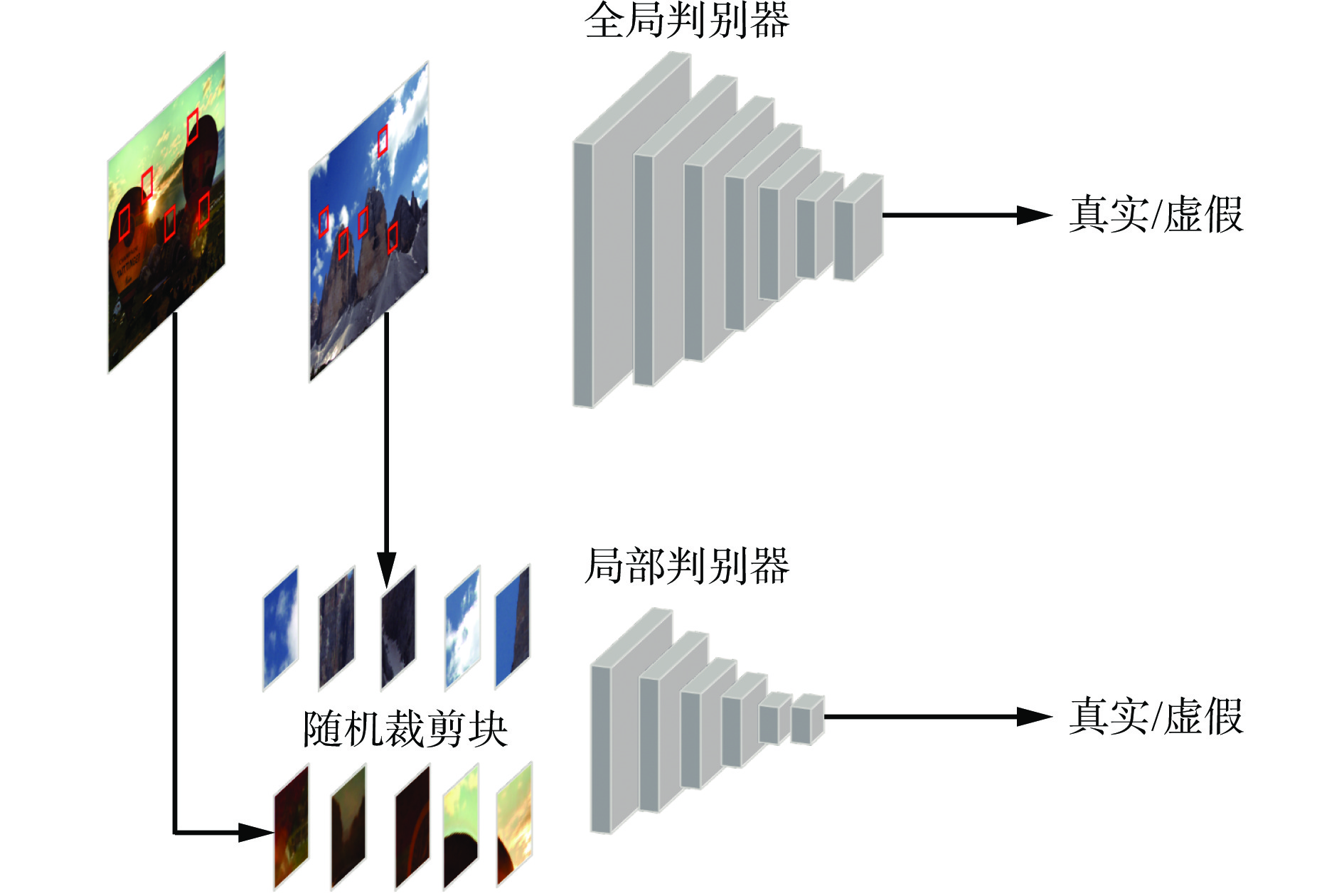
为自适应地增强局部区域的同时提高全局光照亮度,本文采用一种全局−局部双判别器,结构如图2所示。该判别器使用PatchGAN[20]进行真假鉴别,局部判别器从输出和真实的正常光照图像中随机裁剪局部小块,并学习区分它们是真实的还是虚假的,保证了图像全局和局部亮度、对比度提升的自然度,能有效避免图像出现局部曝光。
全局判别器利用相对判别器结构[21]估计真实数据比虚假数据更真实的概率,并指导生成器生成接近真实图像的伪图像。相对判别器的标准函数为
$$ D({x_{\mathrm{r}}},{x_{\mathrm{f}}}) = \sigma (C({x_{\mathrm{r}}}) - {{ E}_{{x_{_{\mathrm{f}}}} \sim {{\mathrm{P}}}_{{\mathrm{fake}}}}}(C({x_{\mathrm{f}}}))) $$ (1) $$ D({x_{\mathrm{f}}},{x_{\mathrm{r}}}) = \sigma (C({x_{\mathrm{r}}}) - {{ E}_{{x_{\mathrm{r}}} \sim {{\mathrm{P}}_{{\mathrm{real}}}}}}(C({x_{\mathrm{r}}}))) $$ (2) 式中:$ D({x_{\mathrm{r}}},{x_{\mathrm{f}}}) $为判别器判别真实数据相对于虚假数据更为真实的概率,$ {x_{\mathrm{r}}} $和$ {x_{\mathrm{f}}} $分别为真实数据和虚假数据;$ \sigma $(·)为sigmoid激活函数;C(·)为判别器网络;$ {E_{{x_{\mathrm{f}}}\sim{{{\mathrm{P}}}_{{\mathrm{fake}}}}}} $(·)为对训练虚假数据样本的期望;$ {E_{{x_{\mathrm{r}}}\sim{{{\mathrm{P}}} _{{\mathrm{real}}}}}} $(·)为对训练真实数据样本的期望; $ D({x_{\mathrm{f}}},{x_{\mathrm{r}}}) $为判别器判别虚假数据相对于真实数据更为真实的概率。
1.2 增强模块损失函数
生成器的目标是要使判别器认为虚假数据$ {x_{\mathrm{f}}} $是真,因此$ D({x_{\mathrm{f}}},{x_{\mathrm{r}}}) $越大越好,$ D({x_{\mathrm{r}}},{x_{\mathrm{f}}}) $越小越好;而判别器要分辨出虚假数据$ {x_{\mathrm{f}}} $为假,因此$ D({x_{\mathrm{r}}},{x_{\mathrm{f}}}) $越大越好,$ D({x_{\mathrm{f}}},{x_{\mathrm{r}}}) $越小越好。对于全局的判别器和生成器,迭代过程中的损失函数可表示为
$$ L_{\mathrm{D}}^{{\mathrm{Global}}} = {E_{{x_{\mathrm{r}}} \sim {{{\mathrm{P}}} _{{\mathrm{real}}}}}}({(D({x_{\mathrm{r}}},{x_{\mathrm{f}}}) - 1)^2}) + {E_{{x_{\mathrm{f}}} \sim {{{\mathrm{P}}} _{{\mathrm{fake}}}}}}(D^2{({x_{\mathrm{f}}},{x_{\mathrm{r}}})}) $$ (3) $$ L_{\mathrm{G}}^{{\mathrm{Global}}} = {E_{{x_{\mathrm{f}}} \sim {{{\mathrm{P}}} _{{\mathrm{fake}}}}}}({(D({x_{\mathrm{f}}},{x_{\mathrm{r}}}) - 1)^2}) + {E_{{x_{\mathrm{r}}} \sim {{{\mathrm{P}}} _{{\mathrm{real}}}}}}(D^2{({x_{\mathrm{r}}},{x_{\mathrm{f}}})}) $$ (4) 式中$L_{\mathrm{D}}^{{\mathrm{Global}}}$和$ L_{\mathrm{G}}^{{\mathrm{Global}}} $分别为全局的判别器损失函数和生成器损失函数。
对于局部的判别器和生成器,迭代过程中的损失函数可表示为
$$ L_{\mathrm{D}}^{{\mathrm{Local}}} = {E_{{x_{\mathrm{r}}} \sim {{{\mathrm{P}}} _{{\mathrm{real}} - {\mathrm{patches}}}}}}({(D({x_{\mathrm{r}}}) - 1)^2}) + {E_{{x_{\mathrm{f}}} \sim {{{\mathrm{P}}} _{{\mathrm{fake}} - {\mathrm{patches}}}}}}(D^2{({x_{\mathrm{f}}})}) $$ (5) $$ L_{\mathrm{G}}^{{\mathrm{Local}}} = {E_{{x_{\mathrm{r}}} \sim {{{\mathrm{P}}} _{{\mathrm{fake}} - {\mathrm{patches}}}}}}({(D({x_{\mathrm{f}}}) - 1)^2}) $$ (6) 式中:$L_{\mathrm{D}}^{{\mathrm{Local}}}$和$L_{\mathrm{G}}^{{\mathrm{Local}}}$分别为局部的判别器损失函数和生成器损失函数;$ {E_{{x_{\mathrm{r}}}\sim{{{\mathrm{P}}} _{{\mathrm{real}} - {\mathrm{peatches}}}}}} $(·)为对训练真实数据局部样本的期望;$D({x_{\mathrm{r}}}) $,$D({x_{\mathrm{f}}}) $分别为判别器判别真实数据、虚假数据的概率;$ {E_{{x_{\mathrm{f}}}\sim{{{\mathrm{P}}} _{{{\mathrm{fake}- {\mathrm{patches}}}}} }}} $(·)为对训练虚假数据局部样本的期望。
为限制感知相似性,提出自特征保留损失函数来限制输入低光照图像与其增强后正常图像之间在VGG网络中的特征距离,使其能更好地保留图像的内容特征。自特征保留损失函数为
$$ L_{\mathrm{SFP}}=\frac{1}{WH}\sum\limits_{X=1}^W\sum\limits_{Y=1}^H(\phi_{X,Y}-\phi_{X,Y}(G))^2 $$ (7) 式中:W,H分别为提取的特征图的最大网络块数和卷积层数;${\phi _{X,Y}}$为输入图像在VGG网络中第X(X=1,2,···,W)个网络块的第Y(Y=1,2,···,H)个卷积层得到的特征图;$G$为生成器输出的增强图像。
增强模块的损失函数为
$$ {L_{{\text{loss}}}} = L_{{\mathrm{SFP}}}^{} + L_{\mathrm{G}}^{{\mathrm{Global}}} + L_{\mathrm{G}}^{{\mathrm{Local}}} + L_{\mathrm{D}}^{{\mathrm{Global}}} + L_{\mathrm{D}}^{{\mathrm{Local}}} $$ (8) 1.3 检测模块
检测模块采用RetinaFace人脸检测框架来检测图像中的人脸。RetinaFace结构如图3所示。首先通过主干网络ResNet50对图像进行特征提取,接着采用特征金字塔结构和单阶段检测模式进行人脸检测,在基本不增加计算量的同时,提高对小尺度人脸检测的能力。然后使用类别标注、预测框标注和特征点标注从特征中获取预测结果,并对预测结果进行解码。最后通过非极大值抑制技术去除重复检测值,得出最终结果。
1.4 检测模块损失函数
对于任何训练锚$i$,RetinaFace多任务联合损失函数定义为
$$ \begin{split}& L = {L_{{\mathrm{cls}}}}({p_i},p_i^ * ) + {\lambda _1}p_i^ * {L_{{\mathrm{box}}}}({t_i},t_i^ * ) + {\lambda _2}p_i^ * {L_{{\mathrm{pts}}}}({l_i},l_i^ * ) + {\lambda _3}p_i^ * {L_{{\mathrm{pixel}}}} \\[-12pt]&{} \end{split} $$ (9) 式中:$ {L_{{\mathrm{cls}}}}({p_i},p_i^ * ) $为人脸分类损失函数,${p_i}$为正锚点框标签,$p_{_i}^ * $为负锚点框标签;${\lambda _1}$−${\lambda _3}$为损失平衡权值参数,在RetinaFace中分别设置为0.25,0.10,0.01;$ {L_{{\mathrm{box}}}}({t_i},t_i^ * ) $为人脸框回归损失函数,$ {t_i} $为正锚点框相关的预测框坐标值,$ t_i^ * $为正锚点框相关的真实框坐标值;$ {L_{{\mathrm{pts}}}}({l_i},l_i^ * ) $为面部标志回归损失函数,$ {l_i} $为正锚点框中预测的人脸标志点,$ l_i^ * $为正锚点框中标注的人脸标志点;${L_{{\mathrm{pixel}}}}$为面部密集点回归损失函数。
2. 实验及结果分析
2.1 实验条件
网络训练采用公开低光照人脸数据集DARK FACE[22]和自建煤矿井下人脸数据集。其中自建煤矿井下人脸数据集主要由3个部分组成:① 来自煤矿井下监控视频和拍摄的人脸图像,对视频进行拆帧处理,获取每一帧图像,然后筛选掉大量相似图像和不合格图像。② 使用国内外公开煤矿井下数据集,筛选其中含有人脸或人脸个数较多的图像进行数据集扩充。③ 利用公开的正常光照人脸数据集,使用CycleGAN进行图像风格迁移,获得伪煤矿井下人脸图像进行数据集扩充。
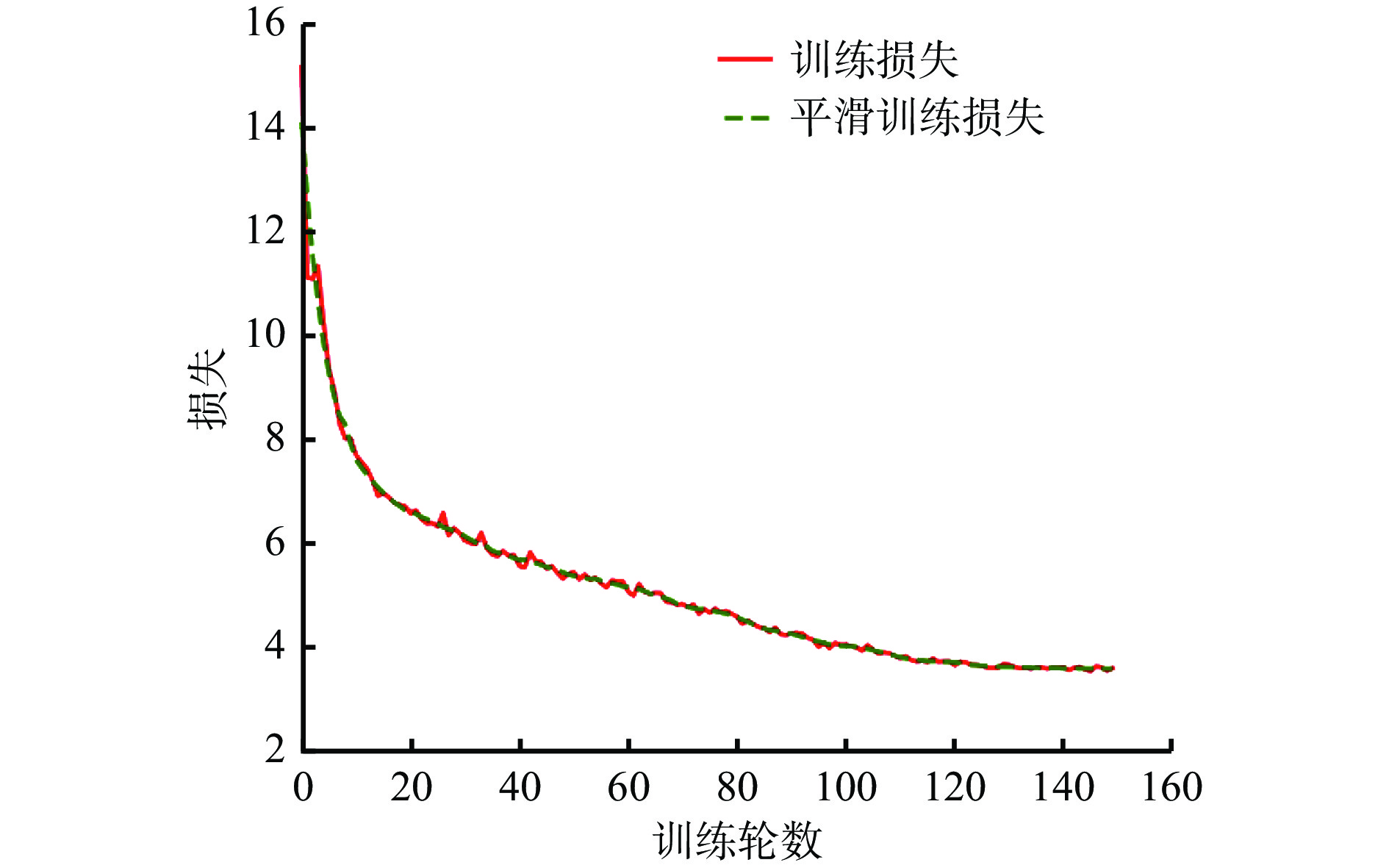
实验基于PyTorch深度学习框架,在NVIDIA GeForce RTX 3090 GPU下进行训练。为使网络更快适应训练,设置初始学习率为0.01,使用随机梯度下降算法优化更新梯度,训练轮数为150,批量大小为8。损失变化曲线如图4所示,可看出训练轮数在大约130时损失变化趋于平稳。
2.2 结果分析
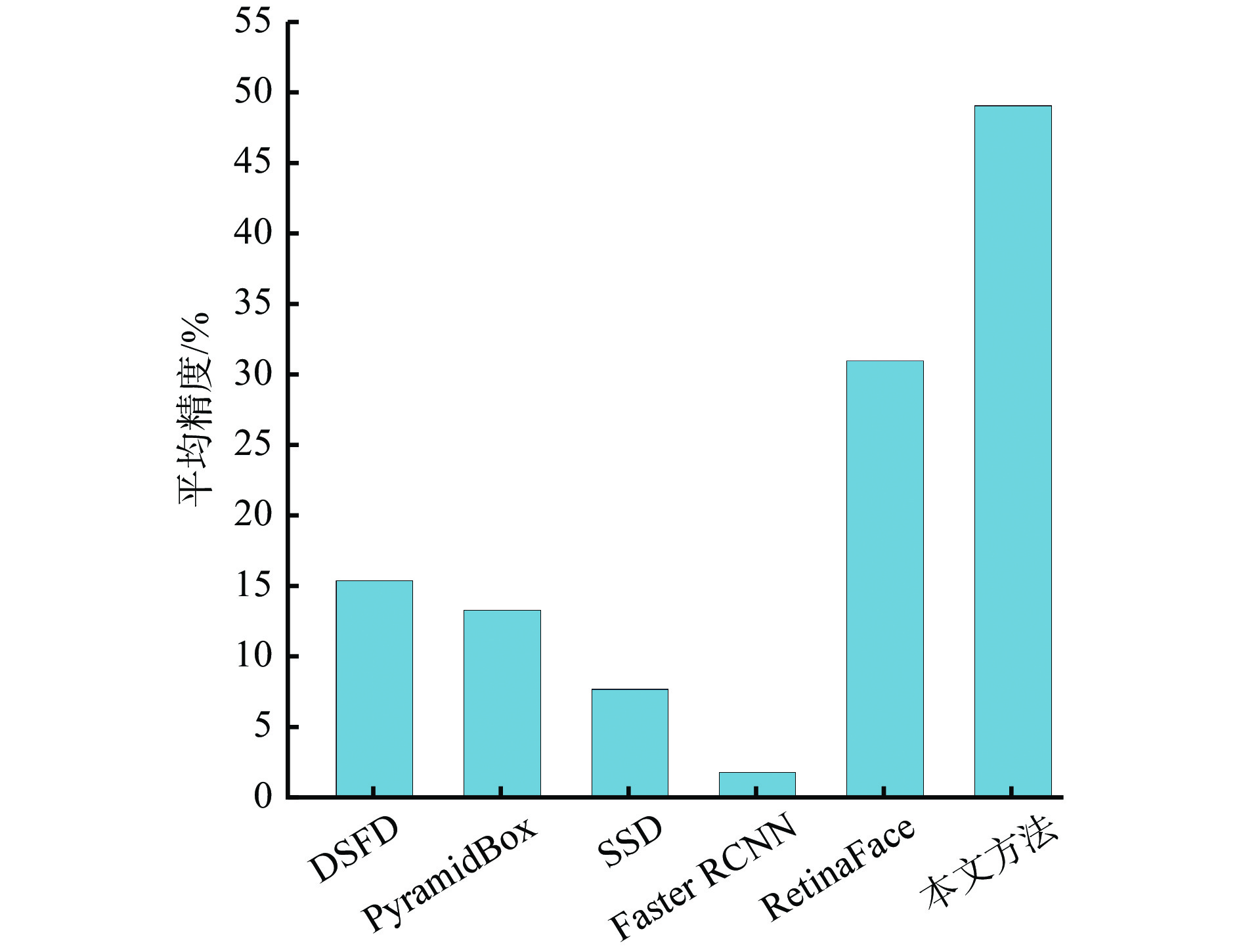
为验证本文方法在低光照环境下的有效性,选取DSFD,PyramidBox,SSD,Faster RCNN和RetinaFace在公开低光照人脸数据集DARK FACE上进行平均精度测试,结果如图5所示。可看出DSFD,PyramidBox,SSD,Faster RCNN的人脸检测精度较低,而RetineaFace的检测精度相对较高,但也只达到30.9%,而本文方法由于在RetinaFace的基础上加入了增强模块,对低光照图像进行增强预处理,强化了人脸特征,可较为准确地提取到图像中的人脸信息,检测精度达49%,比原始RetinaFace提高了58.6%。
在自建煤矿井下人脸数据集上对本文方法进行测试,结果如图6所示。可看出本文方法可有效检测出矿井低光照环境下的人脸,并且可视化效果好,提高了图像对比度的同时,清晰地恢复了图像中的人脸特征。
为进一步证明本文方法针对煤矿井下图像的实用性和有效性,采用自建煤矿井下人脸数据集对RetinaFace和本文方法进行主观和客观评价。
不同方法下煤矿井下人脸图像(编号为T125,T196,T218,T421,T563)的检测结果如图7所示。可看出由于煤矿井下光照不均匀导致采集到的图像出现曝光、局部区域信息丢失等现象,使得RetinaFace出现漏检,在图像T563中甚至出现误检,将安全帽检测为人脸;而本文方法在图像T125,T196,T218,T421中正确检测人脸数均有提升,在图像T563中也能精确检测人脸,这是由于本文方法引入了增强模块对RetinaFace进行改进,充分恢复了图像中人脸的特征细节,避免了煤矿井下光照问题引起的误检,提高了检测精度。
![]() 图 7 不同方法下人脸检测效果对比Figure 7. Comparison of face detection effects under different methods
图 7 不同方法下人脸检测效果对比Figure 7. Comparison of face detection effects under different methods对RetinaFace和本文方法在自建煤矿井下人脸数据集上进行客观评价,结果见表1。可看出本文方法在准确率、召回率、平均精度上均优于RetinaFace,分别提升了0.65%,8.92%,8.26%。
表 1 不同方法下客观评价结果Table 1. Objective evaluation results of different methods% 方法 准确率 召回率 平均精度 RetinaFace 91.2 59.4 54.5 本文方法 91.8 64.7 59.0 3. 结论
1) 采用无监督学习的GAN进行人脸图像增强,提高煤矿井下人脸图像对比度,避免图像中人工光源区域过度增强,使图像中的人脸特征得到恢复,图像视觉效果更真实。
2) 使用RetinaFace人脸检测框架对增强后的图像进行人脸检测,采用特征金字塔结构和单阶段检测模式对强化后的人脸特征进行检测,提高了模型对图像中人脸检测的敏感度。
3) 实验结果表明,该方法能较为准确地对煤矿井下图像进行人脸检测,并提取到图像中人脸的细节信息,有效克服了煤矿井下低光照、光照不均匀导致的漏检、误检,有效提升了煤矿井下人脸检测精度。
-
![]()
图 7 不同方法下人脸检测效果对比
Figure 7. Comparison of face detection effects under different methods
表 1 不同方法下客观评价结果
Table 1 Objective evaluation results of different methods
% 方法 准确率 召回率 平均精度 RetinaFace 91.2 59.4 54.5 本文方法 91.8 64.7 59.0  下载: 导出CSV
下载: 导出CSV
-
[1] 钱鸣高,许家林,王家臣. 再论煤炭的科学开采[J]. 煤炭学报,2018,43(1):1-13. DOI: 10.13225/j.cnki.jccs.2017.4400 QIAN Minggao,XU Jialin,WANG Jiachen. Further on the sustainable mining of coal[J]. Journal of China Coal Society,2018,43(1):1-13. DOI: 10.13225/j.cnki.jccs.2017.4400
[2] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. IEEE Conference on Computer Vision and Pattern Recognition,Columbus,2014:580-587.
[3] REN Shaoqing,HE Kaiming,GIRSHICK R,et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149. DOI: 10.1109/TPAMI.2016.2577031
[4] 郑道能. 一种改进的tiny YOLO v3煤矸石快速识别模型[J]. 工矿自动化,2023,49(4):113-119. ZHENG Daoneng. An improved tiny YOLO v3 rapid recognition model for coal-gangue[J]. Journal of Mine Automation,2023,49(4):113-119.
[5] BERG A C,FU Chengyang,SZEGEDY C,et al. SSD:single shot multibox detector[C]. European Conference on Computer Vision,Amsterdam,2016:21-37.
[6] LI Jian,WANG Yabiao,WANG Changan,et al. DSFD:dual shot face detector[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition,Los Angeles,2019:5060-5069.
[7] TANG Xu,DU D K,HE Zeqiang,et al. PyramidBox:a context-assisted single shot face detector[C]. European Conference on Computer Vision,Munich,2018:797-813.
[8] ZHANG Kaipeng,ZHANG Zhanpeng,LI Zhifeng,et al. Joint face detection and alignment using multi-task cascaded convolutional networks[J]. IEEE Signal Processing Letters,2016,23(10):1499-1503. DOI: 10.1109/LSP.2016.2603342
[9] DENG Jiankang,GUO Jia,VERVERAS E,et al. Retinaface:single-shot multi-level face localisation in the wild[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition,Seattle,2020:5203-5212.
[10] 刘淇缘. 单阶段复杂人脸检测方法研究[D]. 北京:中国人民公安大学,2021. LIU Qiyuan. Research on one-stage complex face detection methods[D]. Beijing:People's Public Security University of China,2021.
[11] YANG Shuo,LUO Ping,LOY C C,et al. Wider face:a face detection benchmark[C]. IEEE Conference on Computer Vision and Pattern Recognition,Las Vegas,2016:5525-5533.
[12] 万俊霞,林珊玲,梅婷,等. 基于图像分割和动态直方图均衡的电润湿显示器图像增强算法[J]. 光子学报,2022,51(2):240-250. WAN Junxia,LIN Shanling,MEI Ting,et al. Image enhancement algorithm of electrowetting display based on image segmentation and dynamic histogram equalization[J]. Acta Photonica Sinica,2022,51(2):240-250.
[13] REN Xutong,YANG Wenhan,CHENG Wenhuang,et al. LR3M:robust low-light enhancement via low-rank regularized Retinex model[J]. IEEE Transactions on Image Processing,2020,29:5862-5876. DOI: 10.1109/TIP.2020.2984098
[14] WANG Lei,FU Guangtao,JIANG Zhuqiang,et al. Low-light image enhancement with attention and multi-level feature fusion[C]. IEEE International Conference on Multimedia & Expo Workshops,Shanghai,2019:276-281.
[15] LI Jinjiang,FENG Xiaomei,HUA Zhen. Low-light image enhancement via progressive-recursive network[J]. IEEE Transactions on Circuits and Systems for Video Technology,2021,31(11):4227-4240. DOI: 10.1109/TCSVT.2021.3049940
[16] GUO Chunle,LI Chongyi,GUO Jichang,et al. Zero-reference deep curve estimation for low-light image enhancement[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition,Seattle,2020:1780-1789.
[17] LEE H,SOHN K,MIN Dongbo. Unsupervised low-light image enhancement using bright channel prior[J]. IEEE Signal Processing Letters,2020,27:251-255. DOI: 10.1109/LSP.2020.2965824
[18] JIANG Yifan,GONG Xinyu,LIU Ding,et al. EnlightenGAN:deep light enhancement without paired supervision[J]. IEEE Transactions on Image Processing,2021,30:2340-2349. DOI: 10.1109/TIP.2021.3051462
[19] 刘丹英,刘晓燕. 基于U−Net卷积神经网络的多尺度遥感图像分割算法[J]. 现代电子技术,2023,46(21):44-47. DOI: 10.16652/j.issn.1004-373x.2023.21.009 LIU Danying,LIU Xiaoyan. Multi-scale remote sensing image segmentation algorithm based on U-net convolutional neural network[J]. Modern Electronics Technique,2023,46(21):44-47. DOI: 10.16652/j.issn.1004-373x.2023.21.009
[20] 王照乾,孔韦韦,滕金保,等. DenseNet生成对抗网络低照度图像增强方法[J]. 计算机工程与应用,2022,58(8):214-220. WANG Zhaoqian,KONG Weiwei,TENG Jinbao,et al. Low illumination image enhancement method based on DenseNet GAN[J]. Computer Engineering and Applications,2022,58(8):214-220.
[21] DONG Xuan,WANG Guan,PANG Yi,et al. Fast efficient algorithm for enhancement of low lighting video[C]. IEEE International Conference on Multimedia and Expo,Barcelona,2011:1-6.
[22] MA Long,MA Tengyu,LIU Risheng,et al. Toward fast,flexible,and robust low-light image enhancement[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition,New Orleans,2022:5637-5646.
-
期刊类型引用(4)
1. 王泰基. 基于ITLBO-AFSA优化FCM算法的矿井图像增强. 工矿自动化. 2024(S1): 25-28 .  本站查看
本站查看
2. 张立辉. 基于损失函数优化神经网络模型的面罩遮挡人脸识别算法. 工矿自动化. 2024(S1): 15-20 . 本站查看
3. 王启飞,赵逸涵,刘帅,刘昊霖,孙英峰,李成武. 煤矿事故大数据驱动的风险治理模式研究综述. 中国安全科学学报. 2024(07): 28-37 . 百度学术
4. 李盟,马晓燕. 基于YOLOv5的关键区域人脸检测系统设计. 自动化与仪器仪表. 2024(10): 24-28 . 百度学术
其他类型引用(5)



计量
- 文章访问数: 147
- HTML全文浏览量: 114
- PDF下载量: 38
- 被引次数: 9
