裴浩1, 游小荣1, 牛欣伟2
(1.常州纺织服装职业技术学院 机电工程系, 江苏 常州 213164;2.宾州州立大学 伊利比伦德学院 工程学院, 宾夕法尼亚州 伊利 16563)
摘要:分析了三维空间数据距离直方图算法的性质及数据结构,提出了基于图形处理器的通用计算方法和基于FPGA的高性能计算方法,基于图形处理器的计算方法可用于实现三维空间数据距离直方图算法的单指令多数据并行优化;基于FPGA的计算方法可实现算法的硬件分块优化,使算法的硬件结构达到最优匹配。实验结果表明,利用基于图形处理器的计算方法可使算法达到平均18倍的性能加速,基于FPGA的计算方法可使算法达到平均30倍的性能加速,大大提升了算法的数据处理能力。
关键词:数字矿山; 三维空间数据; 大数据; 距离直方图算法; 优化加速; GPU; FPGA
在“数字矿山”的发展要求下,矿山企业的数字化、信息化和三维可视化的建设已刻不容缓。矿山是分布于三维地理空间的地质实体,矿山的原始数据都是三维的[1]。在“数字矿山”的建设过程中,由于大量三维建模和三维可视化技术的应用,极大增加了三维空间实体的操作量,使得三维空间数据的几何运算量快速增长。三维空间数据具有复杂、海量、动态变化等特点,并且呈现空间点、线及面等多样化特征[2-3],符合大数据的主要特点[4-5]:Volume(海量数据)、Velocity(数据处理快速)、Variety(数据类型多样)和Value(数据价值高),对计算能力提出了更高的要求。
三维空间数据点是矿山三维建模的基础,处理算法主要有三维空间数据距离直方图算法、分割合并算法、三角网生长算法、逐点插入算法等。其中,三维空间数据距离直方图算法[6-7]作为基础算法,在矿山三维建模与可视化过程中应用广泛。由于三维空间数据距离直方图算法涉及大量数据计算,导致三维空间数据计算时间过长,存在计算复杂度较高、计算过程中需要占用较多的有限资源(CPU和内存)等问题,不能满足三维空间大数据的处理要求。为此,笔者在分析三维空间数据距离直方图算法基础上,提出了基于图形处理器(Graphics Processing Unit,GPU)的通用计算方法[8]和基于FPGA(Field-Programmable Gate Array,现场可编程门阵列)[9]的高性能并行计算方法,用于实现三维空间数据距离直方图算法的优化及加速,极大提升了算法的三维空间数据处理能力。
三维空间数据距离直方图算法被广泛应用于三维图像和视频数据处理、物理分子运算及三维数据模拟N-Body等[10-12],具有典型意义。它是根据三维空间点的数据坐标,计算任意2个空间点的矢量距离,根据距离值范围生成直方图,从而获得三维空间点的分布状态。
假设存在三维空间数据点集合Lattice [N](N为集合大小),元素Lattice [i]由三维空间矢量坐标(Xi,Yi,Zi)(i=1,2,…,N)表示,任意2个点Lattice[i]和Lattice[j]的空间距离为Di,j(j=1,2,…,N),判断Di,j的取值范围,生成直方图。Di,j计算公式如下:
(1)
随着N的增大,数据计算量也会呈N2增加,见表1。假设存在N=4的数据点集合Lattice((2,6,7),(-4,3,-5),(-3,-2,-1),(1,2,3)),计算任意2点的空间距离,所生成的直方图如图1所示。
表1 任意2点空间距离Di,j的计算

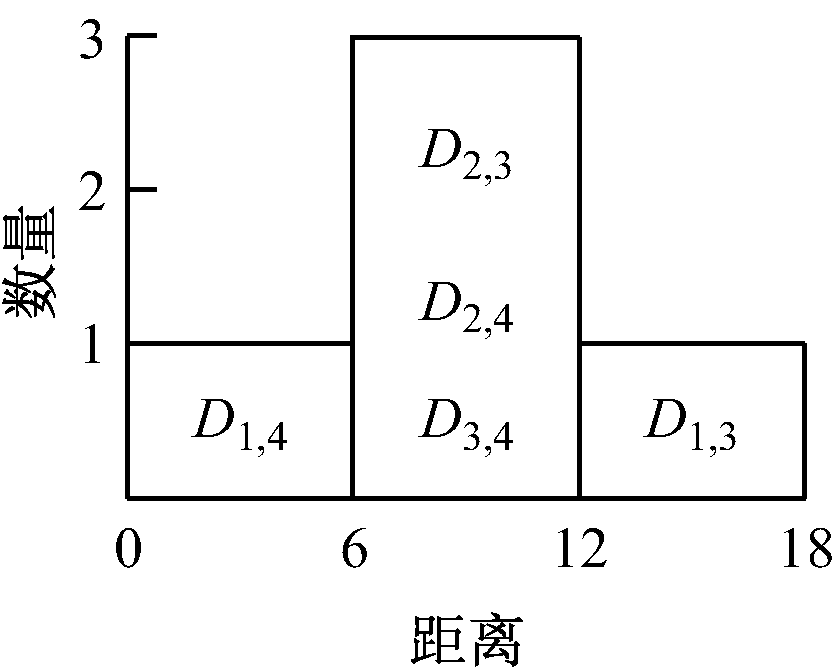
图1 三维空间点距离直方图
综上所述,算法的常规实现核心描述如下:
for(i=0;i<N;i++)
for(j=i+1;j<N;j++)
{
//计算Lattice[i]与Lattice[j]的距离
Distance=calulate(Lattice[i], Lattice[j]);
//统计结果,生成直方图
Histo[Distance]= Histo[Distance]+1;
}
该算法具有以下特点:① 时间复杂度较高,为O(N2);② 以串行方式进行计算,占据较多的CPU资源;③ 内存需求较大,并且长时间不释放。
可以看出,当三维数据点迅速增长时,有限的CPU和内存资源将不能满足计算要求,这将会直接导致算法数据处理时间过长,性能严重降低,必须要对算法进行优化。
2.1 GPU+OpenCL架构
GPU的众核远超CPU的多核,在浮点运算、并行计算等方面可以提供数十倍乃至于上百倍于CPU的性能。GPU通用计算标准[13-16]目前主要有统一计算架构(Compute Unified Device Architecture,CUDA)和开放式计算语言(Open Computing Language,OpenCL)。其中,CUDA只能运行在NVIDIA公司的GPU平台,而OpenCL则支持多种硬件平台。因此,本文的通用计算方法采用OpenCL架构[11],OpenCL架构具有通用性,主要包括平台模型、内存模型、执行模型和编程模型。
OpenCL平台模型描述如图2所示,GPU被视作一个由若干计算单元(Computing Unit,CU)构成的多处理器计算设备(Computing Device,CD),每个CU又由若干处理元素(Processing Element,PE)组成,同一个CU内的PE共享内存,实现同步操作等。主机(Host)则是控制单元,由CPU担任。
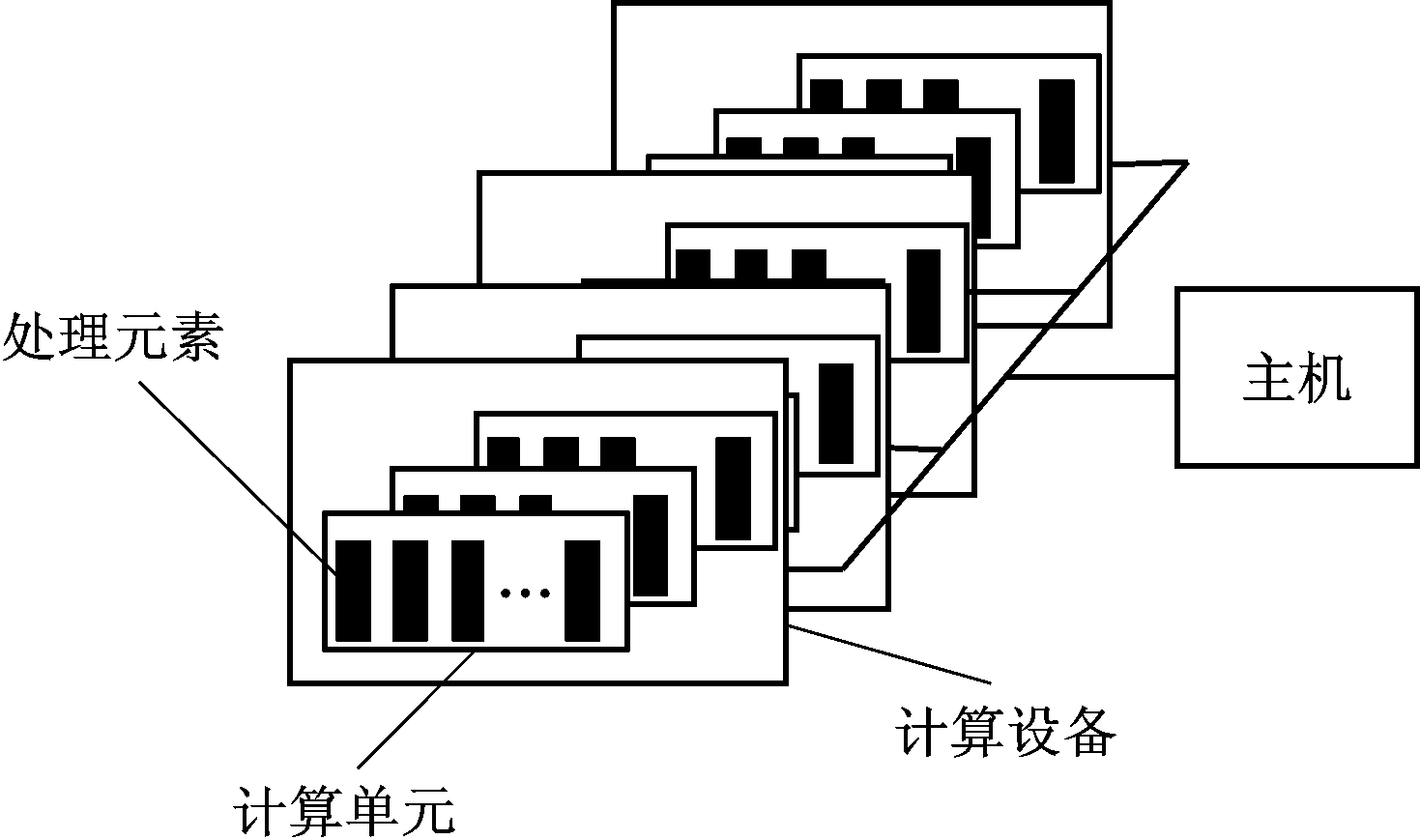
图2 OpenCL平台模型
执行模型和编程模型主要包括2个部分[12]:一部分是主程序,在主机(Host)上运行;另一部分则是Kernel核心程序,在GPU上运行。 Kernel通过Host提交命令,驱动GPU上的PE以单指令多数据(Single Instruction Multiple Data,SIMD)的方式完成计算任务,并返回结果给Host。
OpenCL内存模型描述如图3所示。内存类型有Host内存和设备内存,设备内存又分为全局/常量内存(Global/Constant Memory) 、局部内存(Local Memory)及私有内存(Private Memory)。其中,工作项Work-Item是运行在PE上的Kernel实例,若干工作项被组织在同一个工作组Workgroup内。
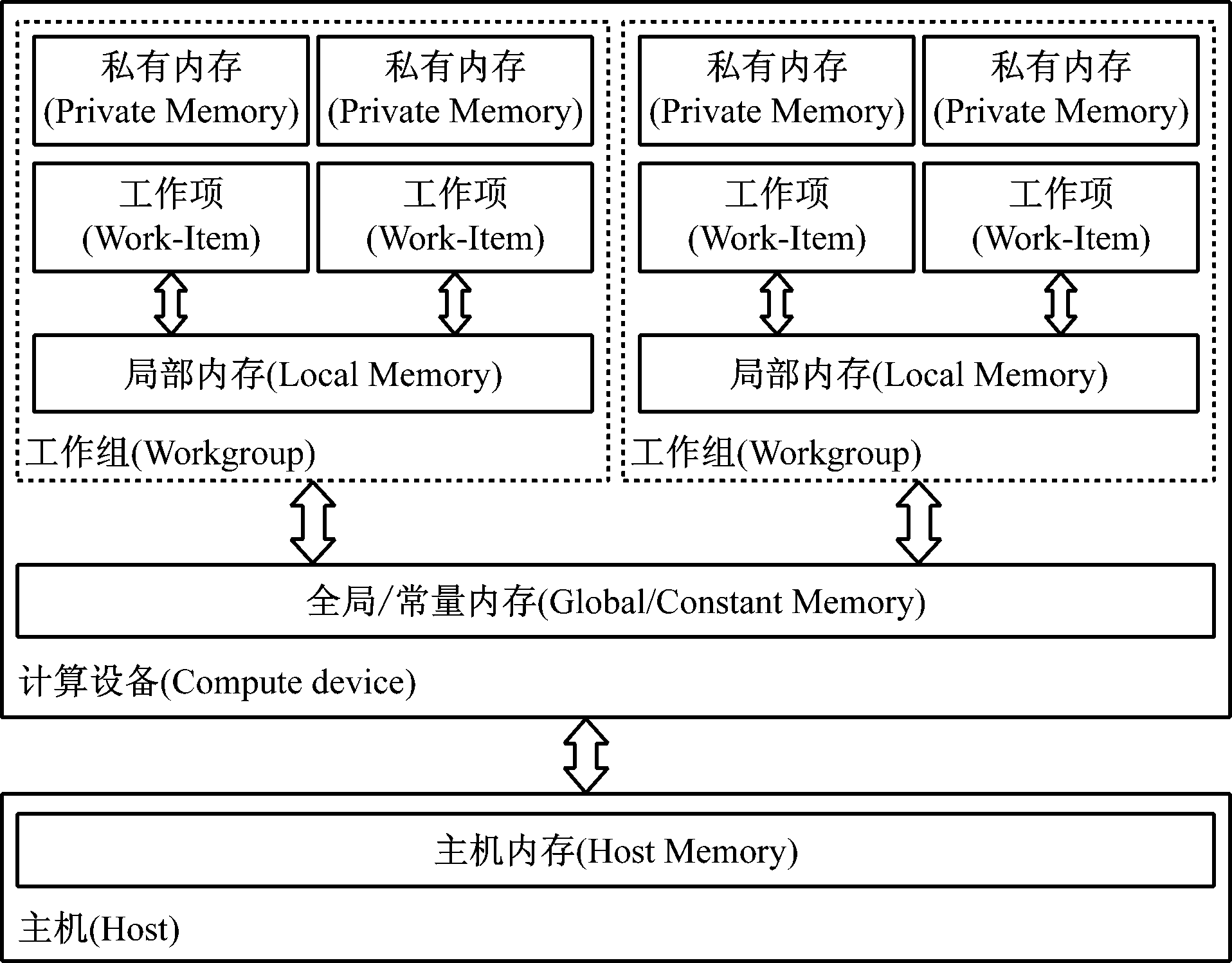
图3 OpenCL内存模型
2.2 算法优化与实现
2.2.1 算法优化
GPU算法优化如图4所示。
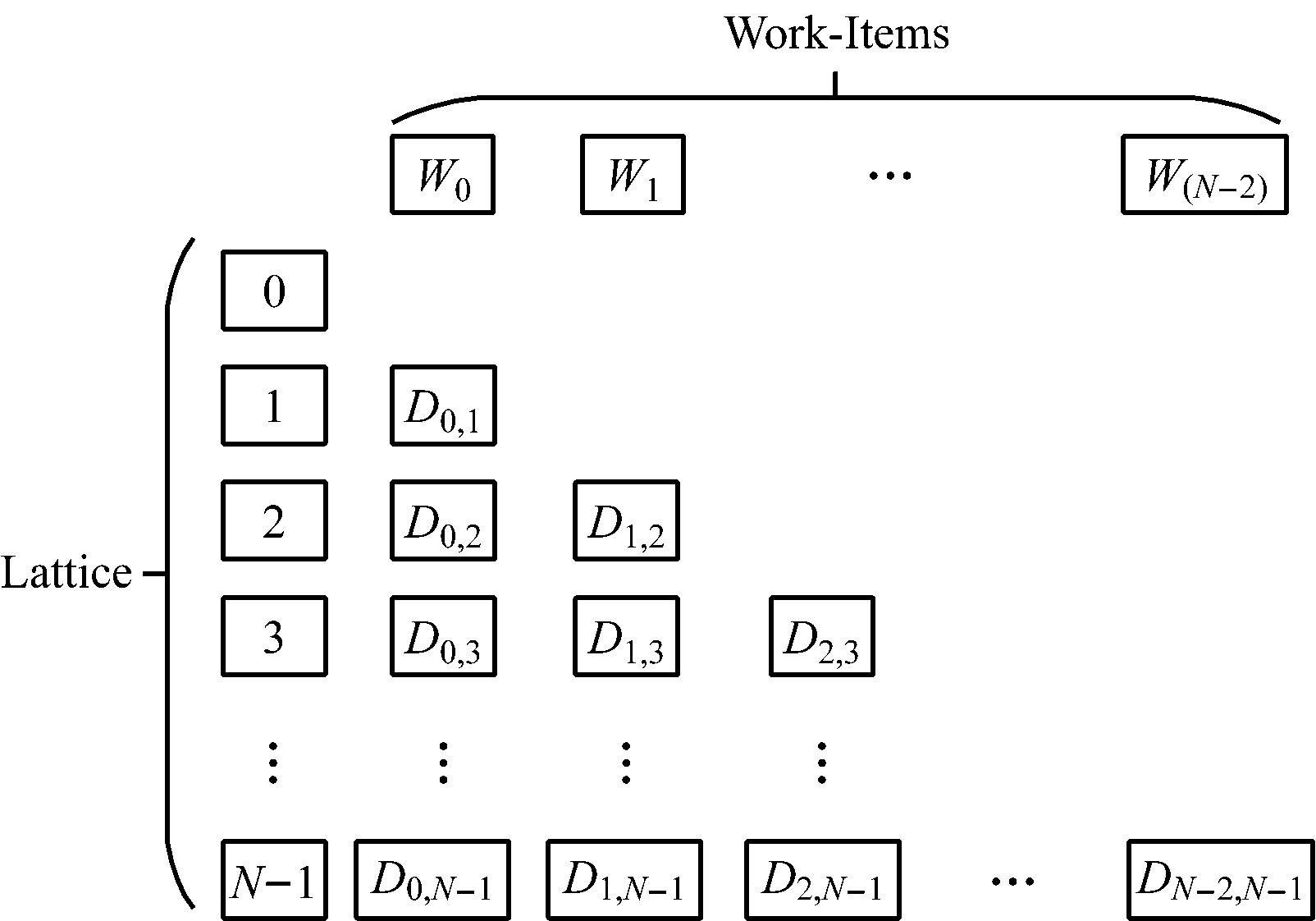
图4 GPU算法优化
采用SIMD方式对三维空间数据距离直方图算法进行优化,将三维点阵数据Lattice[N]从Host Memory复制到Global Memory,GPU同时分配(N-1)个工作项Work-Item(即线程),每个工作项拥有唯一的全局id,并以id为Lattice数组索引,实现所有工作项的SIMD并行计算,得到Lattice[id]与Lattice[j](j=id+1,id+2,…,N-1)的距离值,统计输出直方图。
2.2.2 算法具体实现
算法程序包括Host端CPU主程序和GPU端Kernel核心程序2个部分。
CPU主程序流程如下:
(1) 初始化:数据类型的定义与声明及存储空间的分配,三维点阵的定义为typedef struct {floatx;floaty;floatz;}spatialdata,主机端存储空间分配buf1=(spatialdata *)malloc(BUFSIZE × sizeof(spatialdata))。
(2) 获取GPU平台信息:调用函数clGetPlatformIDs获取当前所拥有的GPU数量及相关信息。
(3) 选择GPU设备:调用函数clGetDeviceIDs,根据ID选定GPU设备。
(4) 管理GPU设备:调用函数clCreateContext创建上下文context,对设备进行管理,调用函数clCreateCommandQueue创建设备可以执行的命令队列。
(5) GPU设备存储空间分配及数据传递:调用函数clCreateBuffer在Global Memory分配存储空间,并调用函数clEnqueueWriteBuffer将数据从Host Memory复制到Global Memory。
(6) Work-Item工作参数设定:编译程序对象,设置Kernel参数和Worksize大小为N。
(7) 并行执行:调用函数clEnqueueND- RangeKernel执行Kernel函数,该函数将会被GPU分配到的所有Work-Items分别执行1次。
(8) 返回结果:调用函数clEnqueueMapBuffer将计算结果返回。
(9) 释放GPU资源:调用clReleaseMemObject回收内存空间。
Kernel核心程序如下:
Kernel程序使用Kernel关键字,函数必须返回void。函数定义为__kernel void HistoResult(__global const spatialdata* Lattice, __global long* Histo, intN),其中Lattice指向数组,Histo指向直方图输出。其程序实现描述如下:
int id = get_global_id(0);
inti=id+1;
while(i<N-1)
{
distance=calculate(Lattice[id],Lattice[i]);
Histo[rs]++;
i++;
}
其中,get_global_id(0)返回正在执行的线程id,同时以id作为当前数据点的索引,i为其他数据点索引,执行循环运算并输出Histo直方图数组。
3.1 FPGA硬件设计
FPGA是一种以硬件描述语言(HDL)来设计实现系统的可重构逻辑器件,它包含了大量专用的定点计算模块、逻辑资源、存储资源、外部存储器接口等,可以完成复杂的浮点运算。同时,大量的片上资源提供了更加高效的并行访问内存能力和高片内访问带宽,丰富的连线资源保证了算法到结构的高效映射,能够根据需求定制计算、存储结构,达到硬件结构与算法的最优匹配[17-18]。
FPGA硬件设计如图5所示。使用FPGA片上资源设计了基于触发式(flip-flop)的数据存储寄存器(Content Storage Register,CSR)来存放三维数据点,能够从CSR中直接读取数据并送至数据处理单元[19-20],节约了内存寻址时间,提高了内存访问速度,可实现对数据点的并行读取、数值计算、结果统计及直方图生成。

图5 FPGA硬件设计
3.2 算法优化与实现
3.2.1 算法优化
设数据点为Li,同时设定CSR寄存器可最多存储T个三维数据点(N>T)。
(1) 常规设计:CSR寄存器每次从数据集取T个数据点![]() ,交由数据处理单元完成任意两点间的距离运算,共完成
,交由数据处理单元完成任意两点间的距离运算,共完成![]() 次计算,并根据计算结果输出直方图数据。然而,由于数据点多次载入,会有重复计算情况发生,导致耗时增加。
次计算,并根据计算结果输出直方图数据。然而,由于数据点多次载入,会有重复计算情况发生,导致耗时增加。
(2) 分块优化设计:将数据集进行有序分块,分块大小S=T/2,可分为N/S块。CSR寄存器划分为相同大小的R1和R2模块,按照数据集分块顺序每次可载入2个数据块,分别存储在R1和R2模块中,如图6所示。数据处理单元负责处理R1模块内数据点距离运算及R1与R2模块间数据点距离运算,且块内和块间运算并行执行,分析统计结果,输出直方图。这样有效避免了重复运算,耗时少。
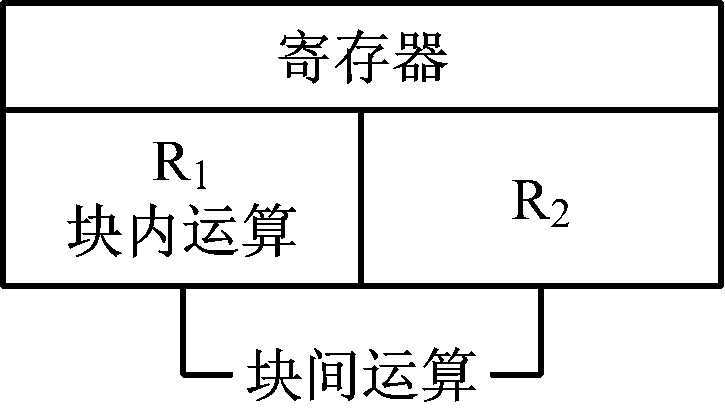
图6 分块优化
分块优化示例如图7所示。
分块优化后三维空间数据距离直方图算法执行示例如下:
(1) 假设N=12,T=8,则S=4。数据集可分为3个数据块,分别为B1、B2和B3。
(2) CSR寄存器将B1载入至R1,B2载入至R2, R1块内运算及R1与R2块间运算并行执行。R1块内运算:执行![]() 次计算得到块内任意两点的距离,即(L1,L2),(L1,L3),(L1,L4),(L2,L3),(L2,L4),(L3,L4),统计结果生成直方图数据;R1与R2块间运算:执行S2次运算,得到B1与B2块间数据点的距离,即(L1,L5),(L1,L6),…,(L1,L8),(L2,L5),(L2,L6),…,(L2,L8),…,(L4,L5),(L4,L6),…,(L4,L8),统计结果生成直方图数据。
次计算得到块内任意两点的距离,即(L1,L2),(L1,L3),(L1,L4),(L2,L3),(L2,L4),(L3,L4),统计结果生成直方图数据;R1与R2块间运算:执行S2次运算,得到B1与B2块间数据点的距离,即(L1,L5),(L1,L6),…,(L1,L8),(L2,L5),(L2,L6),…,(L2,L8),…,(L4,L5),(L4,L6),…,(L4,L8),统计结果生成直方图数据。
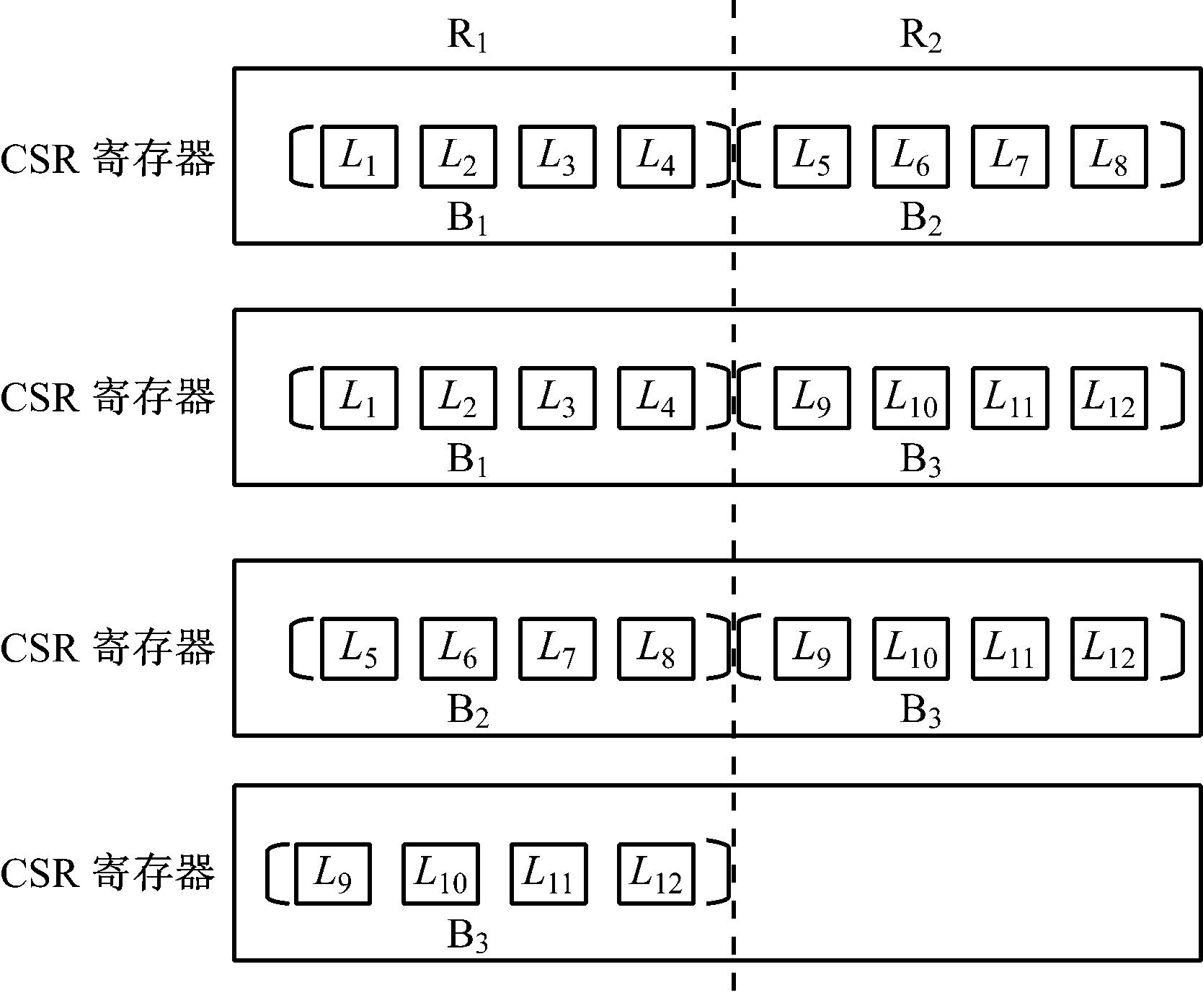
图7 分块优化示例
(3) R1数据不变,R2载入B3,完成R1与R2块间运算。R1与R2块间运算,执行S2次计算得到B1与B3块间数据点的距离,统计结果生成直方图数据。
(4) R1载入B2,R2数据不变,并行完成R1块内运算及R1与R2块间运算,统计结果生成直方图数据。
(5) R1载入B3,完成R1块内运算。R1块内运算,执行![]() 次计算得到B3数据块内任意两点的距离,统计结果生成直方图数据。
次计算得到B3数据块内任意两点的距离,统计结果生成直方图数据。
(6) 数据处理全部结束,汇总直方图数据并输出。
3.2.2 算法具体实现
模块划分如图8所示,算法具体实现主要包括2个模块:块内运算(intra)和块间运算(inter),每个模块内又包含3个功能:空间距离运算、距离值判断及直方图统计。
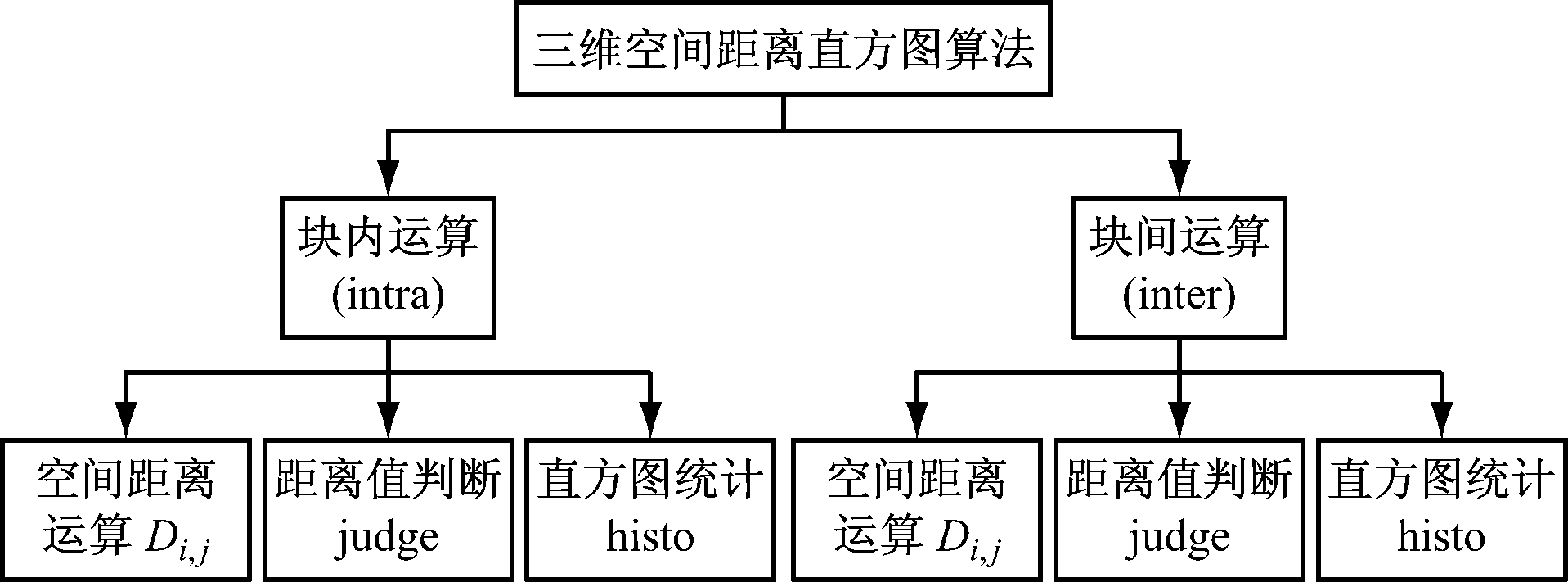
图8 模块划分
空间距离运算:① 定义模块module sqrtinput(clk,rst,start,x1,y1,z1,x2,y2,z2,sqrtinput),得到(Xi-Xj)2+(Yi-Yj)2+(Zi-Zj)2,其中clk为时钟信息,rst为复位信号,start为开始信号,x1、y1、z1及x2、y2、z2为数据点输入信息,sqrtinput为输出结果。② 调用LogiCORE IP CORDIC v4.0,以sqrtinput为输入,计算Di,j。
距离值判断及直方图统计:定义module judge(clk,rst,datain,histo0_10, histo10_20, histo20_30, histo30_40, histo40_50 ),判断datain值范围,输出直方图至histo10_20、 histo20_30,、histo30_40及histo40_50等数组。
实验数据集大小为500~3 000,基于不同大小数据集,完成CPU、GPU及FPGA计算方法的耗时对比实验。基于CPU及GPU计算方法的实验采用AMD APU A8 PRO-7600B R7(10 Compute Cores 4C+6G 四核,主频3.1 GHZ)。 基于FPGA计算方法的实验则采用Xilinx XUPV5-LX110T,主要参数:可编辑逻辑单元CLB为8 640个, 频率为100 MHz,设计了40个CSR寄存器(即T=40)。
基于CPU、GPU及FPGA的计算方法耗时及加速比对比结果见表2及图9。GPU/CPU的加速比为G/C,FPGA/CPU的加速比为F/C,FPGA/GPU的加速比为F/G。随着数据集的增大,CPU方法耗时明显增加,而GPU、FPGA方法耗时则没有显著增加,G/C达到了2~35倍的加速比,F/C达到了20~40倍的加速比。当数据集较小时,F/G达到了18倍的加速比,耗时更少;然而,当数据集逐渐增大至2 500时,FPGA方法耗时显著增加,加速比降低。达到一定数据量时,FPGA方法耗时甚至多于GPU方法,这是由于FPGA硬件资源的限制,可以通过提高芯片性能或者FPGA集群来提升运算速度。
表2 基于CPU、GPU及FPGA的计算方法耗时及加速比对比结果
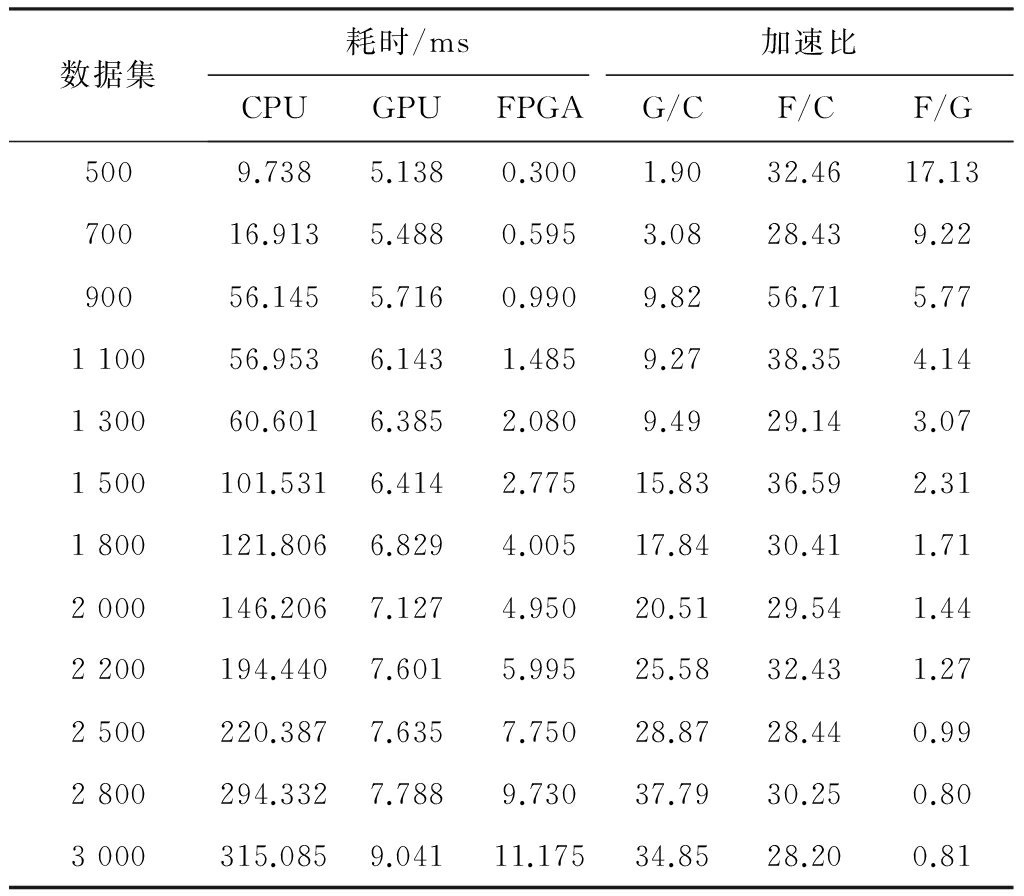
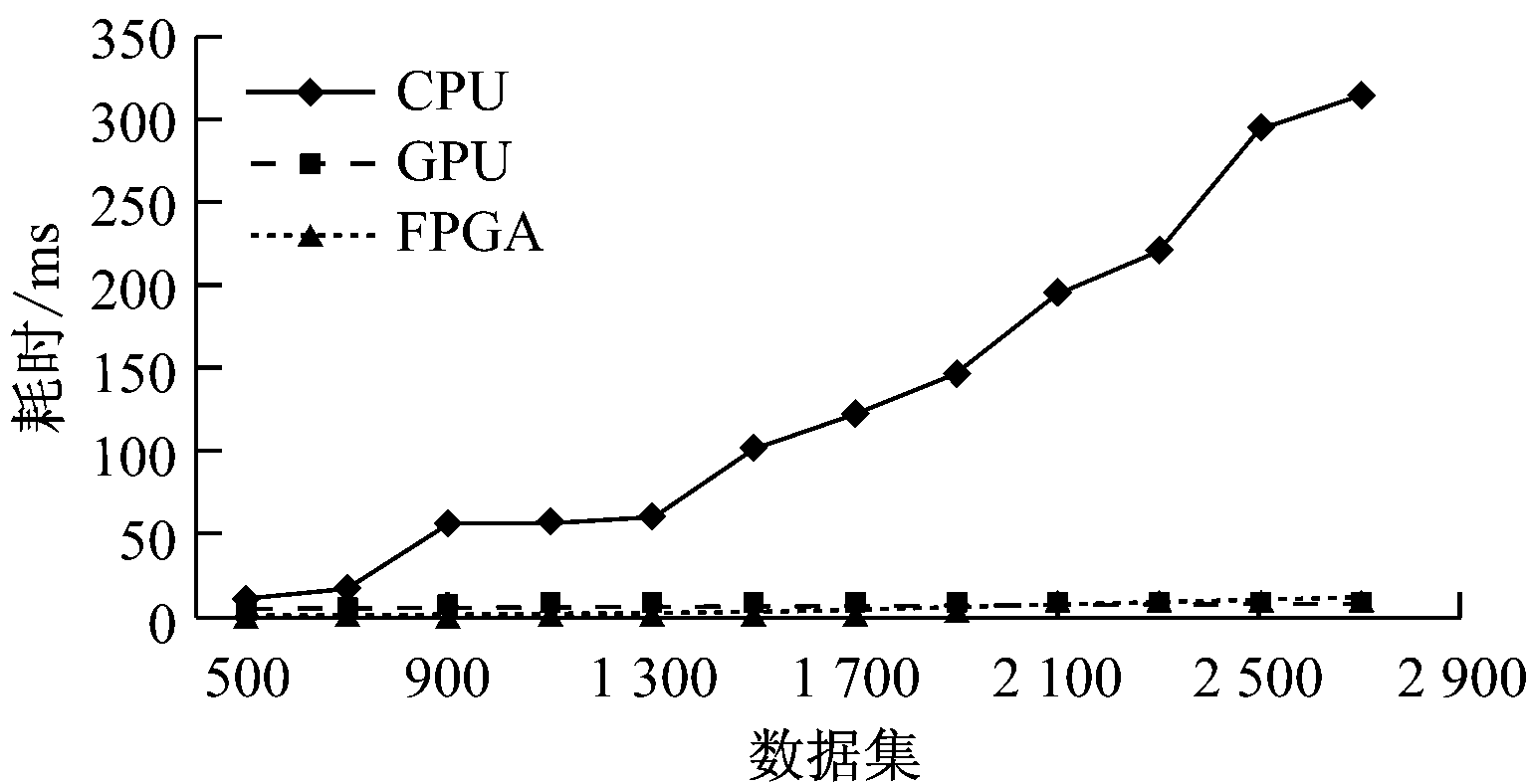
图9 基于CPU、GPU及FPGA的计算方法耗时对比
在“数字矿山”的背景下,矿山三维数据的处理对计算的及时性、准确性和便利性都提出了更高的要求,高性能并行计算可以有效提升三维数据的处理能力。基于GPU和FPGA的高性能计算方法可对三维空间数据距离直方图算法进行优化,实现了算法数十倍的性能加速,极大提升了算法对三维空间数据的处理能力。
参考文献:
[1] 陈玲侠.矿山空间数据处理分析及三维实体建模应用研究[D].西安:长安大学,2013.
[2] 陈金川,毛善君,李小娟,等.虚拟煤矿三维引擎架构设计及实现[J].煤炭科学技术,2012,40(7):76-80.
[3] 马长乐,何小龙,邵艳菊.煤矿井下三维巷道的空间数据及拓扑关系研究[J].煤,2012,21(4):8-10.
[4] 陶雪娇,胡晓峰,刘洋.大数据研究综述[J].系统仿真学报,2013(增刊1):142-146.
[5] 李国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考[J].中国科学院院刊,2012,27(6):647-657.
[6] TU Yicheng, CHEN Shaoping. Computing distance histograms efficiently in scientific databases[C]//IEEE 25th International Conference on Data Engineering, Shanghai,2009.
[7] 曹伟国,胡平,李华,等.基于距离直方图的最优视点选择[J].计算机辅助设计与图形学学报,2010,22(9):1515-1521.
[8] 卢风顺,宋君强,银福康,等.CPU/GPU协同并行计算研究综述[J].计算机科学,2011,38(3):5-9.
[9] 邬贵明.FPGA矩阵计算并行算法与结构[D].长沙:国防科学技术大学,2011.
[10] 维基百科.N-body Probelm[EB/OL].(2013-09-07)[2016-08-24].https://en.wikipedia.org/wiki/N-body_problem.
[11] NGUYEN H.GPU Gems 3[M].Boston: Pearson Education, 2007.
[12] 章冲.网络环境下煤矿三维建模及可视化关键技术研究[D].郑州:解放军信息工程大学,2010.
[13] 白洪涛.基于GPU的高性能并行算法研究[D].长春:吉林大学,2010.
[14] 姚平.CUDA平台上的CPU/GPU异步计算模式[D].合肥:中国科学技术大学,2010.
[15] 马俊峰.基于OpenCL的多GPU并行计算的研究与应用[D].哈尔滨:哈尔滨理工大学,2014.
[16] 张锦涛,赵惊涛,王真理.FPGA与GPU并行计算分析——以Kirchhoff叠前时间偏移为例[J].地球物理学进展,2013,28(3):1464-1471.
[17] 潘明,陈元枝,李强.基于FPGA的图像采集系统的设计[J].国外电子测量技术,2012,31(3):58-61.
[18] 朱俊峰,陈钢,张珂良,等.面向OpenCL架构的GPGPU量化性能模型[J].小型微型计算机系统,2013,34(5):1118-1125.
[19] NIU X, FAN J. System verification of hardware optimization based on edge detection[J]. Journal of Circuits and Systems,2013,4(3):293-298.
[20] NIU X, GALARZA L, GAO Y, et al.Software-hardware co-design for video coding acceleration[C]// 44th IEEE Southeastern Symposium on System Theory, Jacksonville,2012:57-60.
PEI Hao1, YOU Xiaorong1, NIU Xinwei2
(1.Electromechanical Engineering Department, Changzhou Textile and Garment Institute, Changzhou 213164, China;2.School of Engineering, The Behrend College, Penn State Erie, Erie Pennsylvania 16563, USA)
Abstract:The properties and data structure of distance histogram algorithm of three-dimensional space data were analyzed, and a general computing method based on graphics processor and a high performance computing method based on FPGA were proposed. The calculation method based on graphics processor is used to implement single instruction multiple data parallel optimization of distance histogram algorithm of three-dimensional space data; the calculation method based on FPGA can realize hardware block optimization, and achieve the optimal matching of the hardware structure of the algorithm. The experimental results show that using the calculation method based on graphics processor can make the algorithm reach performance acceleration with an average of 18 times, and the computing method based on FPGA can make the algorithm reach performance acceleration with an average of 30 times, which greatly improve data processing ability of the algorithm.
Key words:digital mine; three-dimensional space data; big data; distance histogram algorithm; optimization and acceleration; GPU; FPGA
文章编号:1671-251X(2017)02-0055-06
DOI:10.13272/j.issn.1671-251x.2017.02.012
收稿日期:2016-09-23;
修回日期:2016-10-31;责任编辑:张强。
基金项目:江苏省高校优秀中青年教师和校长境外研修计划项目(201422);常州纺院学术科研基金项目(CFK201510)。
作者简介:裴浩(1984-),男,江苏阜宁人,讲师,硕士,研究方向为大数据计算,E-mail:peihao198419@163.com。
中图分类号:TD672
文献标志码:A
网络出版:时间:2017-01-22 10:35
网络出版地址:http://www.cnki.net/kcms/detail/32.1627.TP.20170122.1035.012.html
裴浩,游小荣,牛欣伟.矿山三维空间数据距离直方图算法优化及加速[J].工矿自动化,2017,43(2):55-60.