
Massive data mining and analysis platform design for fully mechanized working face
-
摘要: 当前综采工作面海量数据采集的实时性和完整性差、异常数据清洗耗时大、数据挖掘时延大,导致综采数据利用率低,无法辅助管理层实时下发决策指令。针对上述问题,设计了一种综采工作面海量数据挖掘分析平台。该平台由数据源层、数据采集存储层、数据挖掘层和前端应用层组成。数据源层由工作面各类硬件设备提供原始数据;数据采集存储层使用OPC UA网关实时采集井下传感器监测信息,再通过MQTT协议和RESTful接口将数据存入InfluxDB存储引擎;数据挖掘层利用Hive数据引擎和Yarn资源管理器筛选数据采集过程中受工作现场干扰形成的异常数据,解决因网络延时导致的数据局部采集顺序紊乱问题,并利用Spark分布式挖掘引擎挖掘工作面设备群海量工况数据的潜在价值,提高数据挖掘模型的运行速度;前端应用层利用可视化组件与后端数据库关联,再通过AJAX技术与后端数据实时交互,实现模型挖掘结果和各类监测数据的可视化展示。测试结果表明,该平台能够充分保证数据采集的实时性与完整性,清洗效率较单机MySQL查询引擎提升5倍,挖掘效率较单机Python挖掘引擎提升4倍。Abstract: The current real-time and integrity of massive data acquisition in fully mechanized working faces are poor. The abnormal data cleaning takes a long time. The data mining delays are large. This leads to low utilization rate of fully mechanized working data and incapability to assist management in issuing decision-making instructions in real-time. In order to solve the above problems, a massive data mining and analysis platform for fully mechanized working faces is designed. The platform consists of a data source layer, a data acquisition and storage layer, a data mining layer, and a front-end application layer. The data source layer is provided with raw data by various hardware devices on the working surface. The data acquisition and storage layer uses the OPC UA gateway to collect real-time monitoring information from underground sensors, and then stores the data in the InfluxDB storage engine through the MQTT protocol and RESTful interface. The data mining layer uses the Hive data engine and Yarn resource manager to filter out abnormal data caused by workplace interference during the data acquisition process. It solves the problem of local data acquisition order disorder caused by network latency. The Spark distributed mining engine is used to explore the potential value of massive working condition data in the working face device group, improving the running speed of the data mining model. The front-end application layer utilizes visual components to associate with the back-end database. It interacts with the back-end data in real-time through AJAX technology to achieve visual display of model mining results and various monitoring data. The test results show that the platform can fully ensure the real-time and integrity of data acquisition. The cleaning efficiency is 5 times better than a standalone MySQL query engine and the mining efficiency is 4 times better than a standalone Python mining engine.
-
Keywords:
- fully mechanized working face /
- massive data /
- data mining /
- data acquisition /
- data storage /
- data cleaning /
- data visualization
-
0. 引言
煤矿智能化是煤炭工业高质量发展的核心技术支撑[1]。综采工作面的智能化改造能够改善井下从业人员生产环境、降低工作难度,促进煤炭安全高效开采[2-3]。海量数据挖掘分析是综采工作面智能化的重要组成部分,对实现综采数据高效利用具有重要意义[4-8]。
许多学者利用人工智能技术挖掘综采工作面设备群海量数据的潜在价值。文献[9-11]根据采煤机里程数据和位姿数据预测采煤机截割曲线,形成了基于动态调整的采煤机智能截割模型,达到了初步的自主割煤。文献[12-13]先将液压支架动作和压力的异常数据进行筛选,对数据进行分析后生成液压支架跟机总体满意度决策模型,根据满意度调整液压支架控制策略。文献[14-16]对综采设备运转过程传感数据(如振动、声发射、油压等)先进行深度特征提取,利用深度迁移学习生成诊断模型,再根据不断采集的数据优化网络参数,提升了综采设备诊断模型的准确率。但由于综采工作面单位时间内数据采集体量大,易受短时电磁干扰等影响[17],无法保证数据采集的实时性与完整性,容易在采集过程中出现异常数据[18-19]。同时,以上研究均通过传统单机计算引擎进行数据的清洗和挖掘分析,读写效率和计算性能的限制使得数据清洗和模型构建速度缓慢[20],导致决策指令下发具有滞后性,限制了模型从实验室到工作现场实际应用的进一步转换[21]。
针对上述问题,本文提出一种综采工作面海量数据挖掘分析平台设计方案。通过OPC UA(OLE for Process Control Unified Architecture,用于过程控制的OLE统一架构)网关和MQTT协议实现工作面各类数据的实时性采集和分类存储;利用Hive数据引擎和Yarn资源管理器清洗采集过程中的异常数据;通过Spark分布式挖掘引擎发布数据挖掘模型,解决因计算量过大导致数据挖掘模型在传统单机计算引擎上运行速度过慢的问题;通过前端可视化技术实现模型挖掘结果和各类监测数据的可视化展示。
1. 平台总体架构
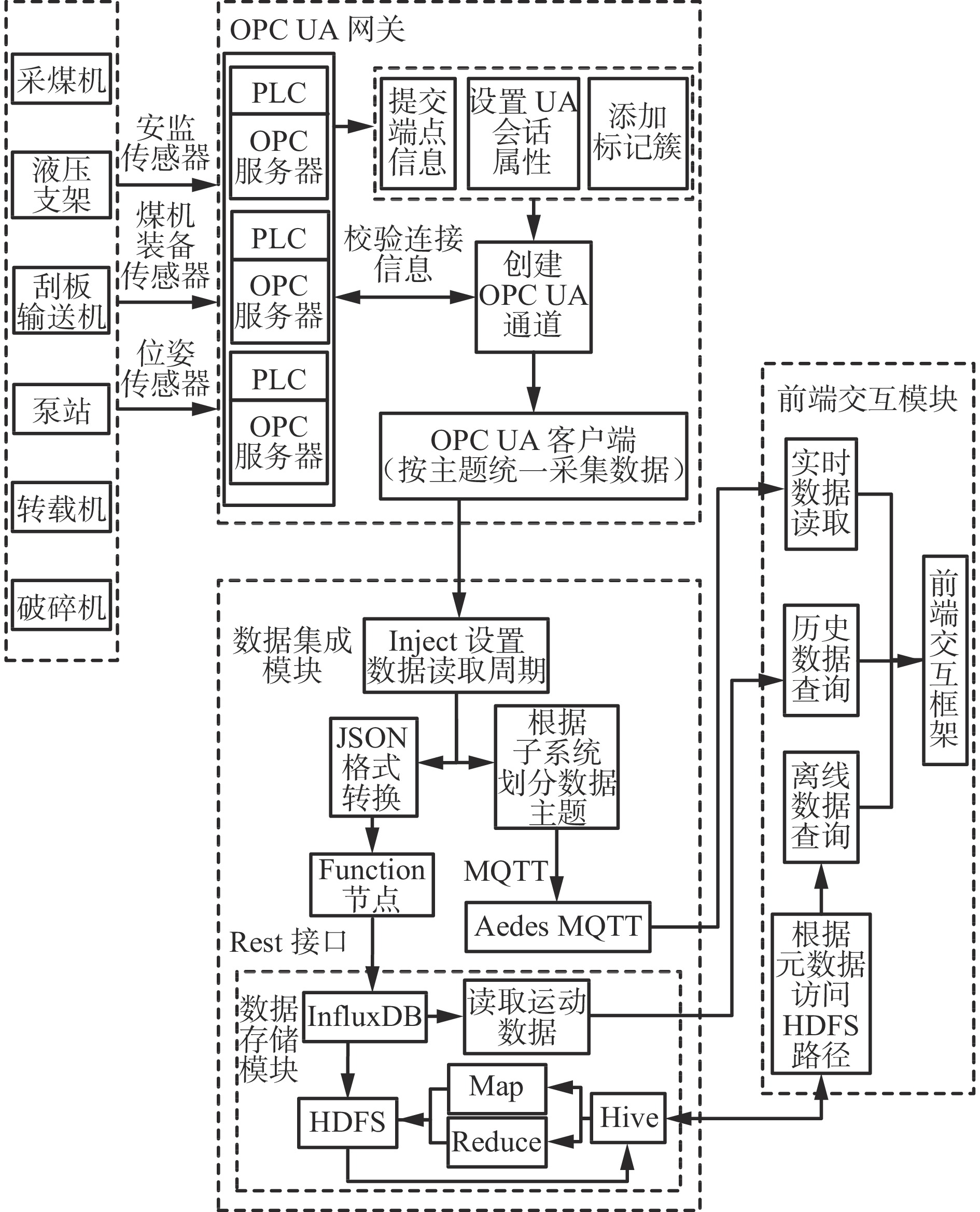
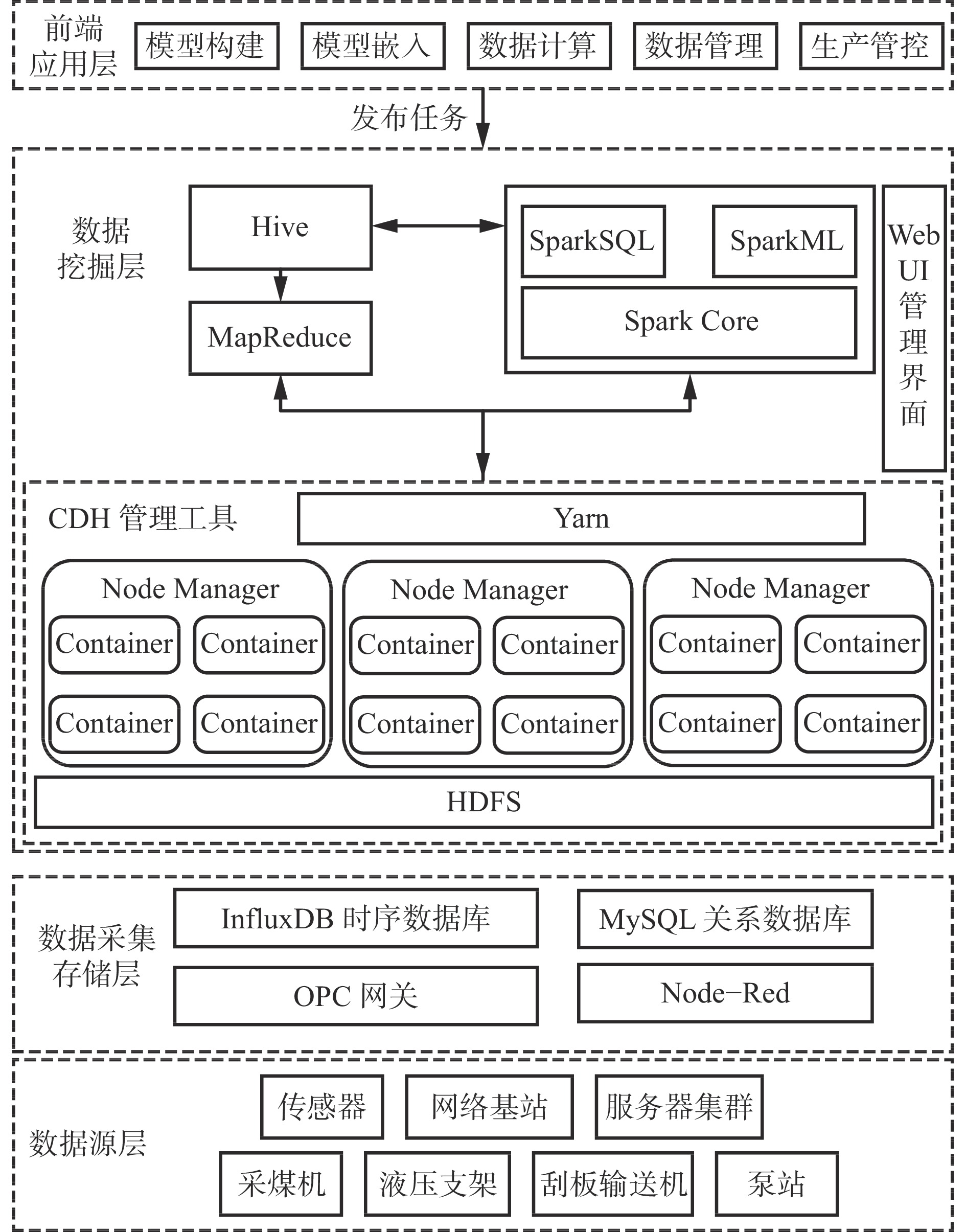
综采工作面海量数据挖掘分析平台由数据源层、数据采集存储层、数据挖掘层、前端应用层组成,如图1所示。
![]() 图 1 综采工作面海量数据挖掘分析平台总体架构Figure 1. Overall architecture of massive data mining and analysis platform for fully mechanized working face
图 1 综采工作面海量数据挖掘分析平台总体架构Figure 1. Overall architecture of massive data mining and analysis platform for fully mechanized working face数据源层由各类子系统硬件资源(采煤机、液压支架、刮板输送机、泵站等)、传感器、网络基站及服务器集群等组成。该层负责工作面各种设备状态监测传感器、音视频采集器的状态感知,提供可扩展的存储和分布式计算资源,为工作面智能化建设积累原始数据,提供数据底座。
数据采集存储层负责数据源层海量数据的采集与存储。井下设备通过RS485/以太网/CAN等通信总线将传感器监测信息传输至PLC,但井下设备大部分通信协议不同,因此使用OPC UA网关通过各厂商PLC通信协议建立与对应型号PLC的连接,实现PLC寄存器数值的实时监测,通过MQTT协议实现实时数据的推送和订阅。时序数据通过在Node−Red中集成RESTful接口存入InfluxDB存储引擎,通过采样和数据保留策略,将高价值、高精度数据存储在内存,将低价值数据存储在磁盘。通过后端集成FFmpeg视频拉流插件,将井下本安型摄像头的RTSP视频流协议转换为RTMP协议接入平台前端界面实时显示。通过前端JavaWeb表单提交基础业务数据,后端调用数据库API建立连接后写入MySQL关系数据库。
数据挖掘层是整个平台的核心层。该层由CDH(Cloudera's Distribution Including Apache Hadoop)管理工具、Hive数据引擎[22]和Spark分布式挖掘引擎[23]构成。数据挖掘层向下需完成分散于各个系统的多源异构数据的汇聚与清洗,实现数据的统一高效管理,为上层数据驱动的数据挖掘模型提供数据基础;向上需将前端应用层发布的任务划分为各个子流程,为每个流程分配相应的硬件资源以供调度,通过调用人工智能算法库进行分布式挖掘,提高挖掘速度。CDH管理工具是Cloudera的开源版本,相比传统手动部署Hadoop集群过程复杂、兼容性差、升级过程繁琐等缺陷,具有自动化部署、集群监控等优势,大大缩减了集群部署时间,降低了后期运维难度,提高了集群管理效率。Hive数据引擎能够用于数据的提取、转换和加载,客户端编写的HQL语句通过Driver驱动器映射为抽象层次较低的MapReduce作业,Node Manager根据作业复杂度划分多个子流程,并为每个子流程分配Container并行运算,这样既能简化开发人员编程难度,提高开发效率,又解决了传统单服务器清洗大规模数据高延迟问题。Spark是基于内存计算的分布式计算框架,通过函数式编程将数据缓存在内存中,解决了MapReduce在进行迭代式计算时需从磁盘重复读取和写入数据的问题,同时提供大量算子(如filter,map,flatMap)和机器学习常用算法库(Spark MLlib,BigDL等),实现工作面大批量工况数据的并行化挖掘。
前端应用层具有传统业务数据管理和模型开发应用功能。将各类子系统管控界面与后端数据库连接,实现实时交互,完成对综采工作面诸如安全管理、生产经营等数据的感知任务。该层同时提供数据模型开发利用功能,通过加载分布式文件系统的数据挖掘模型,设置调度参数,以最直观的方式展现挖掘结果,为管理者下发决策策略提供强有力的辅助与支撑。
2. 平台关键技术
2.1 海量数据实时采集存储技术
工作面传统数据采集系统的数据协议不一且易受现场环境扰动,无法保证数据采集的实时性与完整性,因此使用海量数据采集存储技术完成工作面海量数据的初步汇聚与累积,技术实现流程如图2所示。
![]() 图 2 海量数据采集存储技术实现流程Figure 2. Massive data acquisition and storage technology implementation process
图 2 海量数据采集存储技术实现流程Figure 2. Massive data acquisition and storage technology implementation process采用OPC UA网关统一各类采集设备的传输协议和数据格式。数据集成模块采用Node.js架构,通过集成OPC UA所需API,将客户端封装成功能节点,提供节点的复用功能。通过向服务器端提交端点信息和会话属性建立OPC UA通道,根据服务器中已设置完成的变量标记名读取指定OPC UA服务器中寄存的实时数据,完成数据的初步采集工作。
针对各类数据前端访问的时效性差异问题,需将数据格式进一步分类处理,客户端读取数据成功后,通过设置inject节点读取数据周期,不间断地调用read方法持续向服务器读取数据,并将每次读取的数据进行格式转换;通过JSON转换节点使用insert方法将单位时间内采集到的所有数据转换为JSON格式,根据子系统数据源类型内层嵌套JSON对象,利用function节点编写JavaScript脚本依次遍历所有JSON对象,获取当前对象所有属性后重新封装;利用push方法将单位时间获取的各类子系统数据源JSON对象封装在统一数组中,并通过RESTful请求分别存入不同数据库中。根据数据访问频次和数据类别(实时数据、历史数据、业务数据、非结构化数据)及响应时间来实现数据分类存储,支撑前端实时预警和历史数据挖掘分析等需求。需实时返回查询结果的数据由MQTT推送节点根据数据源设置发布主题后存入MQTT代理服务器,前端通过消息订阅节点订阅主题后读取消息内容,在占用极少带宽的条件下实现稳定可靠的数据实时显示。近期历史数据设置存储路径和相应端口后通过POST请求存入时序数据库InfluxDB。离线数据及非结构化数据通过集成HDFS的上传、下载等指令API,将文件根据指定大小拆分为多个块后存入大数据分布式集群HDFS文件系统中。
2.2 海量数据清洗技术
受井下恶劣工作环境影响,生产过程中各类采集设备受扰动严重,使得各类监测数据夹杂众多异常值,若不加以清洗,会占用太多硬件资源,导致后期数据挖掘模型准确率低、实际应用效果差等问题。
利用大数据组件Hive数据引擎,使用HQL语句编写数据处理条件,通过where条件筛选先剔除不符合实际工况数据的异常值和缺失值,再根据时间粒度统计每段时间内各类数据的采集频次、总值和均值,创建包含以上属性的新数据表,将HQL通过语义解析并优化逻辑执行计划后生成MapReduce任务,提交至Yarn资源管理器执行批处理程序,待清洗过程执行完成后使用insert方法将所有数据存入新数据表并导入HDFS分布式文件系统中。同时将数据表元数据存入MySQL,下次访问可直接根据文件存储路径读取该表内容,避免生成新的MapReduce批处理程序,从而提高数据查询的响应速度,保证后期数据建模运行准确率的同时节省服务器存储空间。
2.3 海量数据挖掘技术
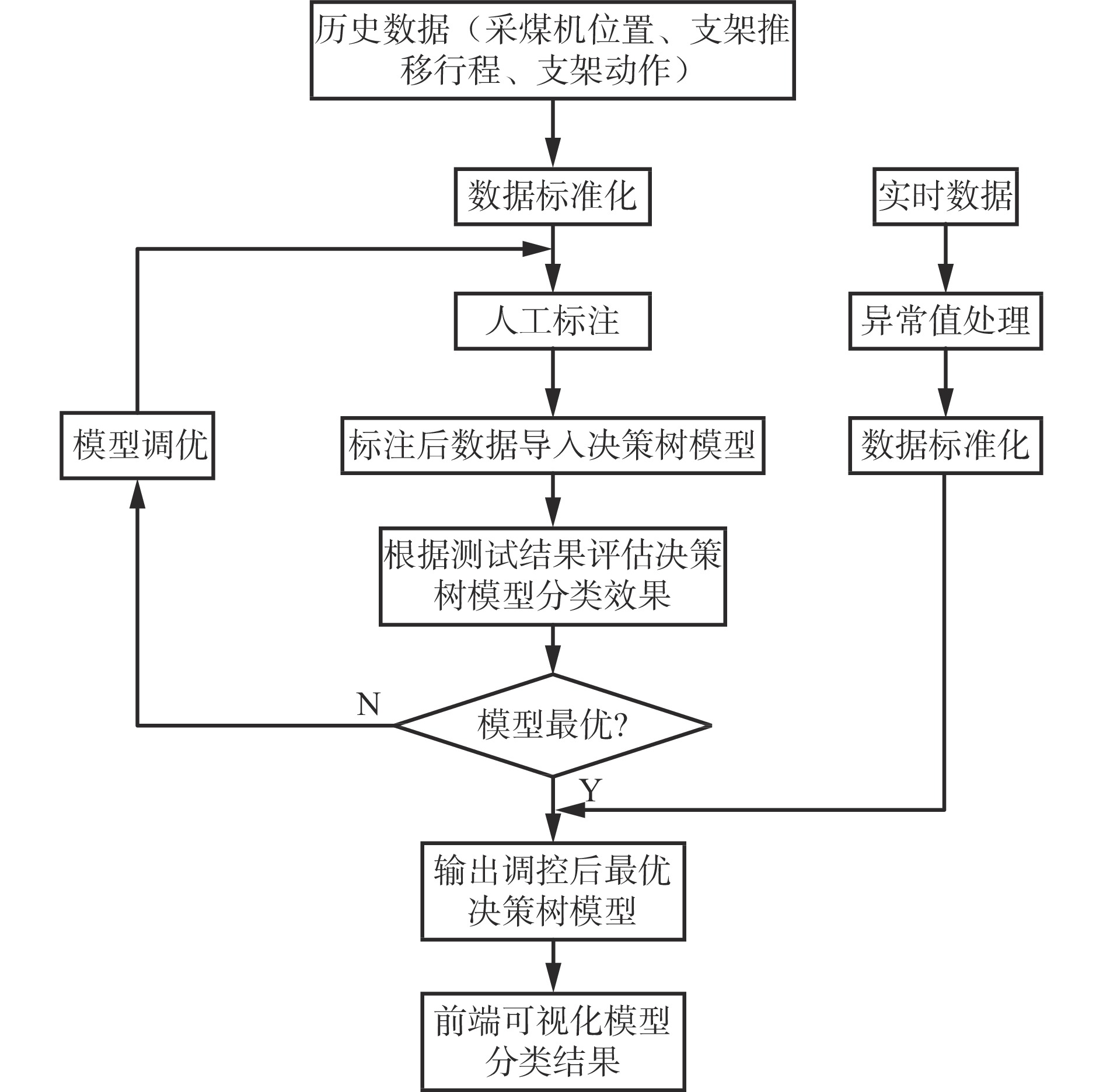
针对传统单机计算引擎无法高效处理工作面海量高价值、低密度工况数据的问题,使用海量数据挖掘技术实现数据挖掘模型在实际生产中的实时调度,技术实现流程如图3所示。
在前端通过低代码编程技术实现可视化组件与数据预处理、机器学习算子的相互映射,屏蔽程序编写过程中的复杂配置和实现原理,之后使用拖拽的方式构建数据挖掘模型。
根据模型数据源体量及任务计算复杂度灵活选择运算方式——单机模式或集群模式。单机模式通过后端集成Python应用接口,前端编写Python代码或上传已经训练好的Pickle模型至本地文件系统,调用本地Python环境进行挖掘。集群模式基于Spark分布式挖掘引擎和Yarn资源调度器进行分布式计算,前端发布数据挖掘模型后,通过SparkSubmit方法打包数据挖掘模型并设置MASTER_URL与DEPLOY_MODE参数,将应用程序提交至后端Yarn部署的分布式集群。任务提交后Resource Manager节点根据任务需求和运行参数划分计算资源,资源申请成功后反向发送心跳定时汇报节点在线状态,同时向资源调度节点Driver反向注册完成初始化并开始执行程序主函数。根据DGA(Directed Acyclic Graph,有向无环图)原则按顺序执行子流程,再根据宽依赖为每段子流程划分TaskSet,通过TaskScheduler将任务提交至执行节点Executor上运行,待所有子流程全部处理完成后,通过TaskRunner方法向Driver节点汇报任务执行状态和执行结果,并将结果返回至前端可视化,最终释放所有计算资源,结束程序运行。
数据挖掘完成后,根据训练结果并通过人工干预调整参数进行模型调优,最终将生成的模型通过PipelineMode方法保存为PMML(Predictive Model Markup Language,预测模型标记语言)跨平台文件后存储至分布式文件系统中。
2.4 前端实时可视化技术
前端应用层基于Java前端框架开发工作面智能管控界面,通过后端集成平台各类数据库API,利用气泡图、热力图、实时线性图等可视化组件关联后端数据库,通过AJAX(Asynchronous JavaScript and XML,异步JavaScript和XML)前后端交互技术定时与后端数据交互并更新部分前端内容,远程通过井上煤矿智能管控中心实时查看各类设备状态和井下人员位置等信息。
通过关联后端开发组件构建数据挖掘任务,将任务提交至流程引擎生成后端编程代码,根据调度周期及其他环境参数设计HTML(Hyper Text Markup Language,超文本标记语言)提交表单,人工输入各类调度参数并提交至后端定时调度数据挖掘模型,对新的实时数据进行模型应用,通过可视化界面将设备运行状态反馈给管理层及时调整决策策略。
3. 平台测试
为验证综采工作面海量数据挖掘分析平台的数据采集存储、数据清洗、数据挖掘等性能,在山西某矿部署该平台,以该矿某工作面2023年2月的液压支架工况数据为例,对平台各项功能进行测试。
3.1 平台搭建
平台硬件由3台R750XS服务器组成,其中1台作为主节点,另外2台作为从节点,服务器均搭载32核的5218型中央处理器及64 GiB内存和1 TiB固态硬盘。平台软件选择兼容性强且稳定性高的CentOS7.6操作系统。使用CDH管理工具搭建Hadoop分布式集群,同时在主节点部署适配版本的Hive和Spark,从节点负责数据存储与计算功能的实现。
3.2 数据采集存储性能分析
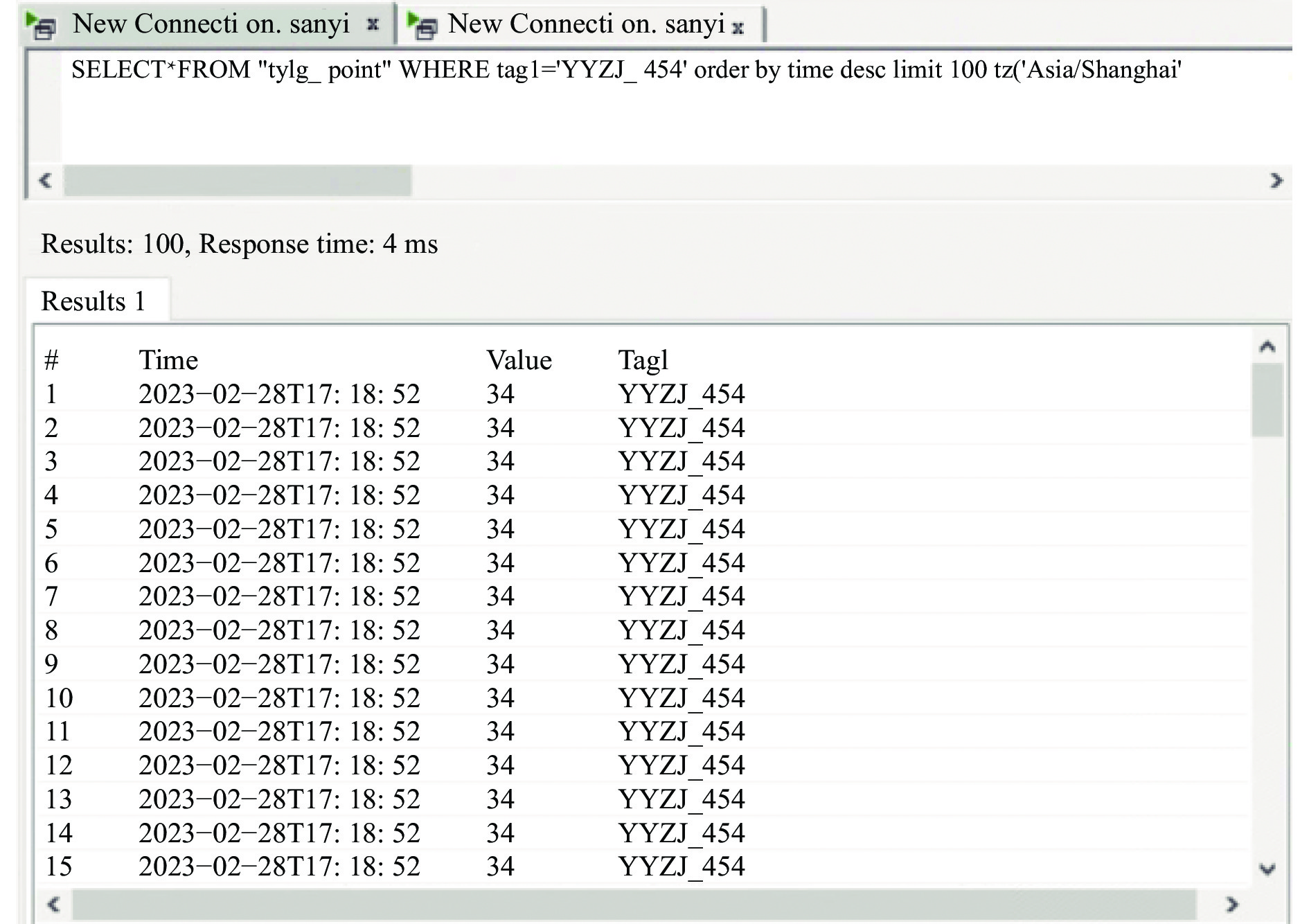
为验证平台的数据采集存储性能,设置数据采集周期为200 ms,对某工作面液压支架立柱压力数据进行采集与加载,通过数据库可视化编程界面随机查询在2月28号采集到的某液压支架立柱压力数据,查询结果如图4所示。通过Time字段的时间戳能看到每秒内进行5次数据采集,通过Value字段可看到采集过程中没有出现缺失值,不会因为网络延时和网络阻塞导致数据漏采、局部采集顺序紊乱等问题,充分保证了数据采集过程的实时性与完整性,满足工作面各类监测数据采集的实际需求。
3.3 数据清洗性能分析
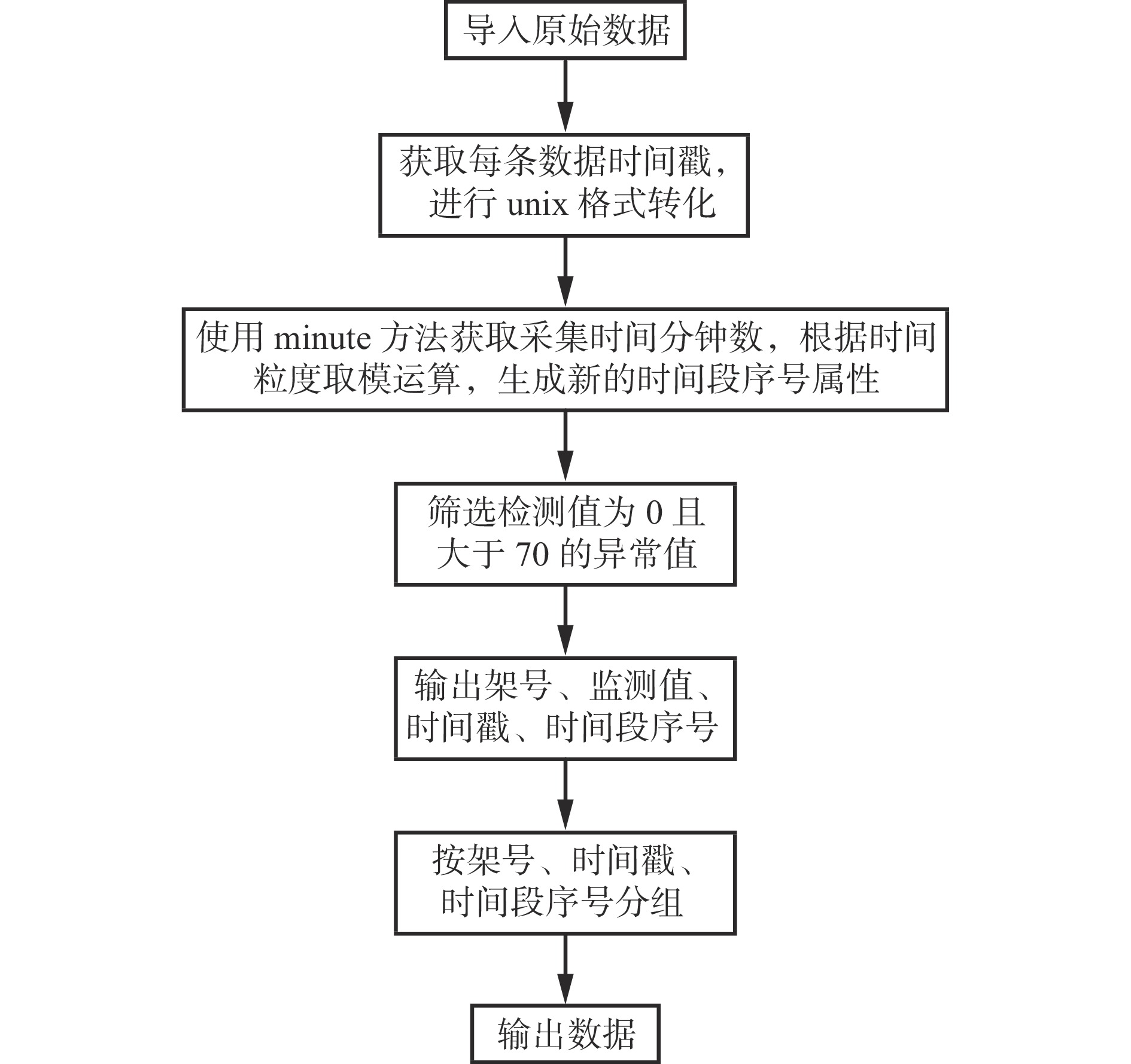
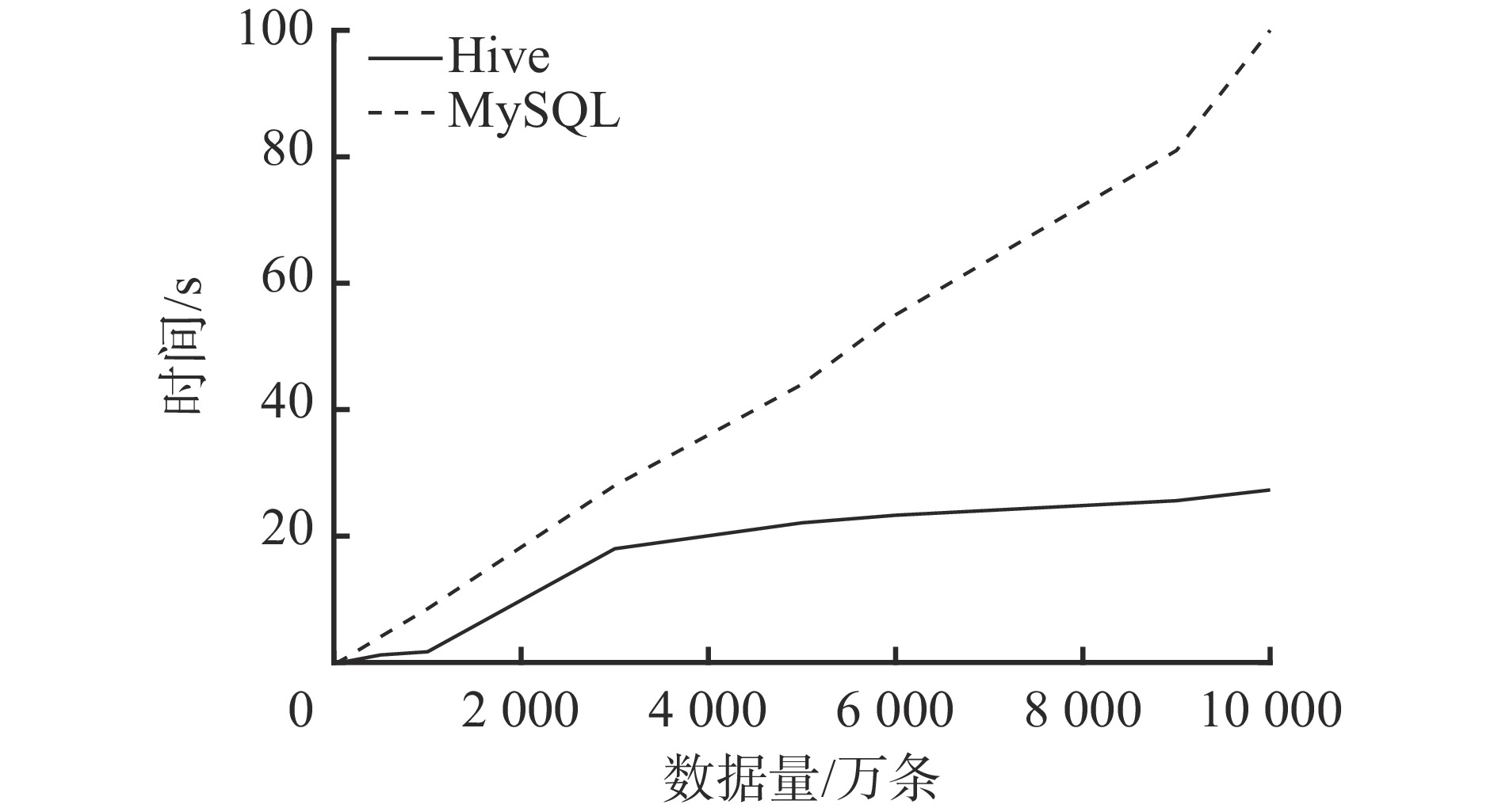
为验证平台数据清洗性能,分别使用平台中Hive数据引擎和单机MySQL查询引擎[24]对不同体量数据清洗速度进行对比测试,测试流程如图5所示,测试结果如图6所示。
从图6可看出,当数据量在10万条到2千万条区间内,Hive数据引擎和单机MySQL查询引擎的数据清洗时间相差不大,均维持在20 s左右;随着数据量的增加,单机MySQL查询引擎的数据清洗时间呈线性增长趋势,而Hive数据引擎的数据清洗时间可维持在30 s内,清洗效率约为单机MySQL查询引擎的5倍。
3.4 数据挖掘性能分析
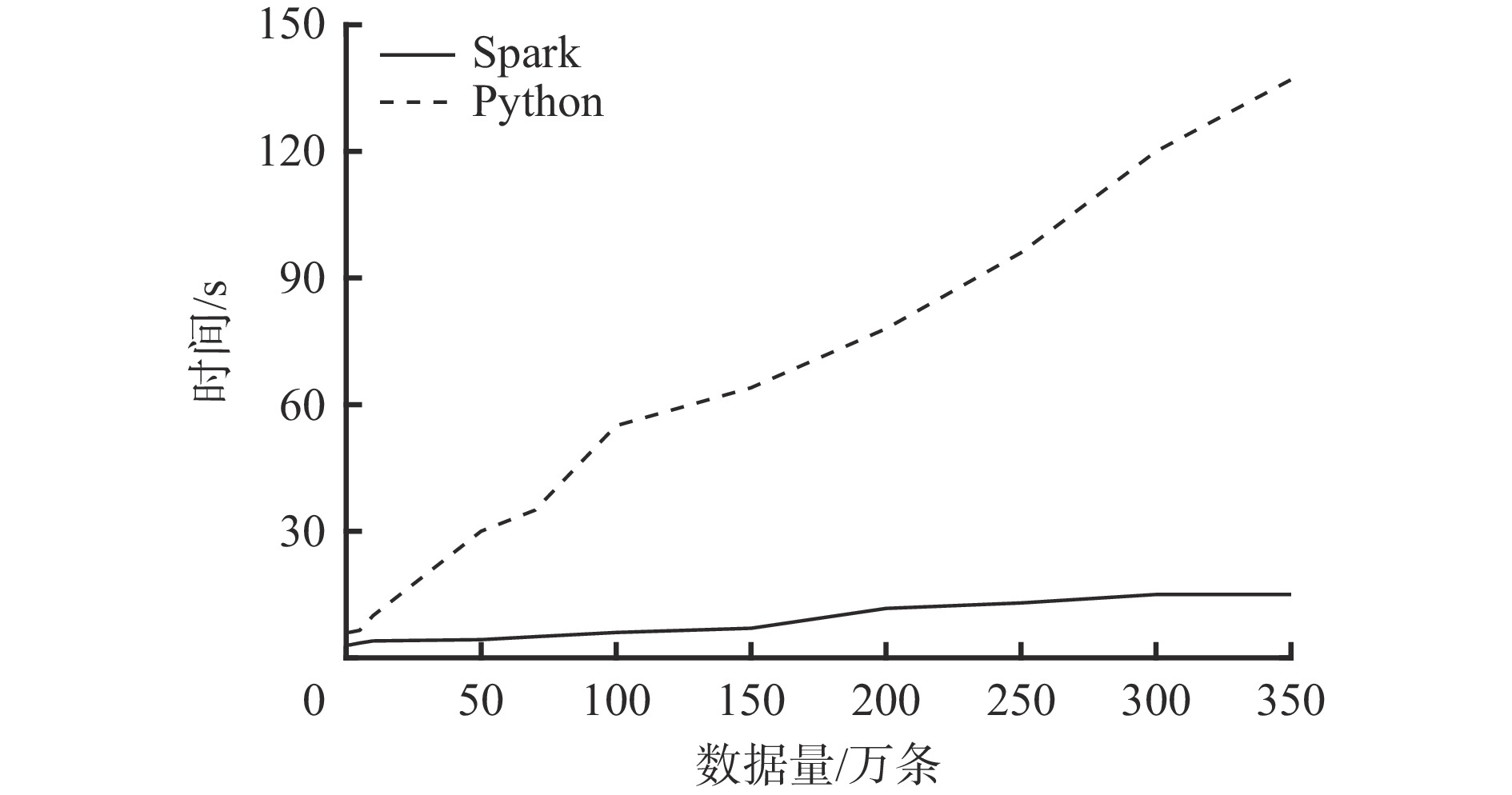
为验证平台的数据挖掘性能,分别使用平台中Spark分布式挖掘引擎和单机Python挖掘引擎[25]对不同体量数据挖掘速度进行对比测试,测试流程如图7所示,测试结果如图8所示。
从图8可看出,当数据量在10万条以内时,Spark分布式挖掘引擎和单机Python挖掘引擎的数据挖掘时间均可维持在10 s内;当数据量增加至100万条时,单机Python挖掘引擎的数据挖掘时间为60 s,挖掘速度过慢;当数据量增加至200万条时,Spark分布式挖掘引擎的数据挖掘时间依然能稳定在20 s左右,数据挖掘效率是单机Python挖掘引擎的4倍。
4. 结语
综采工作面海量数据挖掘分析平台使用OPC UA网关和MQTT协议保证了综采工作面海量数据采集过程中的实时性与完整性;利用Hive数据引擎筛选海量数据中的异常值,为后期数据建模提供了准确数据,提高了综采数据清洗能力;使用Spark分布式挖掘引擎高效挖掘工作面高价值、低密度的海量工况数据,满足了现实生产过程中数据挖掘模型的实时应用。
由于该平台设计尚处于起步阶段,目前仅对井下设备工况数据进行采集分析,今后需完善多源异构数据(音频、视频等数据)的存储利用,增加音视频处理技术,实现对工作面多源异构数据的整体挖掘利用。
-
![]()
图 1 综采工作面海量数据挖掘分析平台总体架构
Figure 1. Overall architecture of massive data mining and analysis platform for fully mechanized working face
![]()
图 2 海量数据采集存储技术实现流程
Figure 2. Massive data acquisition and storage technology implementation process
-
[1] 王国法,赵国瑞,任怀伟. 智慧煤矿与智能化开采关键核心技术分析[J]. 煤炭学报,2019,44(1):34-41. WANG Guofa,ZHAO Guorui,REN Huaiwei. Analysis on key technologies of intelligent coal mine and intelligent mining[J]. Journal of China Coal Society,2019,44(1):34-41.
[2] LIU Xianglan. Digital construction of coal mine big data for different platforms based on life cycle[C]. IEEE 2nd International Conference on Big Data Analysis, Beijing, 2017: 456-459.
[3] 李福兴,李璐爔. 面向煤炭开采的大数据处理平台构建关键技术[J]. 煤炭学报,2019,44(增刊1):362-369. LI Fuxing,LI Luxi. Key technologies of big data processing platform construction for coal mining[J]. Journal of China Coal Society,2019,44(S1):362-369.
[4] 杜毅博,赵国瑞,巩师鑫. 大数据关键技术在智能化煤矿中的应用与发展[J]. 煤炭科学技术,2020,48(7):177-185. DU Yibo,ZHAO Guorui,GONG Shixin. Study on big data platform architecture of intelligent coal mine and key technologies of data processing[J]. Coal Science and Technology,2020,48(7):177-185.
[5] 王国法,王虹,任怀伟,等. 智慧煤矿2025情景目标和发展路径[J]. 煤炭学报,2018,43(2):295-305. DOI: 10.13225/j.cnki.jccs.2018.0152 WANG Guofa,WANG Hong,REN Huaiwei,et al. 2025 scenarios and development path of intelligent coal mine[J]. Journal of China Coal Society,2018,43(2):295-305. DOI: 10.13225/j.cnki.jccs.2018.0152
[6] 崔卫锋,田野,李旭,等. 煤矿综采工作面智能服务大数据决策平台[J]. 煤矿机械,2022,43(10):177-195. CUI Weifeng,TIAN Ye,LI Xu,et al. Intelligent service big data decision-making platform for fully mechanized mining face in coal mine[J]. Coal Mine Machinery,2022,43(10):177-195.
[7] 谭章禄,王美君. 智慧矿山数据治理概念内涵、发展目标与关键技术[J]. 工矿自动化,2022,48(5):6-14. DOI: 10.13272/j.issn.1671-251x.2021120090 TAN Zhanglu,WANG Meijun. Research on the concept connotation,development goal and key technologies of data governance for smart mine[J]. Journal of Mine Automation,2022,48(5):6-14. DOI: 10.13272/j.issn.1671-251x.2021120090
[8] 葛世荣. 煤矿智采工作面概念及系统架构研究[J]. 工矿自动化,2020,46(4):1-9. GE Shirong. Research on concept and system architecture of smart mining workface in coal mine[J]. Industry and Mine Automation,2020,46(4):1-9.
[9] 李首滨,李森,张守祥,等. 综采工作面智能感知与智能控制关键技术与应用[J]. 煤炭科学技术,2021,49(4):28-39. LI Shoubin,LI Sen,ZHANG Shouxiang,et al. Key technology and application of intelligent perception and intelligent control in fully mechanized mining face[J]. Coal Science and Technology,2021,49(4):28-39.
[10] 苏杰,王新坤. 寸草塔煤矿综采工作面智能化建设关键技术研究与应用[J]. 煤炭科学技术,2022,50(增刊1):250-256. SU Jie,WANG Xinkun. Research and application of key technologies for intelligent construction of fully mechanized mining face in Cuncaota Coal Mine[J]. Coal Science and Technology,2022,50(S1):250-256.
[11] 贺海涛. 综采工作面智能化开采系统关键技术[J]. 煤炭科学技术,2021,49(增刊1):8-15. HE Haitao. Key technology of intelligent mining system in fully-mechanized mining face[J]. Coal Science and Technology,2021,49(S1):8-15.
[12] 徐亚军,张坤,李丁一,等. 超前支架自适应支护理论与应用[J]. 煤炭学报,2020,45(10):3615-3624. XU Yajun,ZHANG Kun,LI Dingyi,et al. Theory and application of self-adaptive support for advanced powered support[J]. Journal of China Coal Society,2020,45(10):3615-3624.
[13] 付翔,王然风. 工作面供液系统与液压支架协同自适应控制模型设计[J]. 采矿与岩层控制工程学报,2020,2(3):90-98. FU Xiang,WANG Ranfeng. Cooperative self-adaptive control model of fluid feeding system and hydraulic supports in working face[J]. Journal of Mining and Strata Control Engineering,2020,2(3):90-98.
[14] 宫文峰, 张美玲, 陈辉. 基于深度学习的旋转机械大数据智能故障诊断方法[J/OL]. 计算机集成制造系统: 1-21[2023-04-21]. http://kns.cnki.net/kcms/detail/11.5946.TP.20220612.0910.004.html. GONG Wenfeng, ZHANG Meiling, CHEN Hui. Intelligent fault diagnosis method based on deep learning of rotating machinery under big data[J/OL]. Computer Integrated Manufacturing Systems: 1-21[2023-04-21]. http://kns.cnki.net/kcms/detail/11.5946.TP.20220612.0910.004.html.
[15] 丁恩杰,俞啸,廖玉波,等. 基于物联网的矿山机械设备状态智能感知与诊断[J]. 煤炭学报,2020,45(6):2308-2319. DOI: 10.13225/j.cnki.jccs.zn20.0340 DING Enjie,YU Xiao,LIAO Yubo,et al. Key technology of mine equipment state perception and online diagnosis under Internet of things[J]. Journal of China Coal Society,2020,45(6):2308-2319. DOI: 10.13225/j.cnki.jccs.zn20.0340
[16] 雷亚国,杨彬,杜兆钧,等. 大数据下机械装备故障的深度迁移诊断方法[J]. 机械工程学报,2019,55(7):1-8. DOI: 10.3901/JME.2019.07.001 LEI Yaguo,YANG Bin,DU Zhaojun,et al. Deep transfer diagnosis method for machinery in big data era[J]. Journal of Mechanical Engineering,2019,55(7):1-8. DOI: 10.3901/JME.2019.07.001
[17] 谢嘉成,王学文,杨兆建. 基于数字孪生的综采工作面生产系统设计与运行模式[J]. 计算机集成制造系统,2019,25(6):1381-1391. XIE Jiacheng,WANG Xuewen,YANG Zhaojian. Design and operation mode of production system of fully mechanized coal mining face based on digital twin theory[J]. Computer Integrated Manufacturing Systems,2019,25(6):1381-1391.
[18] 张科学,徐兰欣,李旭,等. 透明工作面智能化开采大数据分析决策方法及系统研究[J]. 煤炭科学技术,2022,50(2):252-262. ZHANG Kexue,XU Lanxin,LI Xu,et al. Research on big data analysis and decision system of intelligent mining in transparent working face[J]. Coal Science and Technology,2022,50(2):252-262.
[19] 李重重,刘清,刘军锋,等. 面向综采工作面的自动化软件设计与应用[J]. 工矿自动化,2023,49(3):124-130. LI Zhongzhong,LIU Qing,LIU Junfeng,et al. Automation software design and application for fully mechanized working face[J]. Journal of Mine Automation,2023,49(3):124-130.
[20] 李佳,徐胜超. 基于云计算的智能电网大数据处理平台[J]. 计算机工程与设计,2018,39(10):3073-3079. LI Jia,XU Shengchao. Smart power system big data processing platform in cloud environments[J]. Computer Engineering and Design,2018,39(10):3073-3079.
[21] 王万良,张兆娟,高楠,等. 基于人工智能技术的大数据分析方法研究进展[J]. 计算机集成制造系统,2019,25(3):529-547. WANG Wanliang,ZHANG Zhaojuan,GAO Nan,et al. Progress of big data analytics methods based on artificial intelligence technology[J]. Computer Integrated Manufacturing Systems,2019,25(3):529-547.
[22] JIANG Dingde,WANG Yuqing,LYU Zhihan,et al. Big data analysis based network behavior insight of cellular networks for industry 4.0 applications[J]. IEEE Transactions on Industrial Informatics,2019,16(2):1310-1320.
[23] ZAHARIA M,XIN R S,WENDELL P,et al. Apache spark:a unified engine for big data processing[J]. Communications of the Acm,2016,59(11):56-65. DOI: 10.1145/2934664
[24] 罗广恒. 基于Django和MySQL的网络化测试数据查询系统研究[J]. 智能物联技术,2019,51(2):15-21,31. LUO Guangheng. Research on measure data networking query system based on Django and MySQL[J]. Technology of IoT & AI,2019,51(2):15-21,31.
[25] 张锦涛,付翔,王然风,等. 智采工作面中部液压支架集群自动化后人工调控决策模型[J]. 工矿自动化,2022,48(10):20-25. ZHANG Jintao,FU Xiang,WANG Ranfeng,et al. Manual regulation and control decision model of middle hydraulic support cluster automation in the intelligent working face[J]. Journal of Mine Automation,2022,48(10):20-25.
-
期刊类型引用(4)
1. 张薇. 基于谱聚类的时序数据局部离群点挖掘方法. 吕梁学院学报. 2025(02): 47-51 .  百度学术
百度学术
2. 徐琳,贺铮,李行,任文辉,张昊. 能源工业互联网海量数据采集方法研究. 电气自动化. 2024(05): 88-90+94 . 百度学术
3. 杨舒涵. 基于数据挖掘的行业价值分析在创业教育中的应用. 中国新技术新产品. 2023(16): 33-35 . 百度学术
4. 李扬. 基于机器学习算法的水煤浆提浓废水絮凝处理加药预测. 智能物联技术. 2023(06): 21-27 . 百度学术
其他类型引用(2)
 下载:
下载:

计量
- 文章访问数: 1061
- HTML全文浏览量: 82
- PDF下载量: 96
- 被引次数: 6
