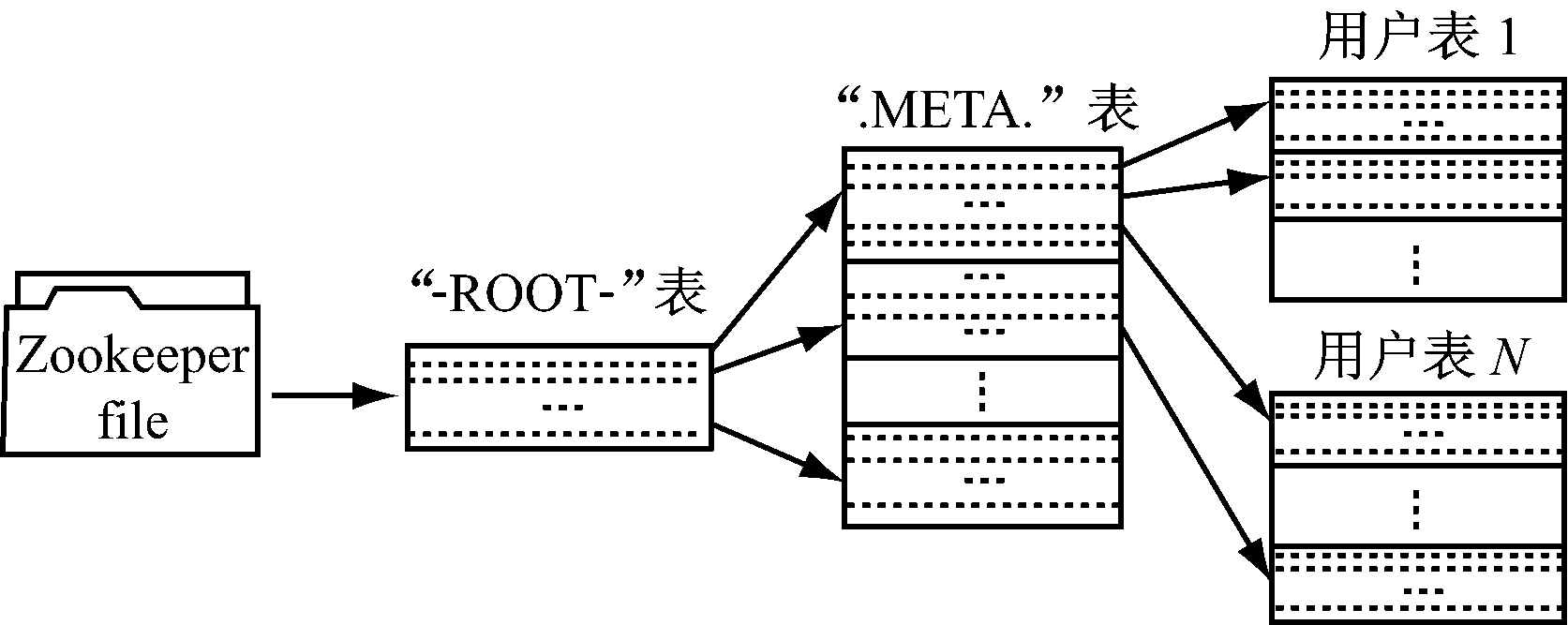
图1 用户表寻址
经验交流
王维1,2
(1.中煤科工集团常州研究院有限公司, 江苏 常州 213015;2.天地(常州)自动化股份有限公司, 江苏 常州 213015)
摘要:针对现有人员定位系统难以满足大型煤矿大数据量访问需求的问题,提出将Hadoop应用于人员定位软件系统中,利用并行计算模型MapReduce和非关系型数据库HBase实现人员定位数据的并行化访问。Hadoop的应用显著提升了人员定位软件系统的数据处理性能、实时性和可扩展性。
关键词:人员定位; Hadoop; 精确定位; 对称双边双向算法; MapReduce; HBase
井下人员定位系统在煤矿生产中为人员安全提供了重要保障,通过人员定位系统可以实时掌握井下人员分布情况、人员考勤信息等[1]。国家强制要求所有煤矿必须安装人员定位系统方可生产。随着煤矿信息化和精确定位技术的发展,人员定位系统对数据吞吐量和可靠性要求越来越高。现有人员定位系统大多采用串行程序和关系数据库,数据处理能力有限。鉴此,本文提出将Hadoop应用于井下人员定位软件系统中,Hadoop的应用提高了系统的数据访问速度和数据可靠性,能满足煤矿人员定位数据访问量不断增长的需求。
Hadoop是一个开源的计算架构,可以在大量计算机组成的集群上运行应用程序,对大规模数据的分布存储和并行计算处理能力显著[2]。其核心包括HDFS分布式文件系统、MapReduce分布式计算模型[3]及HBase分布式数据库。
HDFS把数据集分发到Hadoop集群上的不同的Datanode上,每个Datanode会定期返回自己完成的工作状态报告,由此保证数据的可靠性[4]。
HBase是一个构建在HDFS上的分布式数据库[5]。不同于传统数据库按行存储的模式,HBase采用基于列的存储模式,每个字段的数据聚集存储,可以大幅减少查询需要读取的数据量,并且列为空就不占用存储空间。在HBase中,一张表会被划分成多个块,每个块就是一个Region。每个Region都有自己的一个Rowkey的范围, 该范围的边界值是StartKey和EndKey,落在特定范围内的Region将交由指定的HRegionServer处理, 一个HRegionServer即为一个节点。通过上述方式实现分布式运算和多个节点的并发处理。
安装HBase时会自带Zookeeper,它主要负责HRegionServer实时监控和HMasterServer的选举,保证HBase当中只有一个Master,并且当Master不工作时,迅速推选一个新的HRegionServer作为Master。客户端访问数据时,首先要通过Zookeeper获得“-ROOT-”表的位置,然后通过“-ROOT-”表获得“.META.”的Region分布信息,最后访问“.META.”得到用户表的Region分布信息,然后访问用户表,如图1所示。其中“-ROOT-”和“.META.”表都存储于HBase中,“-ROOT-”表存储于一个Region中,而“.META.”表存储于多个Region中。
图1 用户表寻址
2.1 基于Hadoop的井下人员定位系统架构
基于Hadoop的井下人员定位系统主要由发射器、接收器、分站、传输接口(RS485/TCP通信)、服务器、客户端组成,如图2所示。其中客户端和服务器都是若干个,根据煤矿需求确定。多个服务器组成了Hadoop服务器集群。
射频发射器进入接收器的覆盖范围后开始唤醒,并发送定位数据包,与射频接收器交互2次定位数据包后,射频发射器对定位数据包进行处理,通过空中传输时间计算出与接收器的距离,并把距离数据、控制信息等组成数据帧通过无线信道发送给接收器。接收器收到信号后传输给分站,分站对数据进行必要处理后将这些信息通过传输接口传到上位机,应用程序对数据进行解析后,由Hadoop服务器集群完成数据的分发和存储。
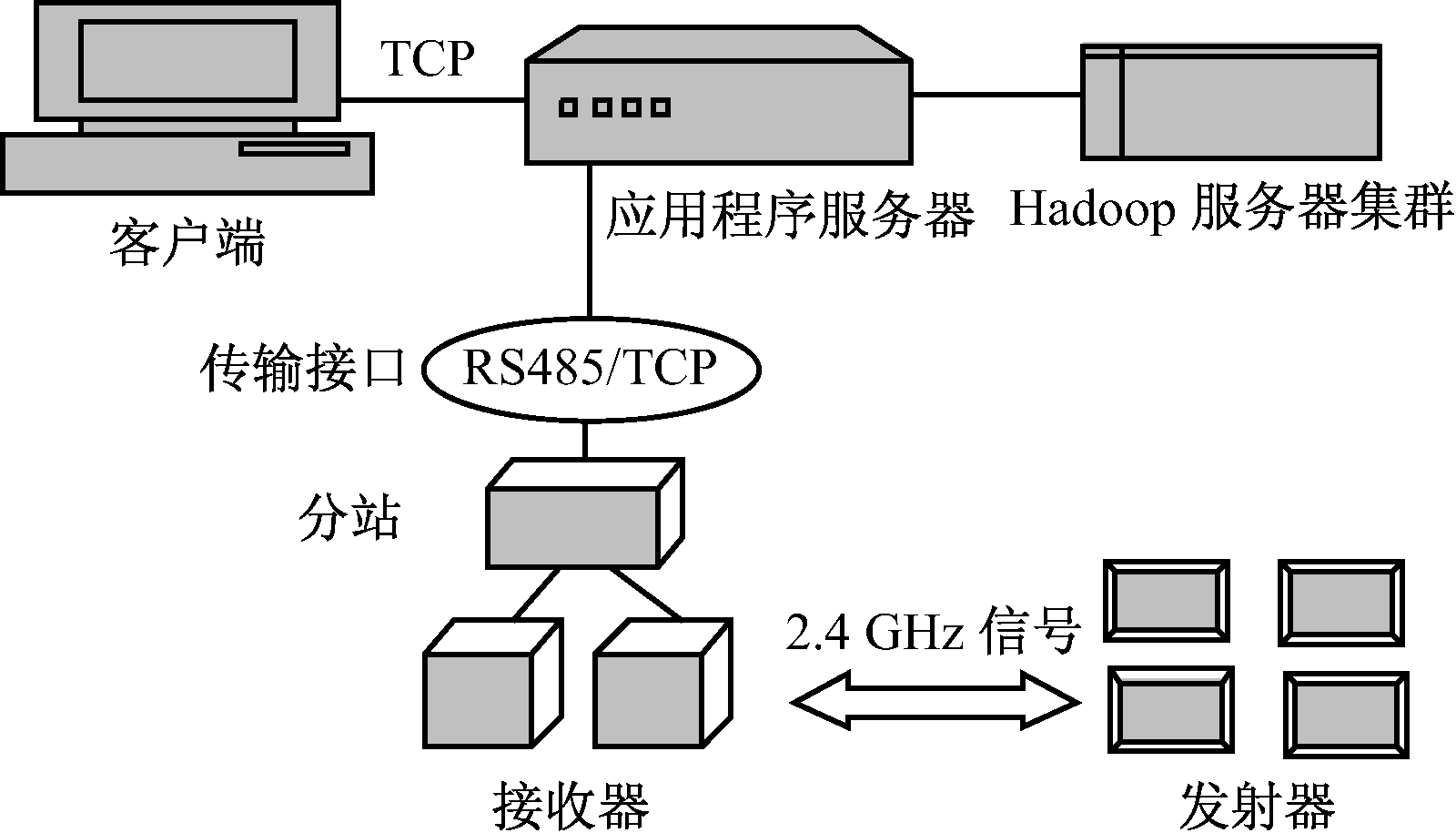
图2 基于Hadoop的井下人员定位系统架构
系统采用对称双边双向测距算法(Symmetrical Double-Sided Two Way Ranging,SDS-TWR)[6]将误差缩小到2 m以内。SDS-TWR基于TOA的思想,是双向测距方法的改进方法。SDS-TWR因为不需要同步时钟,避免了节点因时钟不一致而引起系统误差[7],从而提高了定位精度。
对于精确定位来说,每个人的实时数据(包含时间、距离、方向等)都会频繁写入数据库,而这些数据必须是高速率读写,才能保证客户端查询的精确性。Hadoop框架可满足对数据库高速率访问需求,与精确定位技术相结合可极大地提高井下人员定位数据的实时性和可靠性。
2.2 Hadoop服务器集群
Hadoop服务器集群由一个Master和若干个Slave组成[8],如图3所示,图中虚线部分就是Hadoop集群的常见结构,其中Master可以兼作Slave,这样能提高硬件的利用效率。当Master运行时,Master首先启动IPC Server,用于接收Slave的心跳信息。当Slave运行时,会主动连接到Master,并且定期向Master发送一个心跳,通过心跳将Slave的状态信息传递给Master,最后Master借助心跳的返回值,向从节点Slave传达相应指令。
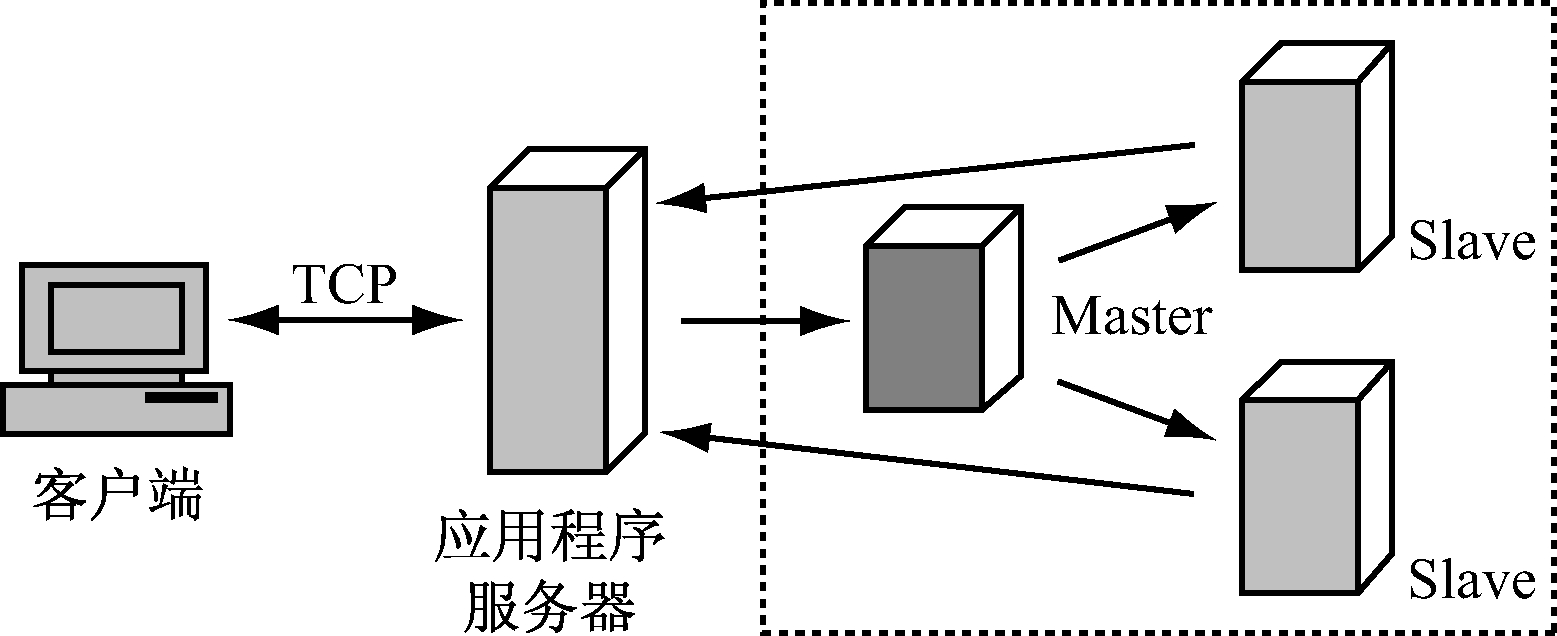
图3 Hadoop集群
对于分布式存储系统HDFS来说,集群中的节点由一个Namenode和多个Datanode组成。Namenode是HDFS的中枢,主要负责Namespace管理和访问分配,确定数据块对应的Datanode映射。Datanode通常是一个节点分配一个,主要负责该节点上的存储,处理客户端的读写请求。一个文件被划分成N个块(N≥1),这些块分布在不同Datanode上。实际的I/O操作不经过Namenode,Namenode只是将操作映射到对应的Datanode。
在Hadoop集群中,Namenode、Jobtracker运行在Master上;Datanode、Tasktracker则运行在Slave上。
对于MapReduce来说,Hadoop将Job划分成若干个Task进行处理。主节点的Jobtracker协调整个Job的运行,将Task分配到不同的Tasktracker上;从节点的Tasktracker负责运行Task,并将运行结果返回给Jobtracker[9]。
2.3 数据采集模型
系统数据通信[10]采用主从方式,一问一答,即上位机向分站发送命令,分站接到命令后,返回对应的数据包。如果是RS485通信,则串行收发命令,同一通道内的分站依次巡检;如果是TCP/IP通信,则是并行发送和接收。对于精确定位来说,数据量较大,因此本文使用TCP/IP通信。
系统数据采集模型如图4所示。应用程序分为两大块:井下通信模块和地面操作模块。井下通信模块即图中的“通信子系统”,该子系统直接负责与井下分站通信,并把接收到的数据通过Thrift API接口写入HBase数据库。地面操作模块包含数据管理子系统、考勤管理子系统、定位跟踪子系统、安全报警子系统和救灾辅助子系统。这些子系统可以通过TCP/IP传送命令给通信子系统,例如发送救灾指示牌命令等,由通信子系统把命令发送到井下设备,相应设备(例如指示牌、报警器等)则会发出相应的声光提示。当应用程序发起人员定位数据访问请求时,主节点接收到该请求后,Jobtracker将开发好的Map函数分发到各个节点。在所有节点上运行Map函数后产生一个中间的key-value对集合,然后把key值相同的value集合在一起,传递给Reduce函数,合并后得到最终结果,并将结果存放到HDFS文件中,同时将定位信息并反馈给应用程序。
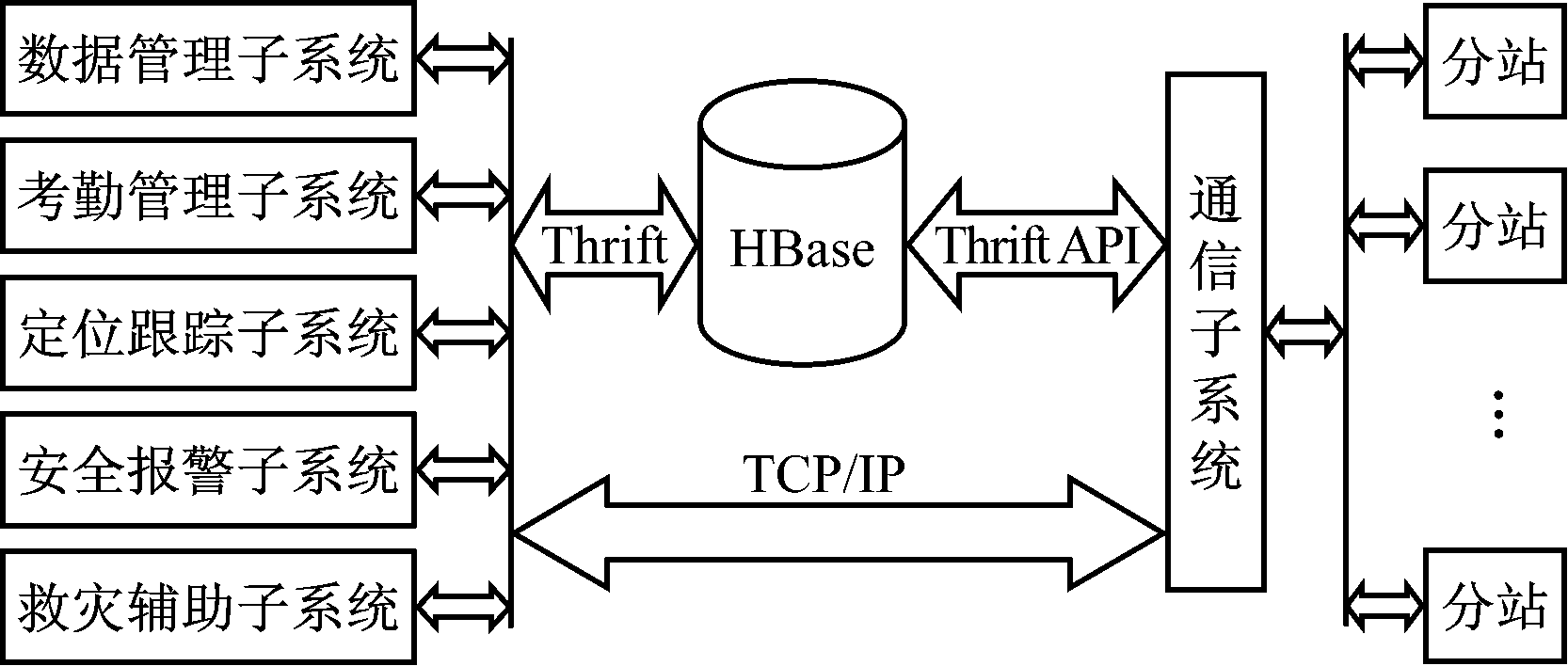
图4 人员定位软件系统数据采集模型
在煤矿井下人员定位软件系统中采用Hadoop集群方案,通过MapReduce和HBase实现了数据的并行访问,提高了系统运行速度。通过采用SDS-TWR算法有效避免了时钟引起的系统误差,提高了人员定位数据的精度。Hadoop的应用使得该系统高效实用、数据可靠,并且具有良好的可扩展性。通过该系统可以实时、精确地掌握井下人员信息,为煤矿安全生产调度指挥提供重要决策依据。
参考文献:
[1] 包建军,霍振龙,徐炜,等.一种高精度井下人员无线定位方法[J].工矿自动化,2009,35(10):18-21.
[2] 刘师语,周渊平,杜江.基于HADOOP分布式系统的数据处理分析[J].通信技术,2013,46(9):99-102.
[3] DEAN J,GHEMAWAT S. MapReduce:simplified data processing on large clusters[J]. Communications of the ACM,2008, 51(1):107-111.
[4] 郝树魁.Hadoop HDFS和MapReduce架构浅析[J].邮电设计技术,2012(7):37-42.
[5] 李玲,任青,付园,等.基于Hadoop的社交网络服务推荐算法[J].吉林大学学报(信息科学版),2013,31(4):359-364.
[6] 杨清玉,于宁,王霄,等.无线传感器网络线性调频扩频测距方法研究[J].传感技术学报,2010,23(12):1761-1765.
[7] 张科帆,朱海霞,包建军.基于CSS技术的井下精确定位系统设计[J].工矿自动化,2014,40(1):5-8.
[8] SHVACHKO K, KUANG H, RADIA S, et al. The Hadoop distributed file system[C]//IEEE 26th Symposium on Mass Storage Systems and Technologies, Incline Village, Nevada, USA: IEEE Press,2010:1-10.
[9] 董西成.Hadoop技术内幕:深入解析MapReduce架构设计与实现原理[M].北京:机械工业出版社,2013.
[10] 霍振龙,包建军.煤矿物联网统一通信平台的研究[J].工矿自动化,2011,37(10):1-3.
WANG Wei1,2
(1.CCTEG Changzhou Research Institute, Changzhou 213015, China;2.Tiandi(Changzhou) Automation Co., Ltd., Changzhou 213015, China)
Abstract:In order to solve the problem that existing personnel locating system can not meet large data access requirement of large-scale coal mines, Hadoop was proposed to be used in personnel positioning software system, and parallel computing model MapReduce and non-relational database HBase were used to realize parallel access of personnel positioning data. The application of Hadoop can significantly improve data processing performance, real-time performance and scalability of personnel positioning software system.
Key words:personnel positioning; Hadoop;precise positioning; SDS-TWR; MapReduce; HBase
文章编号:1671-251X(2017)01-0066-03
DOI:10.13272/j.issn.1671-251x.2017.01.016
收稿日期:2016-09-08;
修回日期:2016-12-05;责任编辑:胡娴。
基金项目:国家科技支撑计划项目(2013BAK06B05);中国煤炭科工集团有限公司面上项目(2016MS019)。
作者简介:王维(1984-),男,江苏宿迁人,工程师,现主要从事矿用软件的开发与应用工作,E-mail:tiandichangzhou@126.com。
中图分类号:TD655
文献标志码:A
网络出版:时间:2016-12-30 10:32
网络出版地址:http://www.cnki.net/kcms/detail/32.1627.TP.20161230.1032.016.html
王维.Hadoop在人员定位软件系统中的应用研究[J].工矿自动化,2017,43(1):66-68.